In June 2023, support for Python 3.7 was deprecated in the Google Ads API Client Library for Python. In Q1 2024, a major version of the library will be released that makes it incompatible with Python 3.7. Library changes related to compatibility with Python 3.7 will be limited to critical security or stability patches.
Google Ads API users who depend on Python 3.7 can continue using version 22.1.0 of the library, which includes API v15 support, until v15 of the is sunset in September 2024. All Python users should upgrade to Python 3.8 or higher as soon as possible.
In the future, Python users should expect that the library will become incompatible with unsupported versions of Python as soon as they reach end-of-life status. When Python 3.8 becomes unsupported in October 2024, a major version of the library will be released that is incompatible with Python 3.8. At least two months before a Python version deprecation, we will publish a blog post to help remind users of the change.
The below resources are available to help users plan ahead for future language support removal:
The Python Developer’s Guide shows the end-of-life date for all currently supported Python versions.
The supported API versions table documents which versions of our client libraries are compatible with currently supported Google Ads API versions.
The Python dependencies table documents the library’s compatibility with individual dependency versions.
If you have any questions about this change, please file an issue on the client library repository on GitHub. - Ben Karl, on behalf of the Google Ads API Team
On June 27, 2023, Python 3.7 will reach end-of-life and will no longer be supported by the Python Software Foundation. Once Python 3.7 officially reaches end-of-life status, it will also no longer be supported by the Google Ads client library for Python.
While this will not change the functionality of the client library, any issues or bugs related to the library's compatibility with Python 3.7 will not be addressed, and any documentation related to Python 3.7 will be removed.
We recommend library users upgrade their systems to Python 3.8 or higher as soon as possible.
If you have any questions about this change, please file an issue on the client library repository. - Ben Karl, on behalf of the Google Ads API Team
The Serverless Migration Station series is aimed at helping developers modernize their apps running one of Google Cloud's serverless platforms. The preceding (Migration Module 20) video demonstrates how to add use of App Engine's Users service to a Python 2 App Engine sample app. Today's Module 21 video picks up from where that leaves off, migrating that usage to Cloud Identity Platform.
How to migrate the App Engine Users to Cloud Identity Platform
Move to VM-based services like GKE or Compute Engine, or to other compute platforms
Understanding the overall migration
Overall, Module 21 features major changes to the Module 20 sample app, implementing a move from App Engine bundled services (NDB & Users) to standalone Cloud services (Cloud Datastore & Identity Platform). Identity Platform doesn't know anything about App Engine admins, so that must be built, requiring the use of the Cloud Resource Manager API. Apps dependent on Python 2 have additional required updates. Let's discuss in a bit more detail.
Migration "parts"
The following changes to the sample app are required:
Migrate from App Engine Users (server-side) to Cloud Identity Platform (client-side)
Migrate from App Engine NDB, the other bundled service used in Module 20, to Cloud NDB (requires use of the Cloud Datastore API)
Move from App Engine bundled services to standalone Cloud services
The NDB to Cloud NDB migration is identical to the Module 2 migration content, so it's not covered in-depth here in Module 21. The primary focus is on switching to Identity Platform to continue supporting user logins as well as implementing use of the Resource Manager and Firebase Admin SDK to build a proxy for recognizing App Engine admin users as provided by the Users service. Below is pseudocode implementing the key changes to the main application where new or updated lines of code are bolded:
Migrating from App Engine Users to Cloud Identity Platform(click to enlarge)
The key differences to note:
The server-side Users service code vanishes from the main application, moving into the (client-side) web template (not shown here).
Practically all of the new code in the Module 21 app above is for recognizing App Engine admin users. There are no changes to app operations or data models other than Cloud NDB requiring use of Python context managers to wrap all Datastore code (using Python with blocks).
Complete versions of the app before and after the updates can be found in the Module 20 (Python 2) and Module 21 (Python 3) repo folders, respectively. In addition to the video, be sure to check out the Identity Platform documentation as well as the Module 21 codelab which leads you step-by-step through the migrations discussed.
Aside from the necessary coding changes as well as moving from server-side to client-side, note that the Users service usage is covered by App Engine's pricing model while Identity Platform is an independent Cloud service billed by MAUs (monthly active users), so costs should be taken into account if migrating. More information can be found in the Identity Platform pricing documentation.
Python 2 considerations
With the sunset of Python 2, Java 8, PHP 5, and Go 1.11, by their respective communities, Google Cloud has assured users by expressing continued long-term support of these legacy App Engine runtimes, including maintaining the Python 2 runtime. So while there is no current requirement for users to migrate, developers themselves are expressing interest in updating their applications to the latest language releases. The primary Module 21 migration automatically includes a port from Python 2 to 3 as that's where most developers are headed. For those with dependencies requiring remaining on Python 2, some additional effort is required:
Using 3rd-party packages requires some App Engine Python 2.7 built-in libraries (grpcio and setuptools), meaning additional changes to configuration files, app.yaml and appengine_config.py. There is no support for built-in libraries in the Python 3 runtime, so just list desired packages in requirements.txt, and those libraries will be automatically installed during deployment.
The codelab covers this backport in-depth, so check out the specific section for Python 2 users if you're in this situation. If you don't want to think about it, just head to the repo for a working Python 2 version of the Module 21 app.
Wrap-up
Module 21 features migrations of App Engine bundled services to appropriate standalone Cloud services. While we recommend users modernize their App Engine apps by moving to the latest offerings from Google Cloud, these migrations are not required. In Fall 2021, the App Engine team extended support of many of the bundled services to 2nd generation runtimes (that have a 1st generation runtime), meaning you don't have to migrate to standalone services before porting your app to Python 3. You can continue using App Engine NDB and Users in Python 3 so long as you retrofit your code to access bundled services from next-generation runtimes. Then should you opt to migrate, you can do so on your own timeline.
If you're using other App Engine legacy services be sure to check out the other Migration Modules in this series. All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, the Cloud team is working on covering other language runtimes, so stay tuned. For additional video content, check out our broader Serverless Expeditions series.
The Serverless Migration Stationvideo series and corresponding codelabs aim to help App Engine developers modernize their apps, whether it's upgrading language runtimes like from Python 2 to 3 and Java 8 to 17, or to move laterally to sister serverless platforms like Cloud Functions or Cloud Run. For developers who want more control, like being able to SSH into instances, Compute Engine VMs or GKE, our managed Kubernetes service, are also viable options.
In order to consider moving App Engine apps to other compute services, developers must move their apps away from its original APIs (now referred to as legacy bundled services), either to Cloud standalone replacement or alternative 3rd-party services. Once no longer dependent on these proprietary services, apps become much more portable. Apps can stay on App Engine while upgrading to its 2nd-generation platform, or move to other compute platforms as listed above.
Today's Migration Module 20 content focuses on helping developers refamiliarize themselves with App Engine's Users service, a user authentication system serving as a lightweight wrapper around Google Sign-In (now called Google Identity Services). The video and its corresponding codelab (self-paced, hands-on tutorial) demonstrate how to add use of the Users service to the sample baseline app from Module 1. After adding the Users service in Module 20, Module 21 follows, showing developers how to migrate that usage to Cloud Identity Platform.
How to use the App Engine Users service
Adding use of Users service
The sample app's basic functionality consists of registering each page visit in Datastore and displaying the most recent visits. The Users service helps apps support user logins, App Engine administrative ("admin'") users. It also provides convenient functions for generating login/logout links and retrieving basic user information for logged-in users. Below is a screenshot of the modified app which now supports user logins via the user interface (UI):
Sample app now supports user logins and App Engine admin users (click to enlarge)
Below is the pseudocode reflecting the changes made to support user logins for the sample app, including integrating the Users service and updating what shows up in the UI:
If the user is logged in, show their "nickname" (display name or email address) and display a Logout button. If the logged-in user is an App Engine app admin, also display an "admin" badge (between nickname and Logout button).
If the user is not logged in, display the username generically as "user", remove any admin badge, and display a Login button.
Because the Users service is primarily a user-facing endeavor, the most significant changes take place in the UI, whereas the data model and core functionality of registering visits remain unchanged. The new support for user management primarily results in additional context to be rendered in the web template. New or altered code is bolded to highlight the updates.
Adding App Engine Users service usage to sample app (click to enlarge)
Wrap-up
Today's "migration" consists of adding usage of the App Engine Users service to support user management and recognize App Engine admin users, starting with the Module 1 baseline app and finishing with the Module 20 app. To get hands-on experience doing it yourself, try the codelab and follow along with the video. Then you'll be ready to upgrade to Identity Platform should you choose to do so.
In Fall 2021, the App Engine team extended support of many of the bundled services to 2nd generation runtimes (that have a 1st generation runtime), meaning you are no longer required to migrate from the Users service to Identity Platform when porting your app to Python 3. You can continue using the Users service in your Python 3 app so long as you retrofit the code to access bundled services from next-generation runtimes.
If you do want to move to Identity Platform, see the Module 21 content, including its codelab. All Serverless Migration Station content (codelabs, videos, and source code [when available]) are available at its open source repo. While we're initially focusing on Python users, the Cloud team is covering other runtimes soon, so stay tuned. Also check out other videos in the broader Serverless Expeditions series.
Move to VM-based services like GKE or Compute Engine, or to other compute platforms
Understanding the migrations
Module 19 consists of implementing three different migrations on the Module 18 sample app:
Migrate from App Engine NDB to Cloud NDB
Migrate from App Engine Task Queue pull tasks to Cloud Pub/Sub
Migrate from Python 2 to Python (2 and) 3
The NDB to Cloud NDB migration is identical to the Module 2 migration content, so it's not covered in-depth in Module 19. The original app was designed to be Python 2 and 3 compatible, so there's no work there either. Module 19 boils down to three key updates:
Setup: Enable APIs and create Pub/Sub Topic & Subscription
How work is created: Publish Pub/Sub messages instead of adding pull tasks
How work is processed: Pull messages instead of leasing tasks
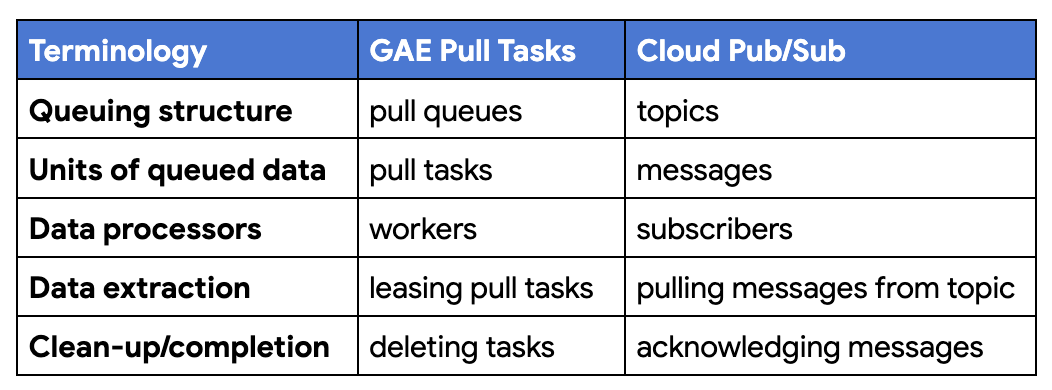
Aside from these physical changes, a key hurdle to overcome is understanding the differences in terminology between pull tasks and Pub/Sub. The following chart attempts to demystify this so developers can more easily grasp how they differ:
Terminology differences between App Engine pull tasks and Cloud Pub/Sub
Reflecting the chart, these differences can be summarized like this:
With Pull Queues, work is created in pull queues while work is sent to Pub/Sub topics
Task Queue pull tasks are called messages in Pub/Sub
With Task Queues, workers access pull tasks; with Pub/Sub, subscribers receive messages
Leasing a pull task is the same as pulling a message from a Pub/Sub topic via a subscription
Deleting a task from a pull queue when you're done is analogous to successfully acknowledging a Pub/Sub message
The video walks developers through the terminology as well as the code changes described above. Below is pseudocode implementing the key changes to the main application (new or updated lines of code bolded):
Migration from App Engine Task Queue pull tasks to Cloud Pub/Sub
Observe how most of the code, especially app operations and data models are left relatively unchanged. The only visible changes are switching from App Engine NDB and Task Queue to Cloud NDB and Pub/Sub. Complete versions of the app before and after making the changes can be found in the Module 18 and Module 19 repo folders, respectively. In addition to the video, be sure to check out the Module 19 codelab which leads you step-by-step through the migrations discussed.
Wrap-up
Module 19 features a migration of App Engine pull tasks to Cloud Pub/Sub, but developers should note that Pub/Sub itself is not based on pull tasks. It is a fully-featured asynchronous, scalable messaging service that has many more features than the pull functionality provided by Task Queue. For example, Pub/Sub has other features like streaming to BigQuery and push functionality. Pub/Sub push operates differently than Task Queue push tasks, hence why we recommend push tasks be migrated to Cloud Tasks instead (see Module 8). For more information on all of its features, see the Pub/Sub documentation. Because Cloud Tasks doesn't support pull functionality, we turn to Pub/Sub instead for pull task users.
While we recommend users move to the latest offerings from Google Cloud, neither of those migrations are required, and should you opt to do so, can do them on your own timeline. In Fall 2021, the App Engine team extended support of many of the bundled services to 2nd generation runtimes (that have a 1st generation runtime), meaning you don't have to migrate to standalone Cloud services before porting your app to Python 3. You can continue using Task Queue in Python 3 so long as you retrofit your code to access bundled services from next-generation runtimes.
If you're using other App Engine legacy services be sure to check out the other Migration Modules in this series. All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, the Cloud team is working on covering other language runtimes, so stay tuned. For additional video content, check out our broader Serverless Expeditions series.
The Serverless Migration Station mini-series helps App Engine developers modernize their apps to the latest language runtimes, such as from Python 2 to 3 or Java 8 to 17, or to sister serverless platforms Cloud Functions and Cloud Run. Another goal of this series is to demonstrate how to move away from App Engine's original APIs (now referred to as legacy bundled services) to Cloud standalone replacement services. Once no longer dependent on these proprietary services, apps become much more portable, making them flexible enough to:
Move to VM-based services like GKE or Compute Engine, or to other compute platforms
App Engine's Task Queue service provides infrastructure for executing tasks outside of the standard request-response workflow. Tasks may consist of workloads exceeding request timeouts or periodic tangential work. The Task Queue service provides two different queue types, push and pull, for developers to perform auxiliary work.
Push queues are covered in Migration Modules 7-9, demonstrating how to add use of push tasks to an existing baseline app followed by steps to migrate that functionality to Cloud Tasks, the standalone successor to the Task Queues push service. We turn to pull queues in today's video where Module 18 demonstrates how to add use of pull tasks to the same baseline sample app. Module 19 follows, showing how to migrate that usage to Cloud Pub/Sub.
Adding use of pull queues
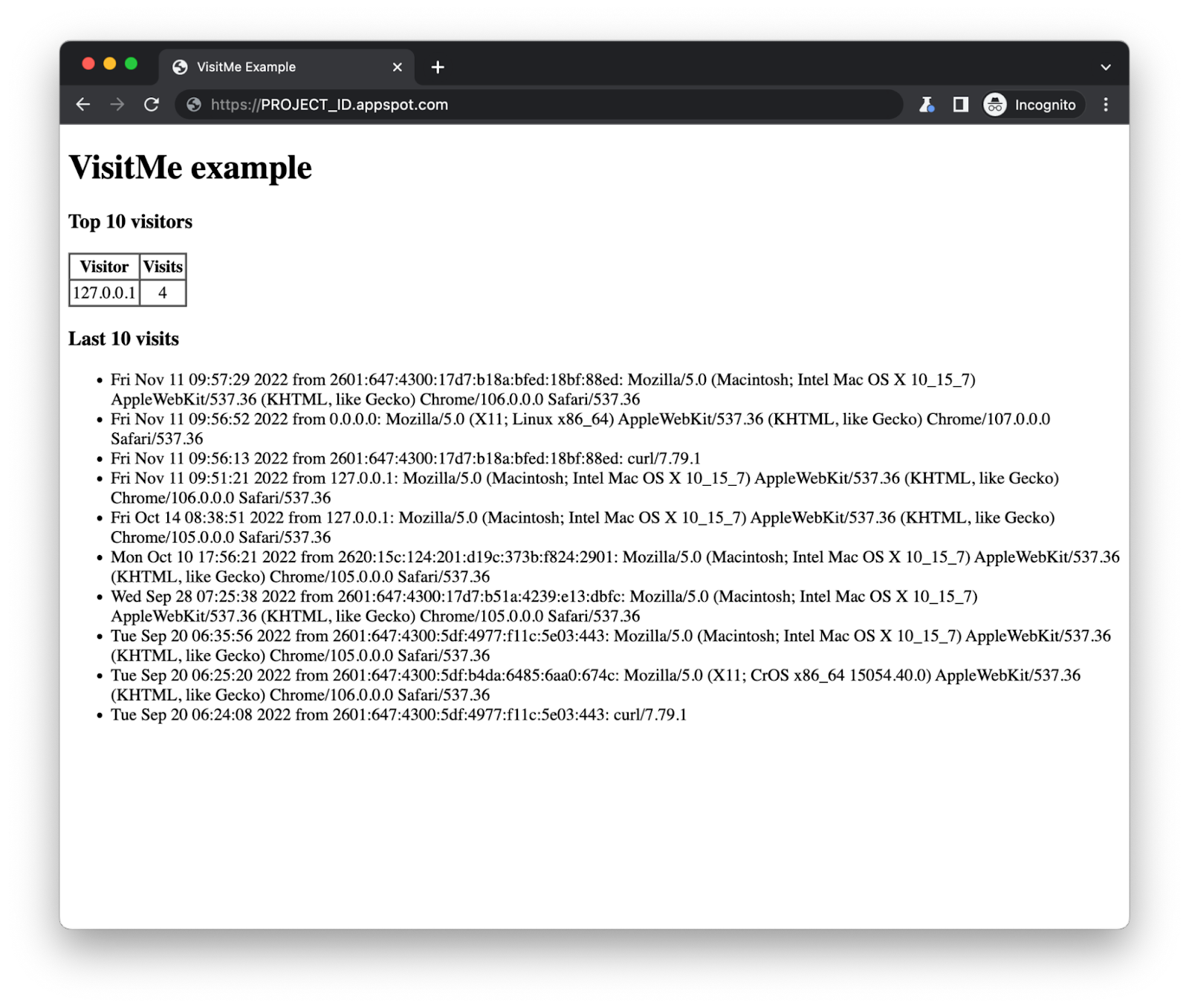
In addition to registering page visits, the sample app needs to be modified to track visitors. Visits are comprised of a timestamp and visitor information such as the IP address and user agent. We'll modify the app to use the IP address and track how many visits come from each address seen. The home page is modified to show the top visitors in addition to the most recent visits:
The sample app's updated home page tracking visits and visitors
When visits are registered, pull tasks are created to track the visitors. The pull tasks sit patiently in the queue until they are processed in aggregate periodically. Until that happens, the top visitors table stays static. These tasks can be processed in a number of ways: periodically by a cron or Cloud Scheduler job, a separate App Engine backend service, explicitly by a user (via browser or command-line HTTP request), event-triggered Cloud Function, etc. In the tutorial, we issue a curl request to the app's endpoint to process the enqueued tasks. When all tasks have completed, the table then reflects any changes to the current top visitors and their visit counts:
Processed pull tasks update the top visitors table
Below is some pseudocode representing the core part of the app that was altered to add Task Queue pull task usage, namely a new data model class, VisitorCount, to track visitor counts, enqueuing a (pull) task to update visitor counts when registering individual visits in store_visit(), and most importantly, a new function fetch_counts(), accessible via /log, to process enqueued tasks and update overall visitor counts. The bolded lines represent the new or altered code.
This "migration" is comprised of adding Task Queue pull task usage to support tracking visitor counts to the Module 1 baseline app and arrives at the finish line with the Module 18 app. To get hands-on experience doing it yourself, do the codelab by hand and follow along with the video. Then you'll be ready to upgrade to Cloud Pub/Sub should you choose to do so.
If you do want to move to Pub/Sub, see Module 19, including its codelab. All Serverless Migration Station content (codelabs, videos, and source code) are available at its open source repo. While we're initially focusing on Python users, the Cloud team is covering other runtimes soon, so stay tuned. Also check out other videos in the broader Serverless Expeditions series.
App Engine initially launched in 2008, providing a suite of bundled services making it convenient for applications to access a database (Datastore), caching service (Memcache), independent task execution (Task Queue), Google Sign-In authentication (Users), or large "blob" storage (Blobstore), or other companion services. However, apps leveraging those services can only run their apps on App Engine.
To increase app portability and help Google move towards its goal of having the most open cloud on the market, App Engine launched its 2nd-generation service in 2018, initially removing those legacy services. The newer platform allows developers to upgrade apps to the latest language runtimes, such as moving from Python 2 to 3 or Java 8 to 11 (and today, Java 17). One of the major drawbacks to the 1st-generation runtimes is that they're customized, proprietary, and restrictive in what you can use or can't.
Instead, the 2nd-generation platform uses open source runtimes, meaning ability to follow standard development practices, use common/known idioms, and have fewer restrictions of 3rd-party libraries, and obviating the need to copy or "vendor" them with your code. Unfortunately, to use these newer runtimes, migrating away from App Engine services were required because while you could upgrade language releases, there was no access to bundled services, breaking apps or requiring complete rewrites, making it a showstopper for many users.
Showing App Engine users how to use bundled services on Python 3
Performing the upgrade
Modernizing the typical Python 2 App Engine app looks something like this:
Migrate from the webapp2 framework (not available in Python 3)
Port from Python 2 to 3, preserve use of bundled services
Optional migration to Cloud standalone or similar 3rd-party services
The first step is to move to a standard Python web framework like Flask, Django, Pyramid, etc. Below is some pseudocode from Migration Module 1 demonstrating how to migrate from webapp2 to Flask:
Step 1: Port Python 2 sample app from webapp2 to Flask
The key changes are bolded in the above code snippets. Notice how the App Engine NDB code [the Visit class definition plus store_visit() and fetch_visits() functions] are unaffected by this web framework migration. The full webapp2 code sample can be found in the Module 0 repo folder while the completed migration to Flask sample is located in the Module 1 repo folder.
After your app has ported frameworks, you're free to upgrade to Python 3 while preserving access to the bundled services if your app uses any. Below is pseudocode demonstrating how to upgrade the same sample app to Python 3 as well as the code changes needed to continue to use App Engine NDB:
Step 2: Port sample app to Python 3, preserving use of NDB bundled service
The original app was designed to work under both Python 2 and 3 interpreters, so no language changes were required in this case. We added an import of the new App Engine SDK followed by the key update wrapping the WSGI object so the app can access the bundled services. As before, the key updates are bolded. Some updates to configuration are also required, and those are outlined in the documentation and the (Module 17) codelab.
The NDB code is also left untouched in this migration. Not all of the bundled services feature such a hands-free migration, and we hope to cover some of the more complex ones ahead in Module 22. Java, PHP, and Go users have it even better, requiring fewer or no code changes at all. The Python 2 Flask sample is located in the Module 1 repo folder, and the resulting Python 3 app can be found in the Module 1b repo folder.
The immediate benefit of step two is the ability to upgrade to a more current version of language runtime. This leaves the third step of migrating off the bundled services as optional, especially if you plan on staying on App Engine for the long-term.
Additional options
If you decide to migrate off the bundled services, you can do so on your own timeline. It should be a consideration should you ever want to move to modern serverless platforms such as Cloud Functions or Cloud Run, to lower-level platforms because you want more control, like GKE, our managed Kubernetes service, or Compute Engine VMs.
Step three is also where the rest of the Serverless Migration Station content may be useful:
*code samples and codelabs available;videos forthcoming
As far as moving to modern serverless platforms, if you want to break apart a large App Engine app into multiple microservices, consider Cloud Functions. If your organization has added containerization as part of your software development workflow, consider Cloud Run. It's suitable for apps if you're familiar with containers and Docker, but even if you or your team don't have that experience, Cloud Buildpacks can do the heavy lifting for you. Here are the relevant migration modules to explore:
Early App Engine users appreciate the convenience of the platform's bundled services, and after listening to user feedback, adding them back to 2nd-generation runtimes is another way we can help developers modernize their apps. Whether upgrading to newer language runtimes to stay on App Engine and continue to use its bundled services, migrating to Cloud standalone products, or shifting to other serverless platforms, the Google Cloud team aims to provide the tools to help streamline your modernization efforts.
All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, the Cloud team is working on covering other language runtimes, so stay tuned. Today's video features a special guest to provide a teaser of what to expect for Java. For additional video content, check out the broader Serverless Expeditions series.
The most recent Serverless Migration Station video demonstrated how to add use of the App Engine's Blobstore service to a sample Python 2 App Engine app, kicking off the first of a 2-part series on migrating away from Blobstore. In today's Module 16 video, we complete this journey, arriving at Cloud Storage. Moving away from proprietary App Engine services like Blobstore makes apps more portable, giving them enough flexibility to:
Shift across to other serverless platforms, like Cloud Functions or Cloud Run (with or without Docker), or
Move to VM-based services like GKE or Compute Engine, or to other compute platforms
Showing App Engine users how to migrate to Cloud Storage
As described previously, a Blobstore for Python 2 dependency on webapp made the Module 15 content more straightforward to implement if it was still using webapp2. To completely modernize this app here in Module 16, the following migrations should be carried out:
Migrate from webapp2 (and webapp) to Flask
Migrate from App Engine NDB to Cloud NDB
Migrate from App Engine Blobstore to Cloud Storage
Migrate from Python 2 to Python (2 and) 3
Performing the migrations
Prior to modifying the application code, a variety of configuration updates need to be made. Updates applying only to Python 2 feature a "Py2" designation while those migrating to Python 3 will see "Py3" annotations.
Remove the built-in Jinja2 library from app.yaml—Jinja2 already comes with Flask, so remove use of the older built-in version which may possibly conflict with the contemporary Flask version you're using. (Py2)
Use of Cloud client libraries (such as those for Cloud NDB and Cloud Storage) require a pair of built-in libraries, grpcio and setuptools, so add those to app.yaml (Py2)
Remove everything in app.yaml except for a valid runtime (Py3)
Add Cloud NDB and Cloud Storage client libraries to requirements.txt (Py2 & Py3)
Create an appengine_config.py supporting both built-in (those in app.yaml) and non built-in (those in requirements.txt) libraries used (Py2)
The Module 15 app already migrated away from webapp2's (Django) templating system to Jinja2. This is useful when migrating to Flask because Jinja2 is Flask's default template system. Switching from App Engine NDB to Cloud NDB is fairly straightforward as the latter was designed to be mostly compatible with the original. The only change visible in this sample app is to move Datastore calls into Python with blocks.
The most significant changes occur when moving the upload and download handlers from webapp to Cloud Storage. The video and corresponding codelab go more in-depth into the necessary changes, but in summary, these are the updates required in the main application:
webapp2 is replaced by Flask. Instead of using the older built-in version of Jinja2, use the version that comes with Flask.
App Engine Blobstore and NDB are replaced by Cloud NDB and Cloud Storage, respectively.
The webapp Blobstore handler functionality is replaced by a combination of the io standard library module plus components from Flask and Werkzeug. Furthermore, the handler classes and methods are replaced by Flask functions.
The main handler class and corresponding GET and POST methods are all replaced by a single Flask function.
The results
With all the changes implemented, the original Module 15 app still operates identically in Module 16, starting with a form requesting a visit artifact followed by the most recents visits page:
The sample app's artifact prompt page
The sample app's most recent visits page.
The only difference is that four migrations have been completed where all of the "infrastructure" is now taken care of by non-App Engine legacy services. Furthermore, the Module 16 app could be either a Python 2 or 3 app. As far as the end-user is concerned, "nothing happened."
Migrating sample app from App Engine Blobstore to Cloud Storage
Wrap-up
Module 16 featured four different migrations, modernizing the Module 15 app from using App Engine legacy services like NDB and Blobstore to Cloud NDB and Cloud Storage, respectively. While we recommend users move to the latest offerings from Google Cloud, migrating from Blobstore to Cloud Storage isn't required, and should you opt to do so, can do it on your own timeline. In addition to today's video, be sure to check out the Module 16 codelab which leads you step-by-step through the migrations discussed.
If you're using other App Engine legacy services be sure to check out the other Migration Modules in this series. All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, the Cloud team is working on covering other language runtimes, so stay tuned. For additional video content, check out our broader Serverless Expeditions series.
The previous Module 12 episode of the Serverless Migration Station video series demonstrated how to add App Engine Memcache usage to an existing app that has transitioned from the webapp2 framework to Flask. Today's Module 13 episode continues its modernization by demonstrating how to migrate that app from Memcache to Cloud Memorystore. Moving from legacy APIs to standalone Cloud services makes apps more portable and provides an easier transition from Python 2 to 3. It also makes it possible to shift to other Cloud compute platforms should that be desired or advantageous. Developers benefit from upgrading to modern language releases and gain added flexibility in application-hosting options.
While App Engine Memcache provides a basic, low-overhead, serverless caching service, Cloud Memorystore "takes it to the next level" as a standalone product. Rather than a proprietary caching engine, Cloud Memorystore gives users the option to select from a pair of open source engines, Memcached or Redis, each of which provides additional features unavailable from App Engine Memcache. Cloud Memorystore is typically more cost efficient at-scale, offers high availability, provides automatic backups, etc. On top of this, one Memorystore instance can be used across many applications as well as incorporates improvements to memory handling, configuration tuning, etc., gained from experience managing a huge fleet of Redis and Memcached instances.
While Memcached is more similar to Memcache in usage/features, Redis has a much richer set of data structures that enable powerful application functionality if utilized. Redis has also been recognized as the most loved database by developers in StackOverflow's annual developers survey, and it's a great skill to pick up. For these reasons, we chose Redis as the caching engine for our sample app. However, if your apps' usage of App Engine Memcache is deeper or more complex, a migration to Cloud Memorystore for Memcached may be a better option as a closer analog to Memcache.
Migrating to Cloud Memorystore for Redis featured video
Performing the migration
The sample application registers individual web page "visits," storing visitor information such as IP address and user agent. In the original app, the most recent visits are cached into Memcache for an hour and used for display if the same user continuously refreshes their browser during this period; caching is a one way to counter this abuse. New visitors or cache expiration results new visits as well as updating the cache with the most recent visits. Such functionality must be preserved when migrating to Cloud Memorystore for Redis.
Below is pseudocode representing the core part of the app that saves new visits and queries for the most recent visits. Before, you can see how the most recent visits are cached into Memcache. After completing the migration, the underlying caching infrastructure has been swapped out in favor of Memorystore (via language-specific Redis client libraries). In this migration, we chose Redis version 5.0, and we recommend the latest versions, 5.0 and 6.x at the time of this writing, as the newest releases feature additional performance benefits, fixes to improve availability, and so on. In the code snippets below, notice how the calls between both caching systems are nearly identical. The bolded lines represent the migration-affected code managing the cached data.
Switching from App Engine Memcache to Cloud Memorystore for Redis
Wrap-up
The migration covered begins with the Module 12 sample app ("START"). Migrating the caching system to Cloud Memorystore and other requisite updates results in the Module 13 sample app ("FINISH") along with an optional port to Python 3. To practice this migration on your own to help prepare for your own migrations, follow the codelab to do it by-hand while following along in the video.
While the code migration demonstrated seems straightforward, the most critical change is that Cloud Memorystore requires dedicated server instances. For this reason, a Serverless VPC connector is also needed to connect your App Engine app to those Memorystore instances, requiring more dedicated servers. Furthermore, neither Cloud Memorystore nor Cloud VPC are free services, and neither has an "Always free" tier quota. Before moving forward this migration, check the pricing documentation for Cloud Memorystore for Redis and Serverless VPC access to determine cost considerations before making a commitment.
One key development that may affect your decision: In Fall 2021, the App Engine team extended support of many of the legacy bundled services like Memcache to next-generation runtimes, meaning you are no longer required to migrate to Cloud Memorystore when porting your app to Python 3. You can continue using Memcache even when upgrading to 3.x so long as you retrofit your code to access bundled services from next-generation runtimes.
A move to Cloud Memorystore and today's migration techniques will be here if and when you decide this is the direction you want to take for your App Engine apps. All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, we plan to cover other language runtimes, so stay tuned. For additional video content, check out our broader Serverless Expeditions series.
In our ongoing Serverless Migration Station series aimed at helping developers modernize their serverless applications, one of the key objectives for Google App Engine developers is to upgrade to the latest language runtimes, such as from Python 2 to 3 or Java 8 to 17. Another objective is to help developers learn how to move away from App Engine legacy APIs (now called "bundled services") to Cloud standalone equivalent services. Once this has been accomplished, apps are much more portable, making them flexible enough to:
In today's Module 12 video, we're going to start our journey by implementing App Engine's Memcache bundled service, setting us up for our next move to a more complete in-cloud caching service, Cloud Memorystore. Most apps typically rely on some database, and in many situations, they can benefit from a caching layer to reduce the number of queries and improve response latency. In the video, we add use of Memcache to a Python 2 app that has already migrated web frameworks from webapp2 to Flask, providing greater portability and execution options. More importantly, it paves the way for an eventual 3.x upgrade because the Python 3 App Engine runtime does not support webapp2. We'll cover both the 3.x and Cloud Memorystore ports next in Module 13.
Got an older app needing an update? We can help with that.
Adding use of Memcache
The sample application registers individual web page "visits," storing visitor information such as the IP address and user agent. In the original app, these values are stored immediately, and then the most recent visits are queried to display in the browser. If the same user continuously refreshes their browser, each refresh constitutes a new visit. To discourage this type of abuse, we cache the same user's visit for an hour, returning the same cached list of most recent visits unless a new visitor arrives or an hour has elapsed since their initial visit.
Below is pseudocode representing the core part of the app that saves new visits and queries for the most recent visits. Before, you can see how each visit is registered. After the update, the app attempts to fetch these visits from the cache. If cached results are available and "fresh" (within the hour), they're used immediately, but if cache is empty, or a new visitor arrives, the current visit is stored as before, and this latest collection of visits is cached for an hour. The bolded lines represent the new code that manages the cached data.
Adding App Engine Memcache usage to sample app
Wrap-up
Today's "migration" began with the Module 1 sample app. We added a Memcache-based caching layer and arrived at the finish line with the Module 12 sample app. To practice this on your own, follow the codelab doing it by-hand while following the video. The Module 12 app will then be ready to upgrade to Cloud Memorystore should you choose to do so.
If you do want to move to Cloud Memorystore, stay tuned for the Module 13 video or try its codelab to get a sneak peek. All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, we hope to one day cover other language runtimes, so stay tuned. For additional video content, check out our broader Serverless Expeditions series.









![Adding App Engine Task Queue pull task usage to sample app showing 'Before'[Module 1] on the left and 'After' [Module 18] with altered code on the right](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjRVGVYc9fl4xI9xUpOUaAwXup8p-wUf5nbKllG7OYJSVAYSPVCGw7DU8EbMoTE3kBBgVZiICFvsn_7fHP2oymA_1ASKBrAE2Qt8PzCGAAkK7_WnyvAIEMKQUrxP8FSz3tGykLrlu9nyluN5vgEPrWZrBqIAalCoRmos169g9m9NHz3cGqQyych9eEG/s1600/Screen%20Shot%202022-11-29%20at%205.19.28%20PM.png)