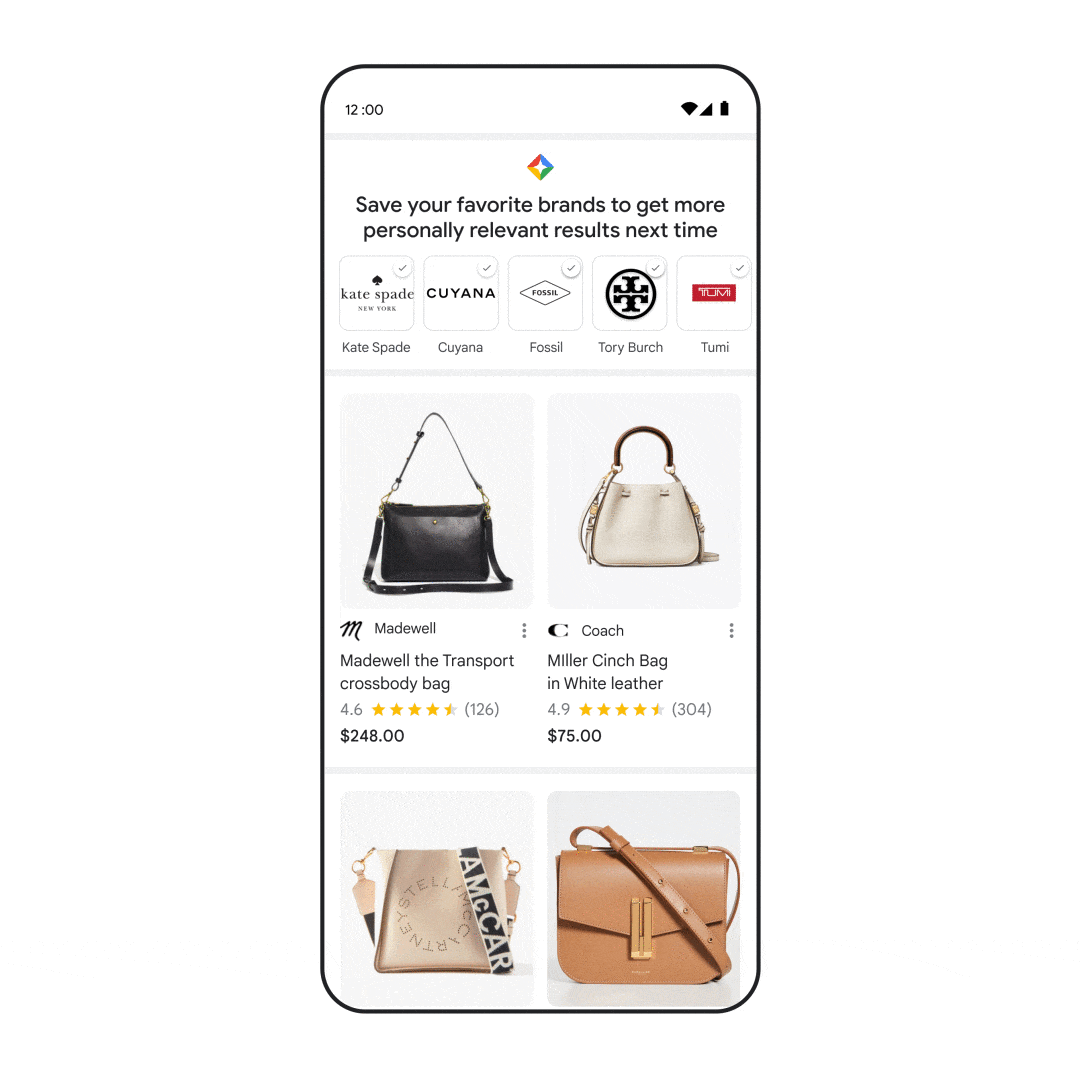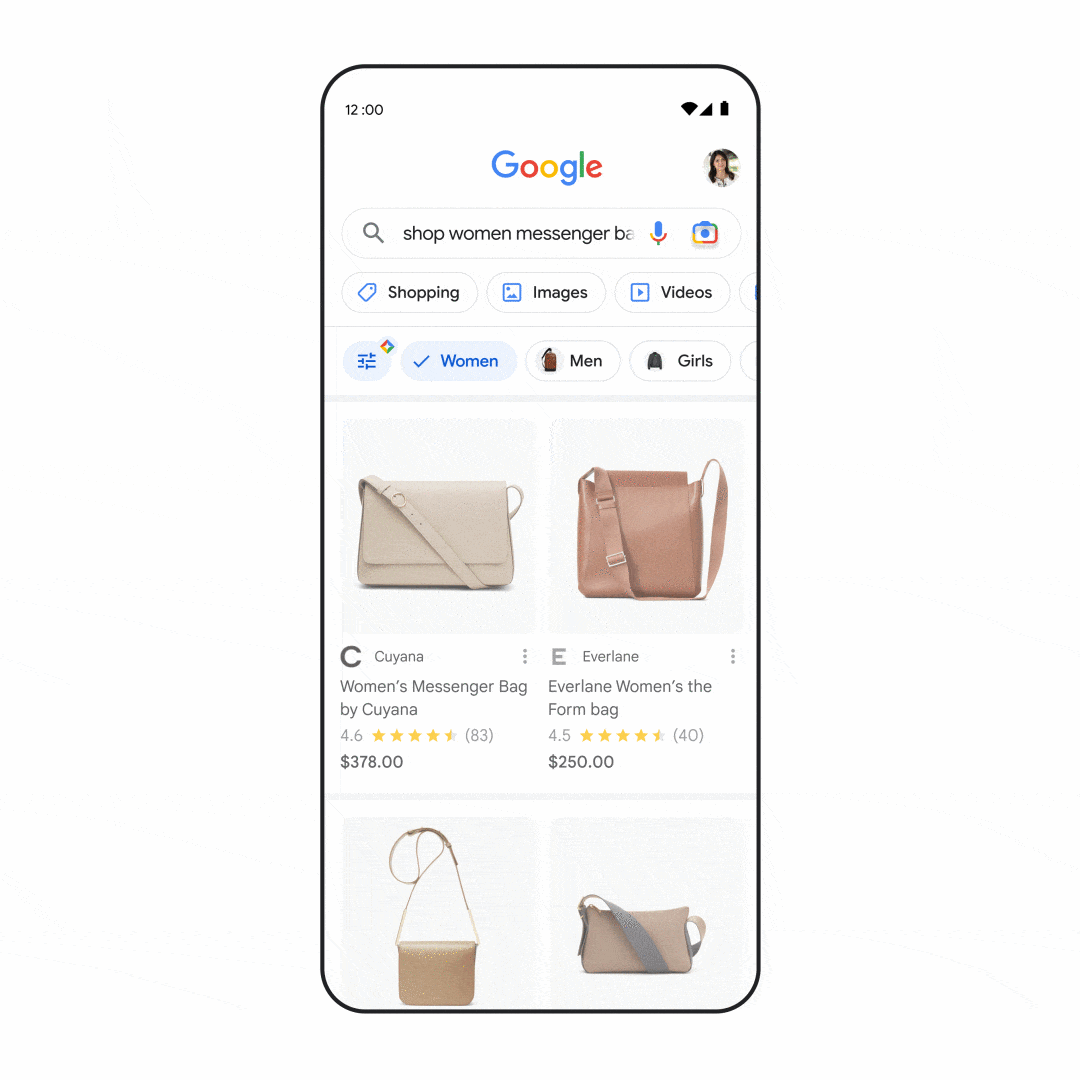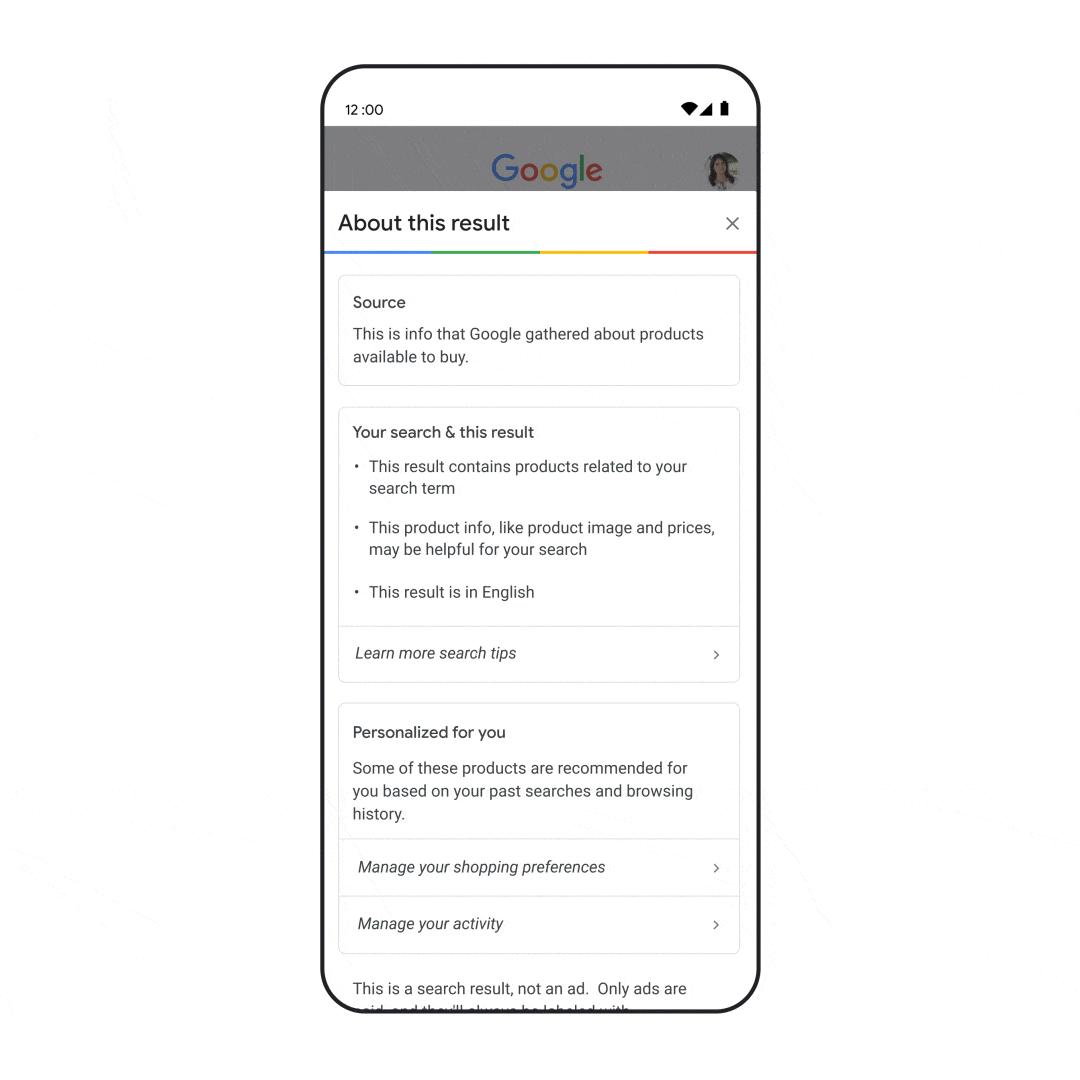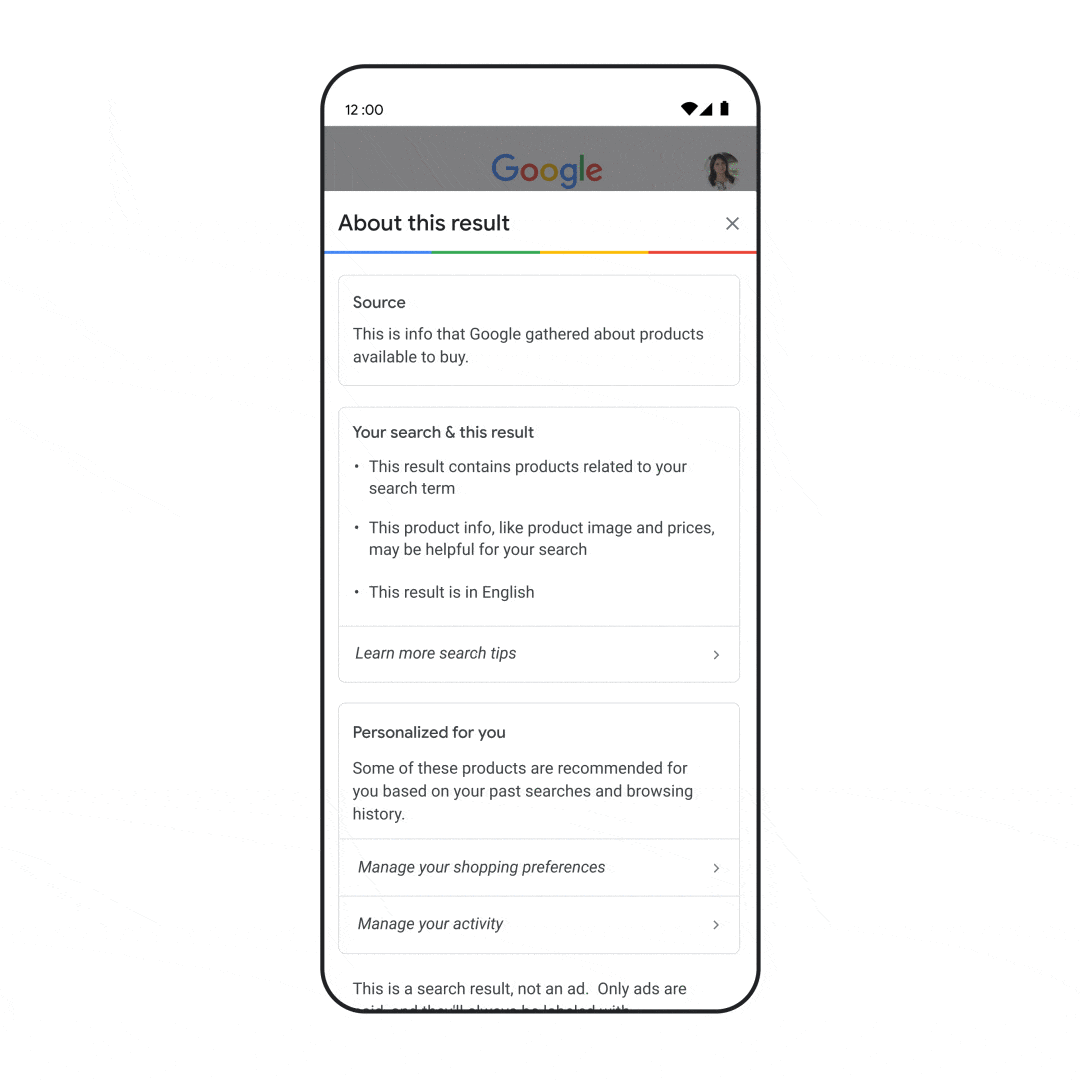
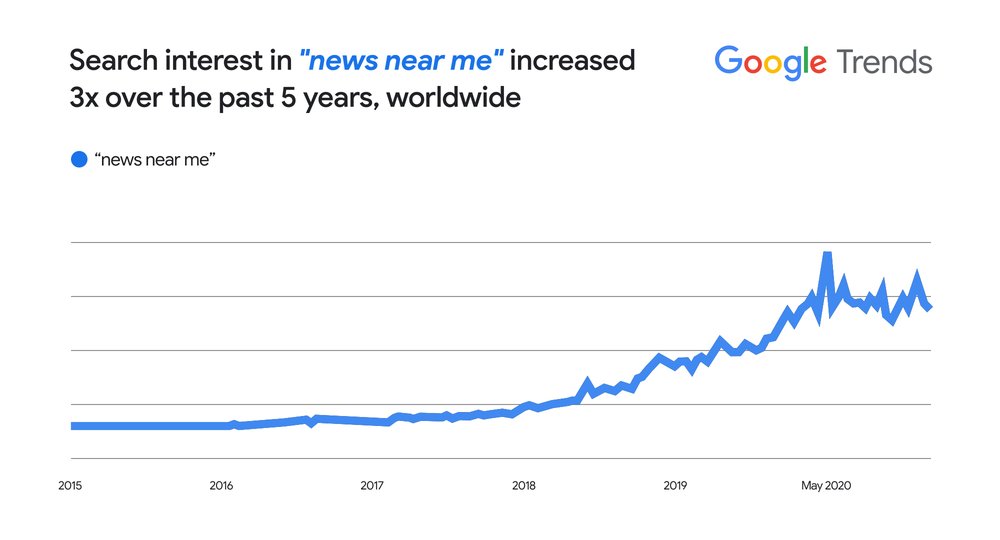
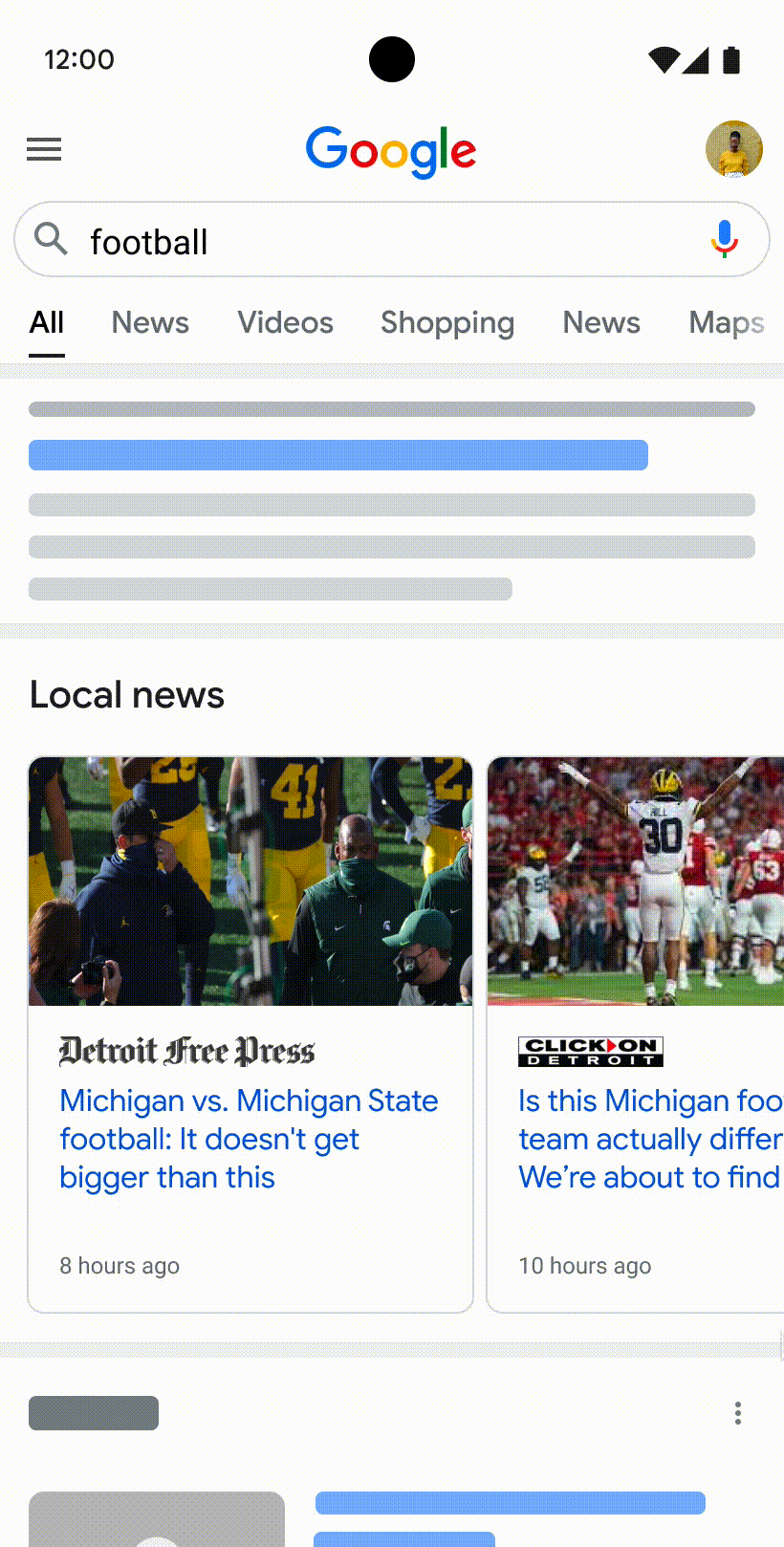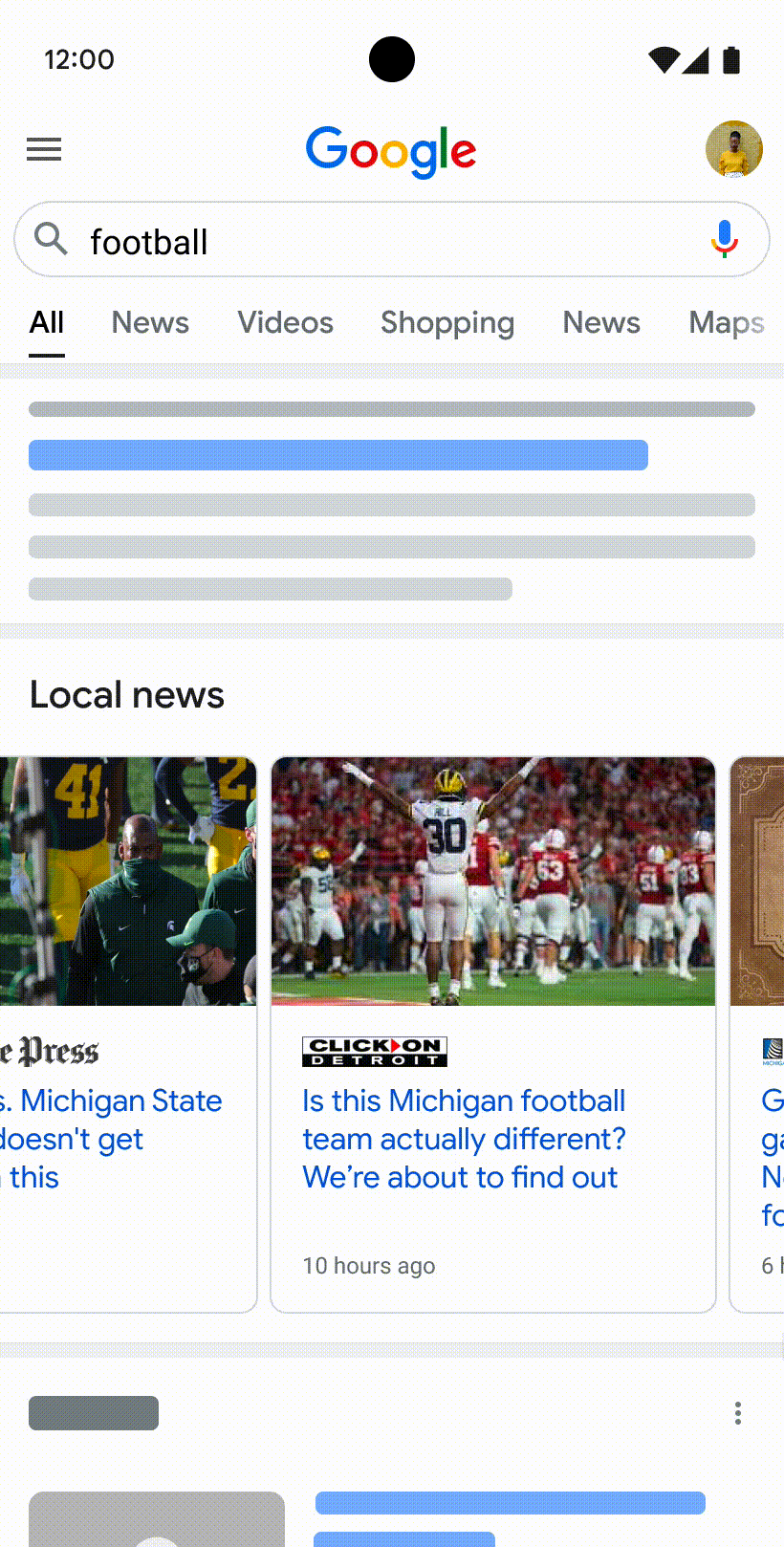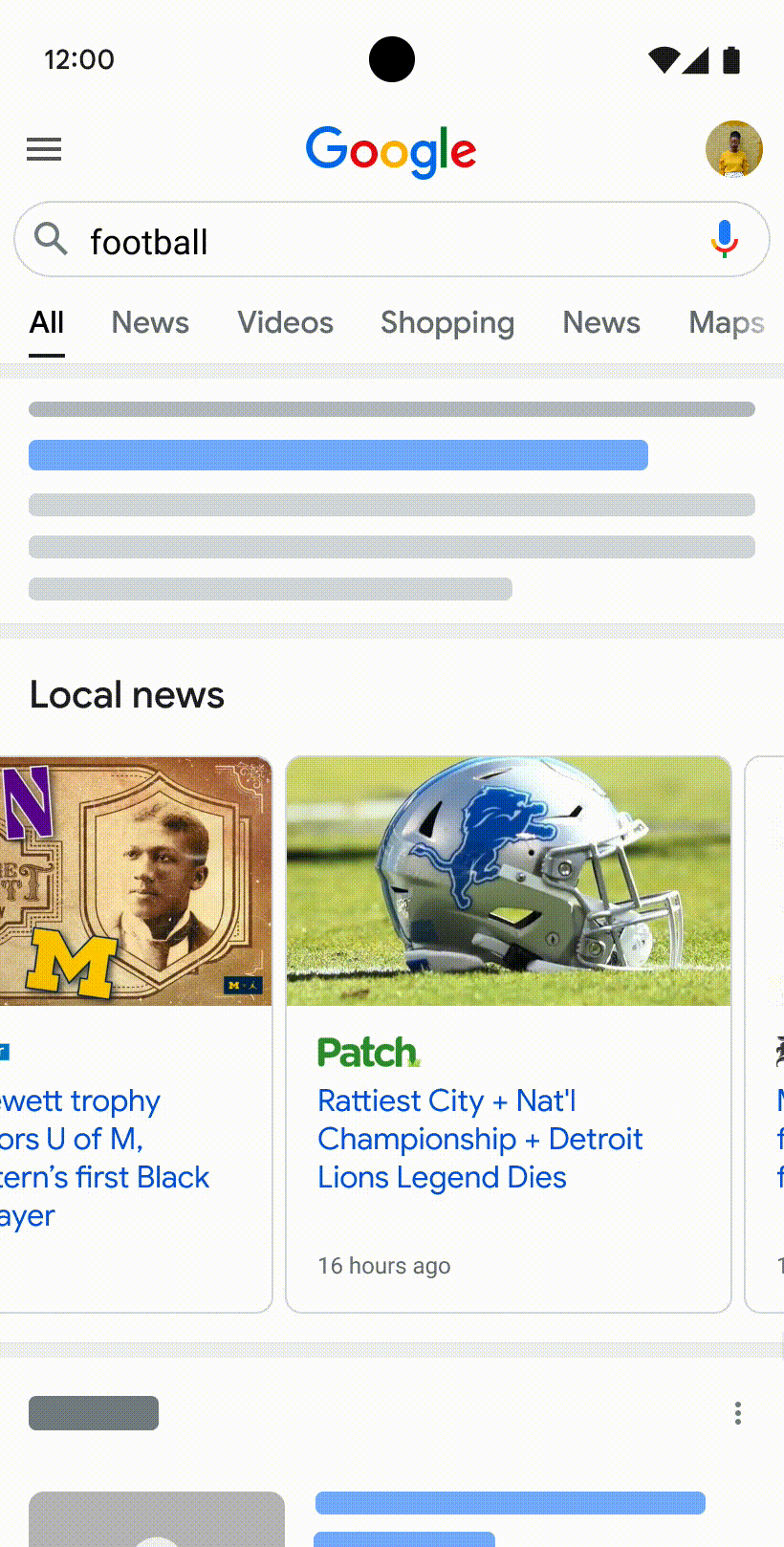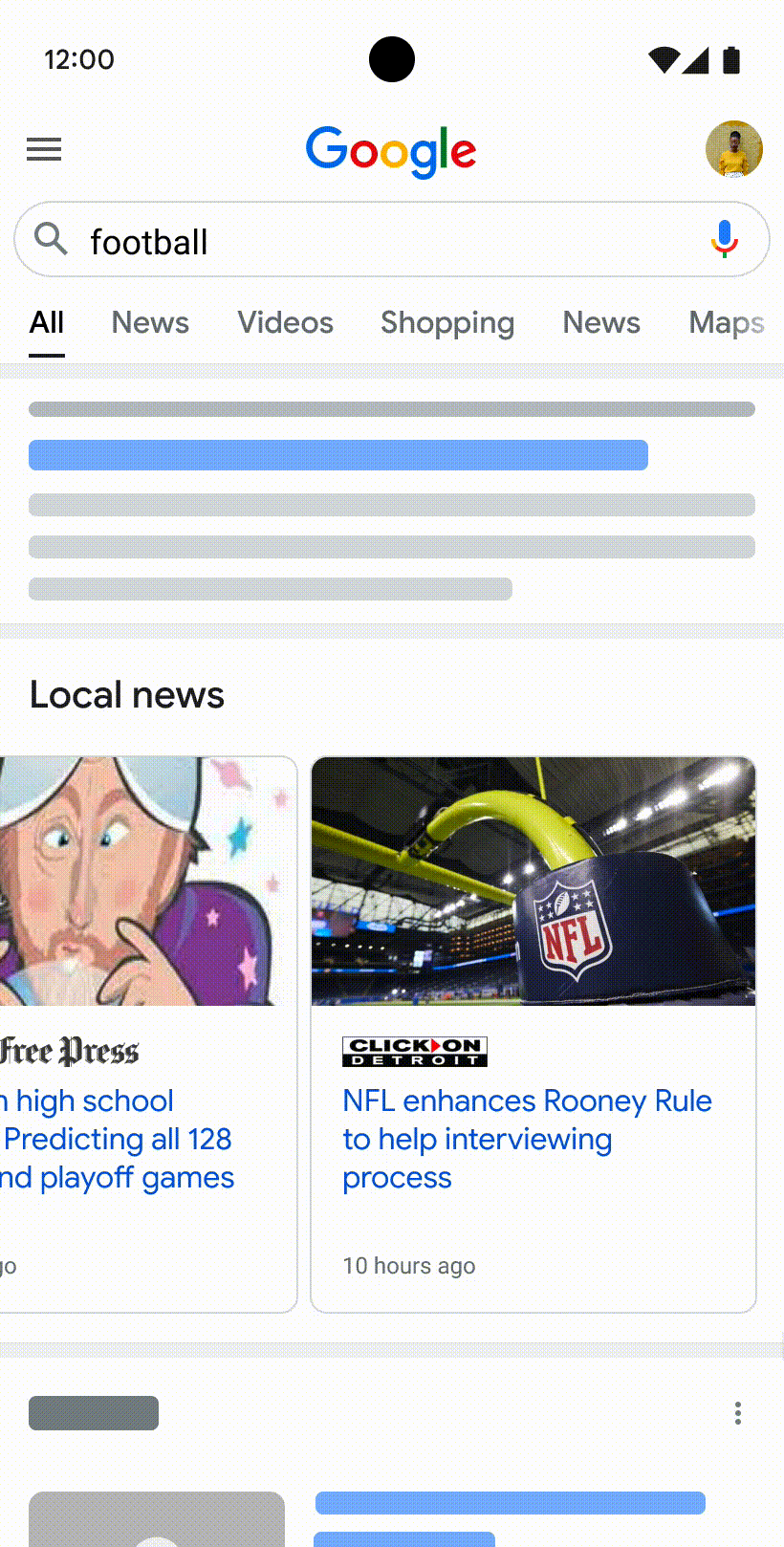
Many of us have experienced the frustration of visiting a web page that seems like it has what we’re looking for, but doesn’t live up to our expectations. The content might not have the insights you want, or it may not even seem like it was created for, or even by, a person.
We work hard to make sure the pages we show on Search are as helpful and relevant as possible. To do this, we constantly refine our systems: Last year, we launched thousands of updates to Search based on hundreds of thousands of quality tests, including evaluations where we gather feedback from human reviewers.
We know people don’t find content helpful if it seems like it was designed to attract clicks rather than inform readers. So starting next week for English users globally, we’re rolling out a series of improvements to Search to make it easier for people to find helpful content made by, and for, people. This ranking work joins a similar effort related to ranking better quality product review content over the past year, which will also receive an update. Together, these launches are part of a broader, ongoing effort to reduce low-quality content and make it easier to find content that feels authentic and useful in Search.
Better ranking of original, quality content
We continually update Search to make sure we're helping you find high quality content. Next week, we'll launch the “helpful content update” to tackle content that seems to have been primarily created for ranking well in search engines rather than to help or inform people. This ranking update will help make sure that unoriginal, low quality content doesn’t rank highly in Search, and our testing has found it will especially improve results related to online education, as well as arts and entertainment, shopping and tech-related content.
For example, if you search for information about a new movie, you might have previously seen articles that aggregated reviews from other sites without adding perspectives beyond what’s available elsewhere. This isn’t very helpful if you’re expecting to read something new. With this update, you’ll see more results with unique, authentic information, so you’re more likely to read something you haven't seen before.
As always, we'll continue to refine our systems and build on this improvement over time. If you’re a content creator, you can learn more about today’s update and guidance to consider on Search Central.
More helpful product reviews written by experts
We know product reviews can play an important role in helping you make a decision on something to buy. Last year, we kicked off a series of updates to show more helpful, in-depth reviews based on first-hand expertise in search results.
We've continued to refine these systems, and in the coming weeks, we’ll roll out another update to make it even easier to find high-quality, original reviews. We’ll continue this work to make sure you find the most useful information when you’re researching a purchase on the web.
We hope these updates will help you access more helpful information and valuable perspectives on Search. We look forward to building on this work to make it even easier to find original content by and for real people in the months ahead.
 For our 25th birthday, we’re looking back at some of the milestones that made Google more helpful, from Autocomplete to Multisearch and beyond.
For our 25th birthday, we’re looking back at some of the milestones that made Google more helpful, from Autocomplete to Multisearch and beyond.