Since it was introduced a few years ago, Google’s Transformer architecture has been applied to challenges ranging from generating fantasy fiction to writing musical harmonies. Importantly, the Transformer’s high performance has demonstrated that feed forward neural networks can be as effective as recurrent neural networks when applied to sequence tasks, such as language modeling and translation. While the Transformer and other feed forward models used for sequence problems are rising in popularity, their architectures are almost exclusively manually designed, in contrast to the computer vision domain where AutoML approaches have found state-of-the-art models that outperform those that are designed by hand. Naturally, we wondered if the application of AutoML in the sequence domain could be equally successful.
After conducting an evolution-based neural architecture search (NAS), using translation as a proxy for sequence tasks in general, we found the Evolved Transformer, a new Transformer architecture that demonstrates promising improvements on a variety of natural language processing (NLP) tasks. Not only does the Evolved Transformer achieve state-of-the-art translation results, but it also demonstrates improved performance on language modeling when compared to the original Transformer. We are releasing this new model as part of Tensor2Tensor, where it can be used for any sequence problem.
Developing the Techniques
To begin the evolutionary NAS, it was necessary for us to develop new techniques, due to the fact that the task used to evaluate the “fitness” of each architecture, WMT’14 English-German translation, is computationally expensive. This makes the searches more expensive than similar searches executed in the vision domain, which can leverage smaller datasets, like CIFAR-10. The first of these techniques is warm starting—seeding the initial evolution population with the Transformer architecture instead of random models. This helps ground the search in an area of the search space we know is strong, thereby allowing it to find better models faster.
The second technique is a new method we developed called Progressive Dynamic Hurdles (PDH), an algorithm that augments the evolutionary search to allocate more resources to the strongest candidates, in contrast to previous works, where each candidate model of the NAS is allocated the same amount of resources when it is being evaluated. PDH allows us to terminate the evaluation of a model early if it is flagrantly bad, allowing promising architectures to be awarded more resources.
The Evolved Transformer
Using these methods, we conducted a large-scale NAS on our translation task and discovered the Evolved Transformer (ET). Like most sequence to sequence (seq2seq) neural network architectures, it has an encoder that encodes the input sequence into embeddings and a decoder that uses those embeddings to construct an output sequence; in the case of translation, the input sequence is the sentence to be translated and the output sequence is the translation.
The most interesting feature of the Evolved Transformer is the convolutional layers at the bottom of both its encoder and decoder modules that were added in a similar branching pattern in both places (i.e. the inputs run through two separate convolutional layers before being added together).
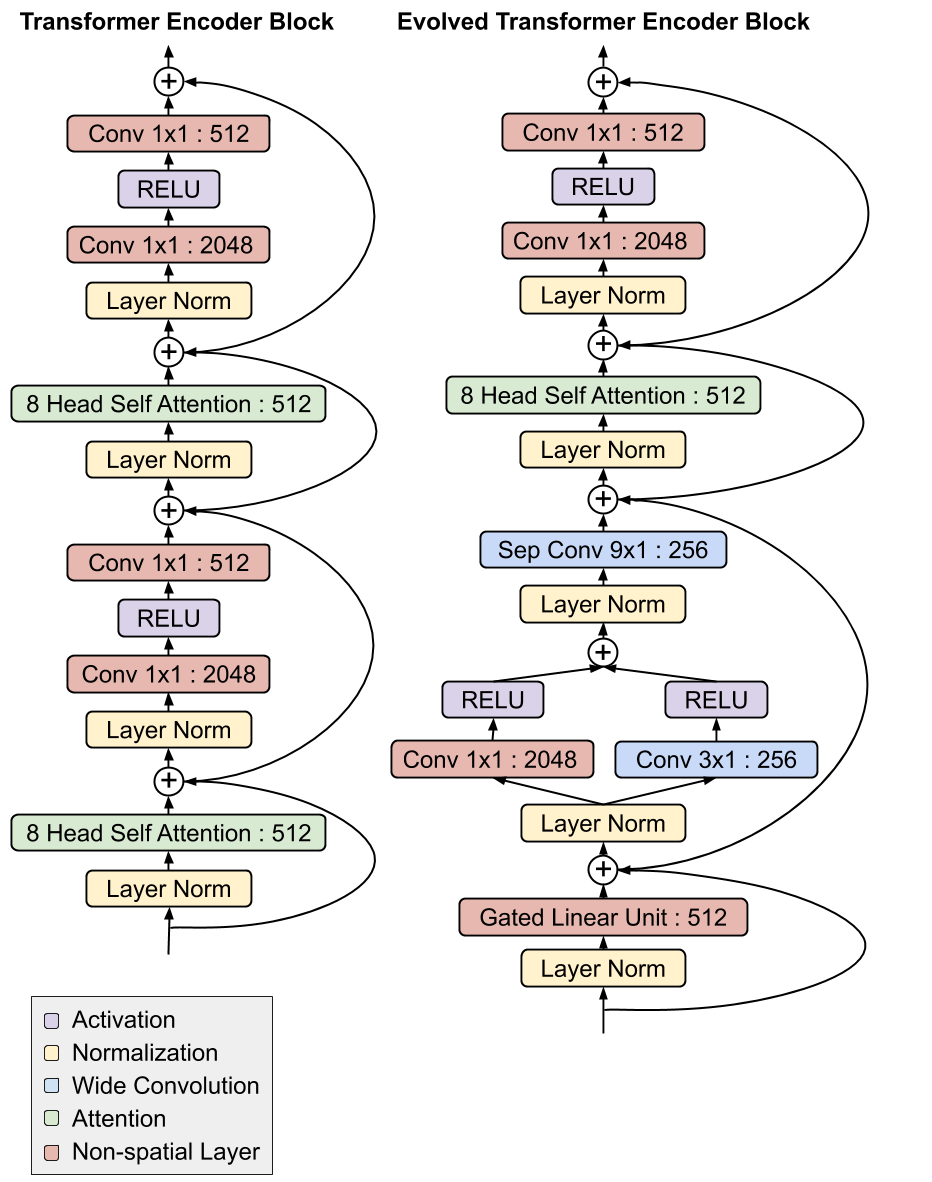 |
| A comparison between the Evolved Transformer and the original Transformer encoder architectures. Notice the branched convolution structure at the bottom of the module, which formed in both the encoder and decoder independently. See our paper for a description of the decoder. |
Evaluation of the Evolved Transformer
To test the effectiveness of this new architecture, we first compared it to the original Transformer on the English-German translation task we used during the search. We found that the Evolved Transformer had better BLEU and perplexity performance at all parameter sizes, with the biggest gain at the size compatible with mobile devices (~7 million parameters), demonstrating an efficient use of parameters. At a larger size, the Evolved Transformer reaches state-of-the-art performance on WMT’ 14 En-De with a BLEU score of 29.8 and a SacreBLEU score of 29.2.
 |
| Comparison between the Evolved Transformer and the original Transformer on WMT’14 En-De at varying sizes. The biggest gains in performance occur at smaller sizes, while ET also shows strength at larger sizes, outperforming the largest Transformer with 37.6% less parameters (models to compare are circled in green). See Table 3 in our paper for the exact numbers. |

These results are the first step in exploring the application of architecture search to feed forward sequence models. The Evolved Transformer is being open sourced as part of Tensor2Tensor, where it can be used for any sequence problem. To promote reproducibility, we are also open sourcing the search space we used for our search and a Colab with an implementation of Progressive Dynamic Hurdles. We look forward to seeing what the research community does with the new model and hope that others are able to build off of these new search techniques!