 Posted by Ming Guang Yong, Product Manager for MediaPipe
Posted by Ming Guang Yong, Product Manager for MediaPipeMediaPipe in 2019
MediaPipe is a framework for building cross platform multimodal applied ML pipelines that consist of fast ML inference, classic computer vision, and media processing (e.g. video decoding). MediaPipe was open sourced at CVPR in June 2019 as v0.5.0. Since our first open source version, we have released various ML pipeline examples like
In this blog, we will introduce another MediaPipe example: Object Detection and Tracking. We first describe our newly released box tracking solution, then we explain how it can be connected with Object Detection to provide an Object Detection and Tracking system.
Box Tracking in MediaPipe
In MediaPipe v0.6.7.1, we are excited to release a box tracking solution, that has been powering real-time tracking in Motion Stills, YouTube’s privacy blur, and Google Lens for several years and that is leveraging classic computer vision approaches. Pairing tracking with ML inference results in valuable and efficient pipelines. In this blog, we pair box tracking with object detection to create an object detection and tracking pipeline. With tracking, this pipeline offers several advantages over running detection per frame:
- It provides instance based tracking, i.e. the object ID is maintained across frames.
- Detection does not have to run every frame. This enables running heavier detection models that are more accurate while keeping the pipeline lightweight and real-time on mobile devices.
- Object localization is temporally consistent with the help of tracking, meaning less jitter is observable across frames.
Our general box tracking solution consumes image frames from a video or camera stream, and starting box positions with timestamps, indicating 2D regions of interest to track, and computes the tracked box positions for each frame. In this specific use case, the starting box positions come from object detection, but the starting position can also be provided manually by the user or another system. Our solution consists of three main components: a motion analysis component, a flow packager component, and a box tracking component. Each component is encapsulated as a MediaPipe calculator, and the box tracking solution as a whole is represented as a MediaPipe subgraph shown below.
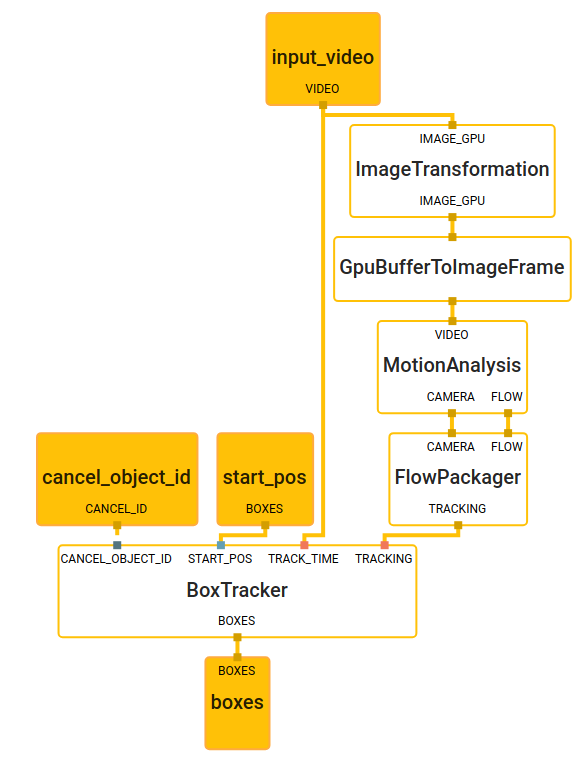
MediaPipe Box Tracking Subgraph
The MotionAnalysis calculator extracts features (e.g. high-gradient corners) across the image, tracks those features over time, classifies them into foreground and background features, and estimates both local motion vectors and the global motion model. The FlowPackager calculator packs the estimated motion metadata into an efficient format. The BoxTracker calculator takes this motion metadata from the FlowPackager calculator and the position of starting boxes, and tracks the boxes over time. Using solely the motion data (without the need for the RGB frames) produced by the MotionAnalysis calculator, the BoxTracker calculator tracks individual objects or regions while discriminating from others. To track an input region, we first use the motion data corresponding to this region and employ iteratively reweighted least squares (IRLS) fitting a parametric model to the region’s weighted motion vectors. Each region has a tracking state including its prior, mean velocity, set of inlier and outlier feature IDs, and the region centroid. See the figure below for a visualization of the tracking state, with green arrows indicating motion vectors of inliers, and red arrows indicating motion vectors of outliers. Note that by only relying on feature IDs we implicitly capture the region’s appearance, since each feature’s patch intensity stays roughly constant over time. Additionally, by decomposing a region’s motion into that of the camera motion and the individual object motion, we can even track featureless regions.

Visualization of Tracking State for Each Box
An advantage of our architecture is that by separating motion analysis into a dedicated MediaPipe calculator and tracking features over the whole image, we enable great flexibility and constant computation independent of the number of regions tracked! By not having to rely on the RGB frames during tracking, our tracking solution provides the flexibility to cache the metadata across a batch of frame. Caching enables tracking of regions both backwards and forwards in time; or even sync directly to a specified timestamp for tracking with random access.
Object Detection and Tracking
A MediaPipe example graph for object detection and tracking is shown below. It consists of 4 compute nodes: a PacketResampler calculator, an ObjectDetection subgraph released previously in the MediaPipe object detection example, an ObjectTracking subgraph that wraps around the BoxTracking subgraph discussed above, and a Renderer subgraph that draws the visualization.
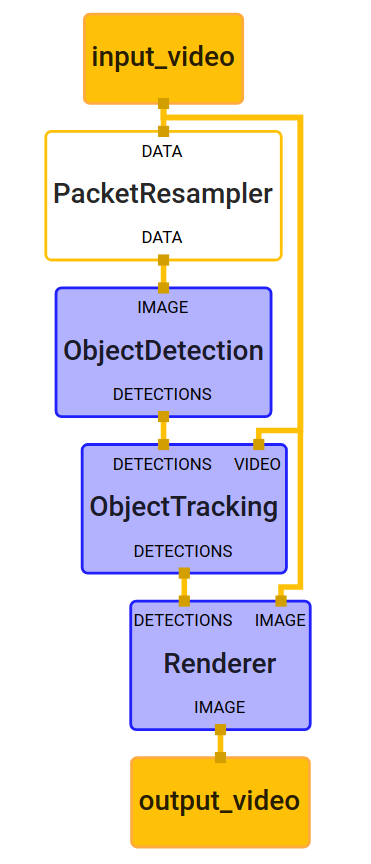
MediaPipe Example Graph for Object Detection and Tracking. Boxes in purple are subgraphs.
In general, the ObjectDetection subgraph (which performs ML model inference internally) runs only upon request, e.g. at an arbitrary frame rate or triggered by specific signals. More specifically, in this example PacketResampler temporally subsamples the incoming video frames to 0.5 fps before they are passed into ObjectDetection. This frame rate can be configured differently as an option in PacketResampler.
The ObjectTracking subgraph runs in real-time on every incoming frame to track the detected objects. It expands the BoxTracking subgraph described above with additional functionality: when new detections arrive it uses IoU (Intersection over Union) to associate the current tracked objects/boxes with new detections to remove obsolete or duplicated boxes.
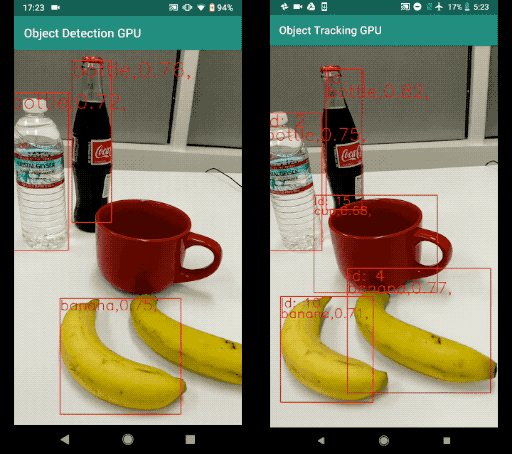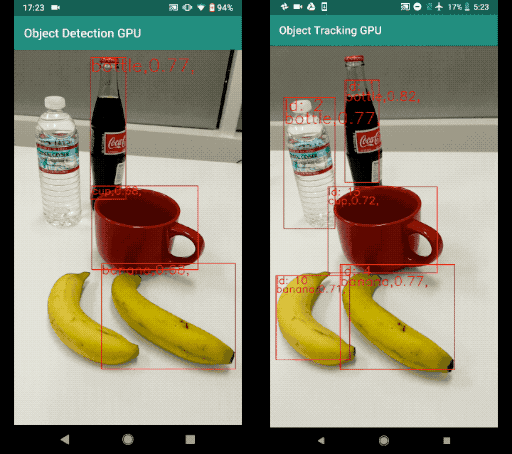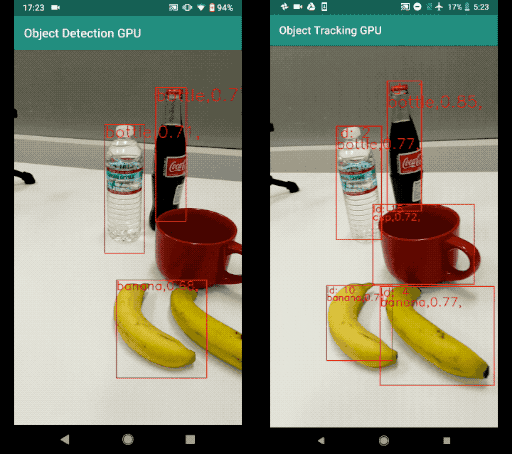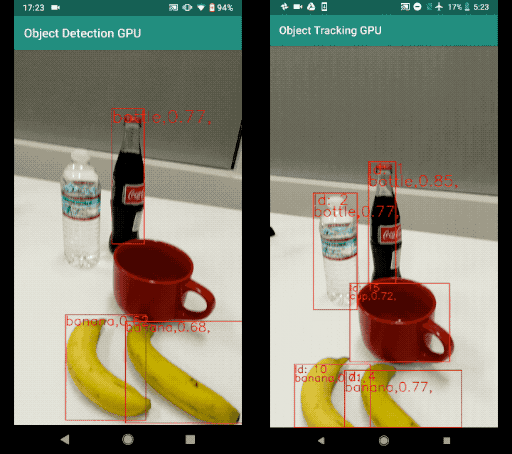
A sample result of this object detection and tracking example can be found below. The left image is the result of running object detection per frame. The right image is the result of running object detection and tracking. Note that the result with tracking is much more stable with less temporal jitter. It also maintains object IDs across frames.
Comparison Between Object Detection Per Frame and Object Detection and Tracking
Follow MediaPipe
This is our first Google Developer blog post for MediaPipe. We look forward to publishing new blog posts related to new MediaPipe ML pipeline examples and features. Please follow the MediaPipe tag on the Google Developer blog and Google Developer twitter account (@googledevs)
Acknowledgements
We would like to thank Fan Zhang, Genzhi Ye, Jiuqiang Tang, Jianing Wei, Chuo-Ling Chang, Ming Guang Yong, and Matthias Grundman for building the object detection and tracking solution in MediaPipe and contributing to this blog post.