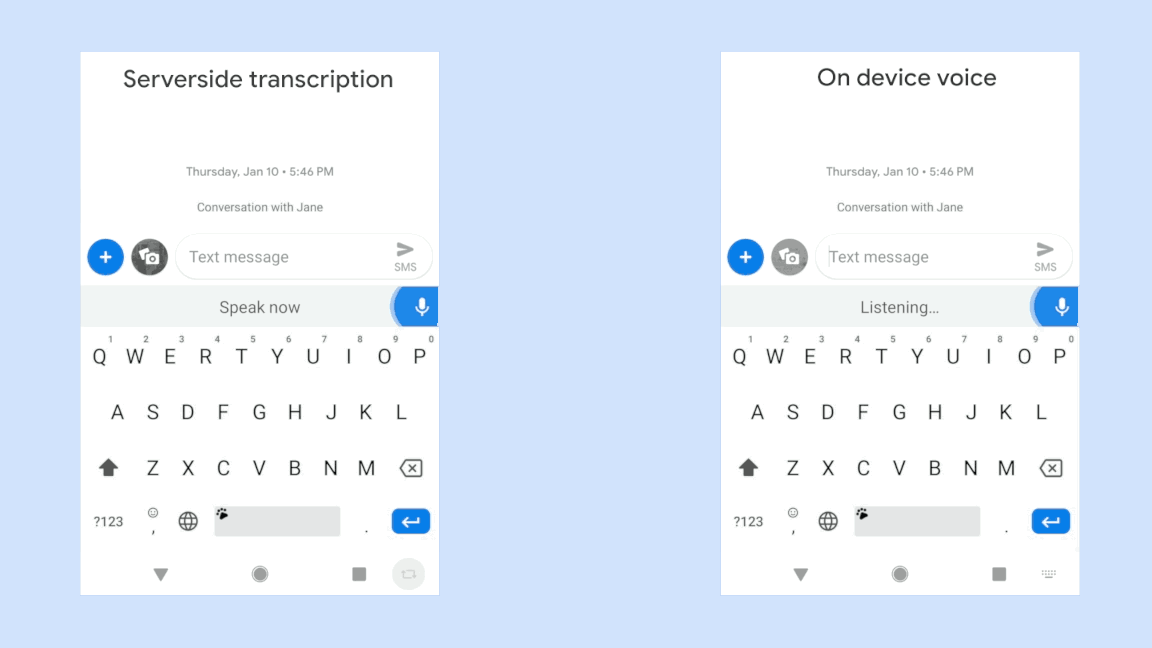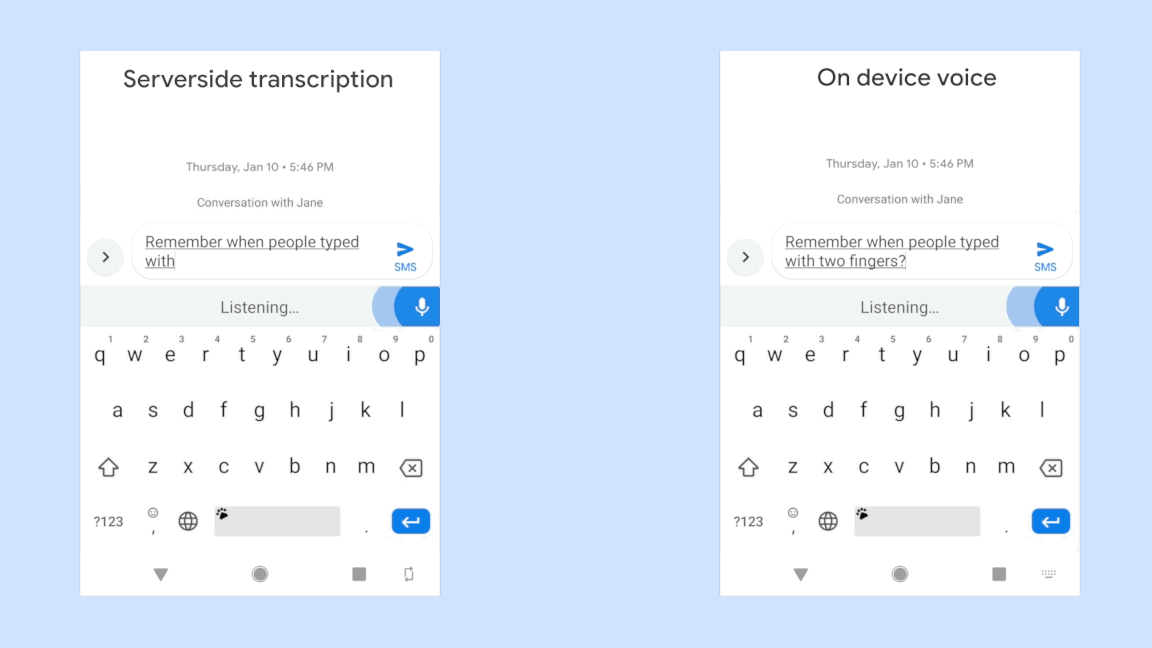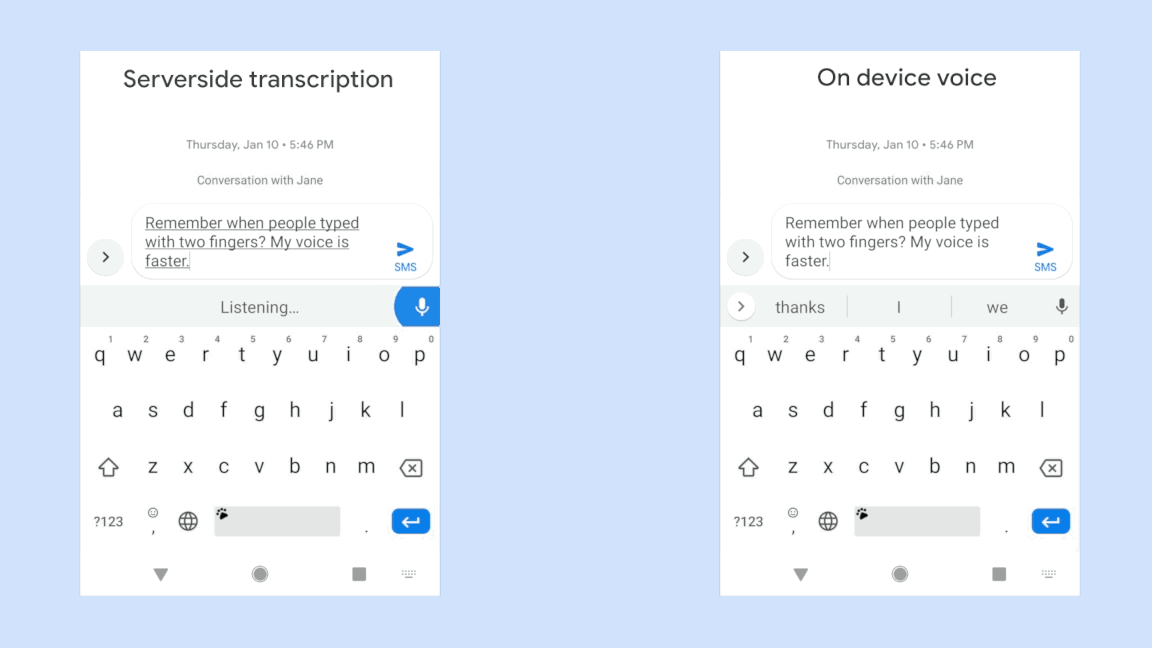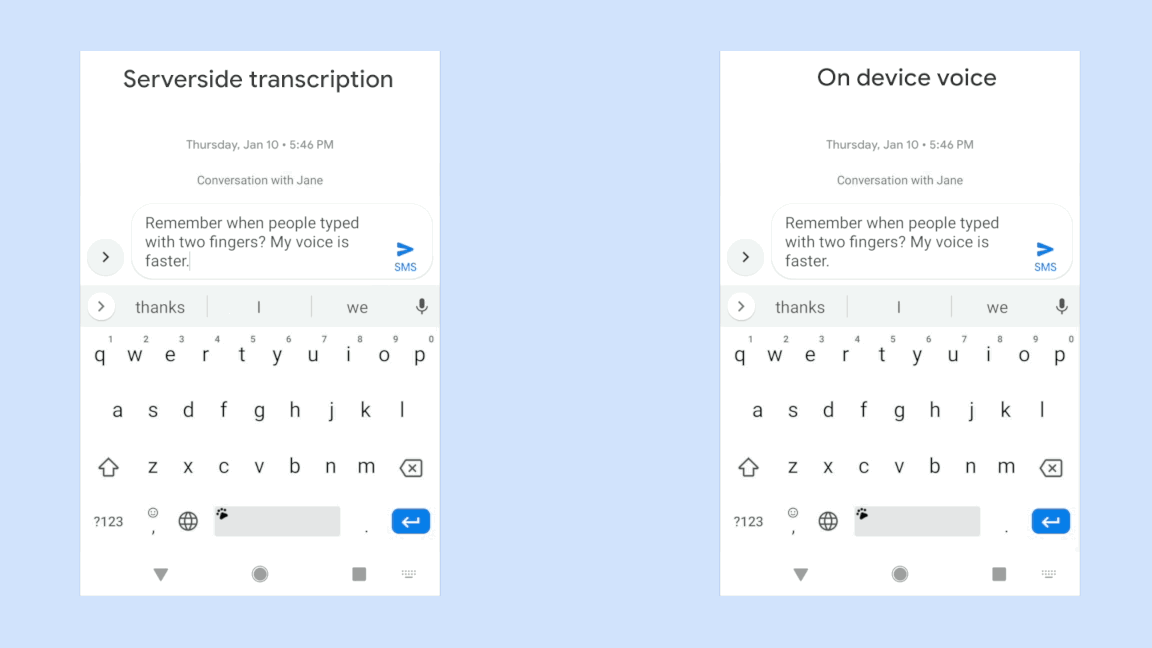
Voice assistive technologies, which enable users to employ voice commands to interact with their devices, rely on accurate speech recognition to ensure responsiveness to a specific user. But in many real-world use cases, the input to such technologies often consists of overlapping speech, which poses great challenges to many speech recognition algorithms. In 2018, we published a VoiceFilter system, which leverages Google’s Voice Match to personalize interaction with assistive technology by allowing people to enroll their voices.
While the VoiceFilter approach is highly successful, achieving a better source to distortion ratio (SDR) than conventional approaches, efficient on-device streaming speech recognition requires addressing restrictions such as model size, CPU and memory limitations, as well as battery usage considerations and latency minimization.
In “VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition”, we present an update to VoiceFilter for on-device use that can significantly improve speech recognition in overlapping speech by leveraging the enrolled voice of a selected speaker. Importantly, this model can be easily integrated with existing on-device speech recognition applications, allowing the user to access voice assistive features under extremely noisy conditions even if an internet connection is unavailable. Our experiments show that a 2.2MB VoiceFilter-Lite model provides a 25.1% improvement to the word error rate (WER) on overlapping speech.
Improving On-Device Speech Recognition
While the original VoiceFilter system was very successful at separating a target speaker's speech signal from other overlapping sources, its model size, computational cost and latency are not feasible for speech recognition on mobile devices.
The new VoiceFilter-Lite system has been carefully designed to fit on-device applications. Instead of processing audio waveforms, VoiceFilter-Lite takes exactly the same input features as the speech recognition model (stacked log Mel-filterbanks), and directly enhances these features by filtering out components not belonging to the target speaker in real time. Together with several optimizations on network topologies, the number of runtime operations is drastically reduced. After quantizing the neural network with the TensorFlow Lite library, the model size is only 2.2 MB, which fits most on-device applications.
To train the VoiceFilter-Lite model, the filterbanks of the noisy speech are fed as input to the network together with an embedding vector that represents the identity of the target speaker (i.e., a d-vector). The network predicts a mask that is element-wise multiplied to the input to produce enhanced filterbanks. A loss function is defined to minimize the difference between the enhanced filterbanks and the filterbanks from the clean speech during training.
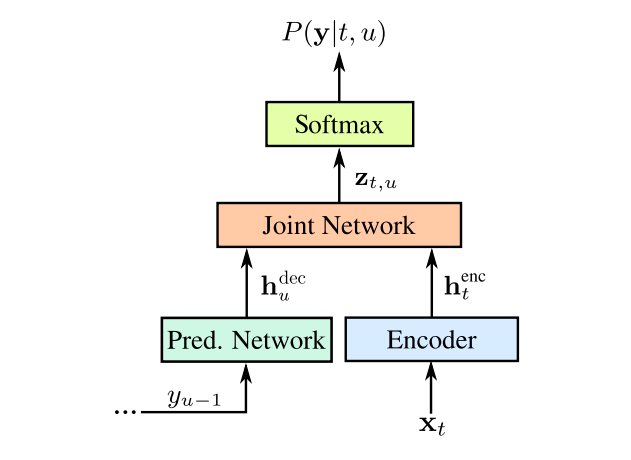
 |
| Model architecture of the VoiceFilter-Lite system. |
VoiceFilter-Lite is a plug-and-play model, which allows the application in which it’s implemented to easily bypass it if the speaker did not enroll their voice. This also means that the speech recognition model and the VoiceFilter-Lite model can be separately trained and updated, which largely reduces engineering complexity in the deployment process.
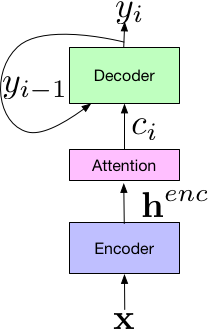
 |
| As a plug-and-play model, VoiceFilter-Lite can be easily bypassed if the speaker did not enroll their voice. |
Addressing the Challenge of Over-Suppression
When speech separation models are used for improving speech recognition, two types of error could occur: under-suppression, when the model fails to filter out noisy components from the signal; and over-suppression, when the model fails to preserve useful signal, resulting in some words being dropped from the recognized text. Over-suppression is especially problematic since modern speech recognition models are usually already trained with extensively augmented data (such as room simulation and SpecAugment), and thus are more robust to under-suppression.
VoiceFilter-Lite addresses the over-suppression issue with two novel approaches. First, it uses an asymmetric loss during the training process, such that the model is less tolerant to over-suppression than under-suppression. Second, it predicts the type of noise at runtime, and adaptively adjusts the suppression strength according to this prediction.
 |
| VoiceFilter-Lite adaptively applies stronger suppression strength when overlapping speech is detected. |
With these two solutions, the VoiceFilter-Lite model retains great performance on streaming speech recognition for other scenarios, such as single-speaker speech under quiet or various noise conditions, while still providing significant improvement on overlapping speech. From our experiments, we observed a 25.1% improvement of word error rate after the 2.2MB VoiceFilter-Lite model is applied on additive overlapping speech. For reverberant overlapping speech, which is a more challenging task to simulate far-field devices such as smart home speakers, we also observed a 14.7% improvement of word error rate with VoiceFilter-Lite.
Future Work
While VoiceFilter-Lite has shown great promise for various on-device speech applications, we are also exploring several other directions to make VoiceFilter-Lite more useful. First, our current model is trained and evaluated with English speech only. We are excited about adopting the same technology to improve speech recognition for more languages. Second, we would like to directly optimize the speech recognition loss during the training of VoiceFilter-Lite, which can potentially further improve speech recognition beyond overlapping speech.
Acknowledgements
The research described in this post represents joint efforts from multiple teams within Google. Contributors include Quan Wang, Ignacio Lopez Moreno, Mert Saglam, Kevin Wilson, Alan Chiao, Renjie Liu, Yanzhang He, Wei Li, Jason Pelecanos, Philip Chao, Sinan Akay, John Han, Stephen Wu, Hannah Muckenhirn, Ye Jia, Zelin Wu, Yiteng Huang, Marily Nika, Jaclyn Konzelmann, Nino Tasca, and Alexander Gruenstein.