Posted by Jagan Sankaranarayanan, Senior Staff Software Engineer, and Indrajit Roy, Head of Napa Product, Google
Google Ads infrastructure runs on an internal data warehouse called Napa. Billions of reporting queries, which power critical dashboards used by advertising clients to measure campaign performance, run on tables stored in Napa. These tables contain records of ads performance that are keyed using particular customers and the campaign identifiers with which they are associated. Keys are tokens that are used both to associate an ads record with a particular client and campaign (e.g., customer_id, campaign_id) and for efficient retrieval. A record contains dozens of keys, so clients use reporting queries to specify keys needed to filter the data to understand ads performance (e.g., by region, device and metrics such as clicks, etc.). What makes this problem challenging is that the data is skewed since queries require varying levels of effort to be answered and have stringent latency expectations. Specifically, some queries require the use of millions of records while others are answered with just a few.
To this end, in “Progressive Partitioning for Parallelized Query Execution in Napa”, presented at VLDB 2023, we describe how the Napa data warehouse determines the amount of machine resources needed to answer reporting queries while meeting strict latency targets. We introduce a new progressive query partitioning algorithm that can parallelize query execution in the presence of complex data skews to perform consistently well in a matter of a few milliseconds. Finally, we demonstrate how Napa allows Google Ads infrastructure to serve billions of queries every day.
Query processing challenges
When a client inputs a reporting query, the main challenge is to determine how to parallelize the query effectively. Napa’s parallelization technique breaks up the query into even sections that are equally distributed across available machines, which then process these in parallel to significantly reduce query latency. This is done by estimating the number of records associated with a specified key, and assigning more or less equal amounts of work to machines. However, this estimation is not perfect since reviewing all records would require the same effort as answering the query. A machine that processes significantly more than others would result in run-time skews and poor performance. Each machine also needs to have sufficient work since needless parallelism leads to underutilized infrastructure. Finally, parallelization has to be a per query decision that must be executed near-perfectly billions of times, or the query may miss the stringent latency requirements.
The reporting query example below extracts the records denoted by keys (i.e., customer_id and campaign_id) and then computes an aggregate (i.e., SUM(cost)) from an advertiser table. In this example the number of records is too large to process on a single machine, so Napa needs to use a subsequent key (e.g., adgroup_id) to further break up the collection of records so that equal distribution of work is achieved. It is important to note that at petabyte scale, the size of the data statistics needed for parallelization may be several terabytes. This means that the problem is not just about collecting enormous amounts of metadata, but also how it is managed.
SELECT customer_id, campaign_id, SUM(cost)
FROM advertiser_table
WHERE customer_id in (1, 7, ..., x )
AND campaign_id in (10, 20, ..., y)
GROUP BY customer_id, campaign_id;
This reporting query example extracts records denoted by keys (i.e., customer_id and campaign_id) and then computes an aggregate (i.e., SUM(cost)) from an advertiser table. The query effort is determined by the keys' included in the query. Keys belonging to clients with larger campaigns may touch millions of records since the data volume directly correlates with the size of the ads campaign. This disparity of matching records based on keys reflects the skewness in data, which makes query processing a challenging problem.
An effective solution minimizes the amount of metadata needed, focuses effort primarily on the skewed part of the key space to partition data efficiently, and works well within the allotted time. For example, if the query latency is a few hundred milliseconds, partitioning should take no longer than tens of milliseconds. Finally, a parallelization process should determine when it's reached the best possible partitioning that considers query latency expectations. To this end, we have developed a progressive partitioning algorithm that we describe later in this article.
Managing the data deluge
Tables in Napa are constantly updated, so we use log-structured merge forests (LSM tree) to organize the deluge of table updates. LSM is a forest of sorted data that is temporally organized with a B-tree index to support efficient key lookup queries. B-trees store summary information of the sub-trees in a hierarchical manner. Each B-tree node records the number of entries present in each subtree, which aids in the parallelization of queries. LSM allows us to decouple the process of updating the tables from the mechanics of query serving in the sense that live queries go against a different version of the data, which is atomically updated once the next batch of ingest (called delta) has been fully prepared for querying.
The partitioning problem
The data partitioning problem in our context is that we have a massively large table that is represented as an LSM tree. In the figure below, Delta 1 and 2 each have their own B-tree, and together represent 70 records. Napa breaks the records into two pieces, and assigns each piece to a different machine. The problem becomes a partitioning problem of a forest of trees and requires a tree-traversal algorithm that can quickly split the trees into two equal parts.
To avoid visiting all the nodes of the tree, we introduce the concept of “good enough” partitioning. As we begin cutting and partitioning the tree into two parts, we maintain an estimate of how bad our current answer would be if we terminated the partitioning process at that instant. This is the yardstick of how close we are to the answer and is represented below by a total error margin of 40 (at this point of execution, the two pieces are expected to be between 15 and 35 records in size, the uncertainty adds up to 40). Each subsequent traversal step reduces the error estimate, and if the two pieces are approximately equal, it stops the partitioning process. This process continues until the desired error margin is reached, at which time we are guaranteed that the two pieces are more or less equal.
Progressive partitioning algorithm
Progressive partitioning encapsulates the notion of “good enough” in that it makes a series of moves to reduce the error estimate. The input is a set of B-trees and the goal is to cut the trees into pieces of more or less equal size. The algorithm traverses one of the trees (“drill down'' in the figure) which results in a reduction of the error estimate. The algorithm is guided by statistics that are stored with each node of the tree so that it makes an informed set of moves at each step. The challenge here is to decide how to direct effort in the best possible way so that the error bound reduces quickly in the fewest possible steps. Progressive partitioning is conducive for our use-case since the longer the algorithm runs, the more equal the pieces become. It also means that if the algorithm is stopped at any point, one still gets good partitioning, where the quality corresponds to the time spent.
Prior work in this space uses a sampled table to drive the partitioning process, while the Napa approach uses a B-tree. As mentioned earlier, even just a sample from a petabyte table can be massive. A tree-based partitioning method can achieve partitioning much more efficiently than a sample-based approach, which does not use a tree organization of the sampled records. We compare progressive partitioning with an alternative approach, where sampling of the table at various resolutions (e.g., 1 record sample every 250 MB and so on) aids the partitioning of the query. Experimental results show the relative speedup from progressive partitioning for queries requiring varying numbers of machines. These results demonstrate that progressive partitioning is much faster than existing approaches and the speedup increases as the size of the query increases.
Conclusion
Napa's progressive partitioning algorithm efficiently optimizes database queries, enabling Google Ads to serve client reporting queries billions of times each day. We note that tree traversal is a common technique that students in introductory computer science courses use, yet it also serves a critical use-case at Google. We hope that this article will inspire our readers, as it demonstrates how simple techniques and carefully designed data structures can be remarkably potent if used well. Check out the paper and a recent talk describing Napa to learn more.
Acknowledgements
This blog post describes a collaborative effort between Junichi Tatemura, Tao Zou, Jagan Sankaranarayanan, Yanlai Huang, Jim Chen, Yupu Zhang, Kevin Lai, Hao Zhang, Gokul Nath Babu Manoharan, Goetz Graefe, Divyakant Agrawal, Brad Adelberg, Shilpa Kolhar and Indrajit Roy.
Posted by Matt Barnes, Software Engineer, Google Research
Routing in Google Maps remains one of our most helpful and frequently used features. Determining the best route from A to B requires making complex trade-offs between factors including the estimated time of arrival (ETA), tolls, directness, surface conditions (e.g., paved, unpaved roads), and user preferences, which vary across transportation mode and local geography. Often, the most natural visibility we have into travelers' preferences is by analyzing real-world travel patterns.
Learning preferences from observed sequential decision making behavior is a classic application of inverse reinforcement learning (IRL). Given a Markov decision process (MDP) — a formalization of the road network — and a set of demonstration trajectories (the traveled routes), the goal of IRL is to recover the users' latent reward function. Although past research has created increasingly general IRL solutions, these have not been successfully scaled to world-sized MDPs. Scaling IRL algorithms is challenging because they typically require solving an RL subroutine at every update step. At first glance, even attempting to fit a world-scale MDP into memory to compute a single gradient step appears infeasible due to the large number of road segments and limited high bandwidth memory. When applying IRL to routing, one needs to consider all reasonable routes between each demonstration's origin and destination. This implies that any attempt to break the world-scale MDP into smaller components cannot consider components smaller than a metropolitan area.
To this end, in "Massively Scalable Inverse Reinforcement Learning in Google Maps", we share the result of a multi-year collaboration among Google Research, Maps, and Google DeepMind to surpass this IRL scalability limitation. We revisit classic algorithms in this space, and introduce advances in graph compression and parallelization, along with a new IRL algorithm called Receding Horizon Inverse Planning (RHIP) that provides fine-grained control over performance trade-offs. The final RHIP policy achieves a 16–24% relative improvement in global route match rate, i.e., the percentage of de-identified traveled routes that exactly match the suggested route in Google Maps. To the best of our knowledge, this represents the largest instance of IRL in a real world setting to date.
Google Maps improvements in route match rate relative to the existing baseline, when using the RHIP inverse reinforcement learning policy.
The benefits of IRL
A subtle but crucial detail about the routing problem is that it is goal conditioned, meaning that every destination state induces a slightly different MDP (specifically, the destination is a terminal, zero-reward state). IRL approaches are well suited for these types of problems because the learned reward function transfers across MDPs, and only the destination state is modified. This is in contrast to approaches that directly learn a policy, which typically require an extra factor of S parameters, where S is the number of MDP states.
Once the reward function is learned via IRL, we take advantage of a powerful inference-time trick. First, we evaluate the entire graph's rewards once in an offline batch setting. This computation is performed entirely on servers without access to individual trips, and operates only over batches of road segments in the graph. Then, we save the results to an in-memory database and use a fast online graph search algorithm to find the highest reward path for routing requests between any origin and destination. This circumvents the need to perform online inference of a deeply parameterized model or policy, and vastly improves serving costs and latency.
Reward model deployment using batch inference and fast online planners.
Receding Horizon Inverse Planning
To scale IRL to the world MDP, we compress the graph and shard the global MDP using a sparse Mixture of Experts (MoE) based on geographic regions. We then apply classic IRL algorithms to solve the local MDPs, estimate the loss, and send gradients back to the MoE. The worldwide reward graph is computed by decompressing the final MoE reward model. To provide more control over performance characteristics, we introduce a new generalized IRL algorithm called Receding Horizon Inverse Planning (RHIP).
IRL reward model training using MoE parallelization, graph compression, and RHIP.
RHIP is inspired by people’s tendency to perform extensive local planning ("What am I doing for the next hour?") and approximate long-term planning ("What will my life look like in 5 years?"). To take advantage of this insight, RHIP uses robust yet expensive stochastic policies in the local region surrounding the demonstration path, and switches to cheaper deterministic planners beyond some horizon. Adjusting the horizon H allows controlling computational costs, and often allows the discovery of the performance sweet spot. Interestingly, RHIP generalizes many classic IRL algorithms and provides the novel insight that they can be viewed along a stochastic vs. deterministic spectrum (specifically, for H=∞ it reduces to MaxEnt, for H=1 it reduces to BIRL, and for H=0 it reduces to MMP).
Given a demonstration from so to sd, (1) RHIP follows a robust yet expensive stochastic policy in the local region surrounding the demonstration (blue region). (2) Beyond some horizon H, RHIP switches to following a cheaper deterministic planner (red lines). Adjusting the horizon enables fine-grained control over performance and computational costs.
Routing wins
The RHIP policy provides a 15.9% and 24.1% lift in global route match rate for driving and two-wheelers (e.g., scooters, motorcycles, mopeds) relative to the well-tuned Maps baseline, respectively. We're especially excited about the benefits to more sustainable transportation modes, where factors beyond journey time play a substantial role. By tuning RHIP's horizon H, we're able to achieve a policy that is both more accurate than all other IRL policies and 70% faster than MaxEnt.
Our 360M parameter reward model provides intuitive wins for Google Maps users in live A/B experiments. Examining road segments with a large absolute difference between the learned rewards and the baseline rewards can help improve certain Google Maps routes. For example:
Nottingham, UK. The preferred route (blue) was previously marked as private property due to the presence of a large gate, which indicated to our systems that the road may be closed at times and would not be ideal for drivers. As a result, Google Maps routed drivers through a longer, alternate detour instead (red). However, because real-world driving patterns showed that users regularly take the preferred route without an issue (as the gate is almost never closed), IRL now learns to route drivers along the preferred route by placing a large positive reward on this road segment.
Conclusion
Increasing performance via increased scale – both in terms of dataset size and model complexity – has proven to be a persistent trend in machine learning. Similar gains for inverse reinforcement learning problems have historically remained elusive, largely due to the challenges with handling practically sized MDPs. By introducing scalability advancements to classic IRL algorithms, we're now able to train reward models on problems with hundreds of millions of states, demonstration trajectories, and model parameters, respectively. To the best of our knowledge, this is the largest instance of IRL in a real-world setting to date. See the paper to learn more about this work.
Acknowledgements
This work is a collaboration across multiple teams at Google. Contributors to the project include Matthew Abueg, Oliver Lange, Matt Deeds, Jason Trader, Denali Molitor, Markus Wulfmeier, Shawn O'Banion, Ryan Epp, Renaud Hartert, Rui Song, Thomas Sharp, Rémi Robert, Zoltan Szego, Beth Luan, Brit Larabee and Agnieszka Madurska.
We’d also like to extend our thanks to Arno Eigenwillig, Jacob Moorman, Jonathan Spencer, Remi Munos, Michael Bloesch and Arun Ahuja for valuable discussions and suggestions.
Posted by Greg Blascovich and Eric Gomez, User Researchers, Google
As companies settle into a new normal of hybrid and distributed work, remote communication technology remains critical for connecting and collaborating with colleagues. While this technology has improved, the core user experience often falls short: conversation can feel stilted, attention can be difficult to maintain, and usage can be fatiguing.
Project Starline renders people at natural scale on a 3D display and enables natural eye contact.
At Google I/O 2021 we announced Project Starline, a technology project that combines advances in hardware and software to create a remote communication experience that feels like you’re together, even when you’re thousands of miles apart. This perception of co-presence is created by representing users in 3D at natural scale, enabling eye contact, and providing spatially accurate audio. But to what extent do these technological innovations translate to meaningful, observable improvement in user value compared to traditional video conferencing?
In this blog we share results from a number of studies across a variety of methodologies, finding converging evidence that Project Starline outperforms traditional video conferencing in terms of conversation dynamics, video meeting fatigue, and attentiveness. Some of these results were previously published while others we are sharing for the first time as preliminary findings.
Improved conversation dynamics
In our qualitative studies, users often describe conversations in Project Starline as “more natural.” However, when asked to elaborate, many have difficulty articulating this concept in a way that fully captures their experience. Because human communication relies partly on unconscious processes like nonverbal behavior, people might have a hard time reflecting on these processes that are potentially impacted by experiencing a novel technology. To address this challenge, we conducted a series of behavioral lab experiments to shed light on what “more natural” might mean for Project Starline. These experiments employed within-subjects designs in which participants experienced multiple conditions (e.g., meeting in Project Starline vs. traditional videoconferencing) in randomized order. This allowed us to control for between-subject differences by comparing how the same individual responded to a variety of conditions, thus increasing statistical power and reducing the sample size necessary to detect statistical differences (sample sizes in our behavioral experiments range from ~ 20 to 30).
In one study, preliminary data suggest Project Starline improves conversation dynamics by increasing rates of turn-taking. We recruited pairs of participants who had never met each other to have unstructured conversations in both Project Starline and traditional video conferencing. We analyzed the audio from each conversation and found that Project Starline facilitated significantly more dynamic "back and forth" conversations compared to traditional video conferencing. Specifically, participants averaged about 2-3 more speaker hand-offs in Project Starline conversations compared to those in traditional video conferencing across a two minute subsample of their conversation (a uniform selection at the end of each conversation to help standardize for interpersonal rapport). Participants also rated their Starline conversations as significantly more natural (“smooth,” “easy,” “not awkward”), higher in quality, and easier to recognize when it was their turn to speak compared to conversations using traditional video conferencing.
In another study, participants had conversations with a confederate in both Project Starline and traditional video conferencing. We recorded these conversations to analyze select nonverbal behaviors. In Project Starline, participants were more animated, using significantly more hand gestures (+43%), head nods (+26%), and eyebrow movements (+49%). Participants also reported a significantly better ability to perceive and convey nonverbal cues in Project Starline than in traditional video conferencing. Together with the turn-taking results, these data help explain why conversations in Project Starline may feel more natural.
We recorded participants to quantify their nonverbal behaviors and found that they were more animated in Project Starline (left) compared to traditional video conferencing (right).
Reduced video meeting fatigue
A well-documented challenge of video conferencing, especially within the workplace, is video meeting fatigue. The causes of video meeting fatigue are complex, but one possibility is that video communication is cognitively taxing because it becomes more difficult to convey and interpret nonverbal behavior. Considering previous findings that suggested Project Starline might improve nonverbal communication, we examined whether video meeting fatigue might also be improved (i.e., reduced) compared to traditional video conferencing.
Our study found preliminary evidence that Project Starline indeed reduces video meeting fatigue. Participants held 30-minute mock meetings in Project Starline and traditional video conferencing. Meeting content was standardized across participants using an exercise adapted from academic literature that emulates key elements of a work meeting, such as brainstorming and persuasion. We then measured video meeting fatigue via the Zoom Exhaustion and Fatigue (ZEF) Scale. Additionally, we measured participants' reaction times on a complex cognitive task originally used in cognitive psychology. We repurposed this task as a proxy for video meeting fatigue based on the assumption that more fatigue would lead to slower reaction times. Participants reported significantly less video meeting fatigue on the ZEF Scale (-31%) and had faster reaction times (-12%) on the cognitive task after using Project Starline compared to traditional video conferencing.
Increased attentiveness
Another challenge with video conferencing is focusing attention on the meeting at hand, rather than on other browser windows or secondary devices.
In our earlier study on nonverbal behavior, we included an exploratory information-retention task. We asked participants to write as much as they could remember about each conversation (one in Project Starline, and one in traditional video conferencing). We found that participants wrote 28% more in this task (by character count) after their conversation in Project Starline. This could be because they paid closer attention when in Project Starline, or possibly that they found conversations in Project Starline to be more engaging.
To explore the concept of attentiveness further, we conducted a study in which participants wore eye-tracking glasses. This allowed us to calculate the percentage of time participants spent focusing on their conversation partner’s face, an important source of social information in human interaction. Participants had a conversation with a confederate in Project Starline, traditional video conferencing, and in person. We found that participants spent a significantly higher proportion of time looking at their conversation partner's face in Project Starline (+14%) than they did in traditional video conferencing. In fact, visual attentiveness in Project Starline mirrored that of the in-person condition: participants spent roughly the same proportion of time focusing on their meeting partner’s face in the Project Starline and in-person conditions.
The use of eye-tracking glasses and facial detection software allowed us to quantify participants' gaze patterns. The video above illustrates how a hypothetical participant's eye tracking data (red dot) correspond to their meeting partner's face (white box).
User value in real meetings
The lab-based, experimental approach used in the studies above allows for causal inference while minimizing confounding variables. However, one limitation of these studies is that they are low in external validity — that is, they took place in a lab environment, and the extent to which their results extend to the real world is unclear. Thus, we studied actual users within Google who used Project Starline for their day-to-day work meetings and collected their feedback.
An internal pilot revealed that users derive meaningful value from using Project Starline. We used post-meeting surveys to capture immediate feedback on individual meetings, longer monthly surveys to capture holistic feedback on the experience, and conducted in-depth qualitative interviews with a subset of users. We evaluated Project Starline on concepts such as presence, nonverbal behavior, attentiveness, and personal connection. We found strong evidence that Project Starline delivered across these four metrics, with over 87% of participants expressing that their meetings in Project Starline were better than their previous experiences with traditional video conferencing.
Conclusion
Together, these findings offer a compelling case for Project Starline's value to users: improved conversation dynamics, reduced video meeting fatigue, and increased attentiveness. Participants expressed that Project Starline was a significant improvement over traditional video conferencing in highly controlled lab experiments, as well as when they used Project Starline for their actual work meetings. We’re excited to see these findings converge across multiple methodologies (surveys, qualitative interviews, experiments) and measurements (self-report, behavioral, qualitative), and we’re eager to continue exploring the implications of Project Starline on human interaction.
Acknowledgments
We’d like to thank Melba Tellez, Eric Baczuk, Jinghua Zhang, Matthew DuVall, and Travis Miller for contributing to visual assets and illustrations.
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team
In recent years, language models (LMs) have become more prominent in natural language processing (NLP) research and are also becoming increasingly impactful in practice. Scaling up LMs has been shown to improve performance across a range of NLP tasks. For instance, scaling up language models can improve perplexity across seven orders of magnitude of model sizes, and new abilities such as multi-step reasoning have been observed to arise as a result of model scale. However, one of the challenges of continued scaling is that training new, larger models requires great amounts of computational resources. Moreover, new models are often trained from scratch and do not leverage the weights from previously existing models.
In this blog post, we explore two complementary methods for improving existing language models by a large margin without using massive computational resources. First, in “Transcending Scaling Laws with 0.1% Extra Compute”, we introduce UL2R, which is a lightweight second stage of pre-training that uses a mixture-of-denoisers objective. UL2R improves performance across a range of tasks and even unlocks emergent performance on tasks that previously had close to random performance. Second, in “Scaling Instruction-Finetuned Language Models”, we explore fine-tuning a language model on a collection of datasets phrased as instructions, a process we call “Flan”. This approach not only boosts performance, but also improves the usability of the language model to user inputs without engineering of prompts. Finally, we show that Flan and UL2R can be combined as complementary techniques in a model called Flan-U-PaLM 540B, which outperforms the unadapted PaLM 540B model by 10% across a suite of challenging evaluation benchmarks.
UL2R Training
Traditionally, most language models are pre-trained on either a causal language modeling objective that enables the model to predict the next word in a sequence (e.g., GPT-3 or PaLM) or a denoising objective, where the model learns to recover the original sentence from a corrupted sequence of words, (e.g., T5). Although there are some tradeoffs in language modeling objectives in that causal LMs are better at long-form generation and LMs trained on a denoising objective are better for fine-tuning, in prior work we demonstrated that a mixture-of-denoisers objective that includes both objectives results in better performance on both scenarios.
However, pre-training a large language model on a different objective from scratch can be computationally prohibitive. Hence, we propose UL2 Repair (UL2R), an additional stage of continued pre-training with the UL2 objective that only requires a relatively small amount of compute. We apply UL2R to PaLM and call the resulting new language model U-PaLM.
In empirical evaluations, we found that scaling curves improve substantially with only a small amount of UL2 training. For instance, we show that by using UL2R on the intermediate checkpoint of PaLM 540B, we reach the performance of the final PaLM 540B checkpoint while using 2x less compute (or a difference of 4.4 million TPUv4 hours). Naturally, applying UL2R to the final PaLM 540B checkpoint also leads to substantial improvements, as described in the paper.
Compute versus model performance of PaLM 540B and U-PaLM 540B on 26 NLP benchmarks (listed in Table 8 in the paper). U-PaLM 540B continues training PaLM for a very small amount of compute but provides a substantial gain in performance.
Another benefit that we observed from using UL2R is that on some tasks, performance is much better than models trained purely on the causal language modeling objective. For instance, there are many BIG-Bench tasks that have been described as “emergent abilities”, i.e., abilities that can only be observed in sufficiently large language models. Although the way that emergent abilities are most commonly found is by scaling up the size of the LM, we found that UL2R can actually elicit emergent abilities without increasing the scale of the LM.
For instance, in the Navigate task from BIG-Bench, which measures the model’s ability to perform state tracking, all models except U-PaLM with less than 1023 training FLOPs achieve approximately random performance. U-PaLM performance is more than 10 points above that. Another example of this is the Snarks task from BIG-Bench, which measures the model’s ability to detect sarcasm. Again, whereas all models less than 1024 training FLOPs achieve approximately random performance, U-PaLM achieves well above even for the 8B and 62B models.
For two abilities from BIG-Bench that demonstrate emergent task performance, U-PaLM achieves emergence at a smaller model size due to its use of the UL2R objective.
Instruction Fine-Tuning
In our second paper, we explore instruction fine-tuning, which involves fine-tuning LMs on a collection of NLP datasets phrased as instructions. In prior work, we applied instruction fine-tuning to a 137B-parameter model on 62 NLP tasks, such as answering a trivia question, classifying the sentiment of a movie, or translating a sentence to Spanish.
In this work we fine-tune a 540B parameter language model on more than 1.8K tasks. Moreover, whereas previous efforts only fine-tuned a LM with few-shot exemplars (e.g., MetaICL) or zero-shot without exemplars (e.g., FLAN, T0), we fine-tune on a combination of both. We also include chain of thought fine-tuning data, which enables the model to perform multi-step reasoning. We call our improved methodology “Flan”, for fine-tuning language models. Notably, even with fine-tuning on 1.8K tasks, Flan only uses a small portion of compute compared to pre-training (e.g., for PaLM 540B, Flan only requires 0.2% of the pre-training compute).
We fine-tune language models on 1.8K tasks phrased as instructions, and evaluate them on unseen tasks, which are not included in fine-tuning. We fine-tune both with and without exemplars (i.e., zero-shot and few-shot) and with and without chain of thought, enabling generalization across a range of evaluation scenarios.
In the paper, we instruction–fine-tune LMs of a range of sizes to investigate the joint effect of scaling both the size of the LM and the number of fine-tuning tasks. For instance, for the PaLM class of LMs, which includes models of 8B, 62B, and 540B parameters. We evaluate our models on four challenging benchmark evaluation suites (MMLU, BBH, TyDiQA, and MGSM), and find that both scaling the number of parameters and number of fine-tuning tasks improves performance on unseen tasks.
Both scaling up to a 540B parameter model and using 1.8K fine-tuning tasks improves the performance on unseen tasks. The y-axis is the normalized average over four evaluation suites (MMLU, BBH, TyDiQA, and MGSM).
In addition to better performance, instruction fine-tuning a LM enables it to respond to user instructions at inference time, without few-shot exemplars or prompt engineering. This makes LMs more user-friendly across a range of inputs. For instance, LMs without instruction fine-tuning can sometimes repeat the input or fail to follow instructions, but instruction fine-tuning mitigates such errors.
Our instruction–fine-tuned language model, Flan-PaLM, responds better to instructions compared to the PaLM model without instruction fine-tuning.
Putting Them Together
Finally, we show that UL2R and Flan can be combined to train the Flan-U-PaLM model. Since Flan uses new data from NLP tasks and enables zero-shot instruction following, we apply Flan as the second method after UL2R. We again evaluate on the four benchmark suites, and find that the Flan-U-PaLM model outperforms PaLM models with just UL2R (U-PaLM) or just Flan (Flan-PaLM). Further, Flan-U-PaLM achieves a new state-of-the-art on the MMLU benchmark with a score of 75.4% when combined with chain of thought and self-consistency.
Combining UL2R and Flan (Flan-U-PaLM) leads to the best performance compared to just using UL2R (U-PaLM) or just Flan (Flan-U-PaLM). Performance is the normalized average over four evaluation suites (MMLU, BBH, TyDiQA, and MGSM).
Overall, UL2R and Flan are two complementary methods for improving pre-trained language models. UL2R adapts the LM to a mixture-of-denoisers objective using the same data, whereas Flan leverages training data from over 1.8K NLP tasks to teach the model to follow instructions. As LMs become even larger, techniques such as UL2R and Flan that improve general performance without large amounts of compute may become increasingly attractive.
Acknowledgements
It was a privilege to collaborate on these two papers with Hyung Won Chung, Vinh Q. Tran, David R. So, Siamak Shakeri, Xavier Garcia, Huaixiu Steven Zheng, Jinfeng Rao, Aakanksha Chowdhery, Denny Zhou, Donald Metzler, Slav Petrov, Neil Houlsby, Quoc V. Le, Mostafa Dehghani, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Ed H. Chi, Jeff Dean, Jacob Devlin, and Adam Roberts.
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team
The field of natural language processing (NLP) has been revolutionized by language models trained on large amounts of text data. Scaling up the size of language models often leads to improved performance and sample efficiency on a range of downstream NLP tasks. In many cases, the performance of a large language model can be predicted by extrapolating the performance trend of smaller models. For instance, the effect of scale on language model perplexity has been empirically shown to span more than seven orders of magnitude.
On the other hand, performance for certain other tasks does not improve in a predictable fashion. For example, the GPT-3 paper showed that the ability of language models to perform multi-digit addition has a flat scaling curve (approximately random performance) for models from 100M to 13B parameters, at which point the performance jumped substantially. Given the growing use of language models in NLP research and applications, it is important to better understand abilities such as these that can arise unexpectedly.
In “Emergent Abilities of Large Language Models,” recently published in the Transactions on Machine Learning Research (TMLR), we discuss the phenomena of emergent abilities, which we define as abilities that are not present in small models but are present in larger models. More specifically, we study emergence by analyzing the performance of language models as a function of language model scale, as measured by total floating point operations (FLOPs), or how much compute was used to train the language model. However, we also explore emergence as a function of other variables, such as dataset size or number of model parameters (see the paper for full details). Overall, we present dozens of examples of emergent abilities that result from scaling up language models. The existence of such emergent abilities raises the question of whether additional scaling could potentially further expand the range of capabilities of language models.
Emergent Prompted Tasks
First we discuss emergent abilities that may arise in prompted tasks. In such tasks, a pre-trained language model is given a prompt for a task framed as next word prediction, and it performs the task by completing the response. Without any further fine-tuning, language models can often perform tasks that were not seen during training.
Example of few-shot prompting on movie review sentiment classification. The model is given one example of a task (classifying a movie review as positive or negative) and then performs the task on an unseen example.
We call a prompted task emergent when it unpredictably surges from random performance to above-random at a specific scale threshold. Below we show three examples of prompted tasks with emergent performance: multi-step arithmetic, taking college-level exams, and identifying the intended meaning of a word. In each case, language models perform poorly with very little dependence on model size up to a threshold at which point their performance suddenly begins to excel.
The ability to perform multi-step arithmetic (left), succeed on college-level exams (middle), and identify the intended meaning of a word in context (right) all emerge only for models of sufficiently large scale. The models shown include LaMDA, GPT-3, Gopher, Chinchilla, and PaLM.
Performance on these tasks only becomes non-random for models of sufficient scale — for instance, above 1022 training FLOPs for the arithmetic and multi-task NLU tasks, and above 1024 training FLOPs for the word in context tasks. Note that although the scale at which emergence occurs can be different for different tasks and models, no model showed smooth improvement in behavior on any of these tasks. Dozens of other emergent prompted tasks are listed in our paper.
Emergent Prompting Strategies
The second class of emergent abilities encompasses prompting strategies that augment the capabilities of language models. Prompting strategies are broad paradigms for prompting that can be applied to a range of different tasks. They are considered emergent when they fail for small models and can only be used by a sufficiently-large model.
One example of an emergent prompting strategy is called “chain-of-thought prompting”, for which the model is prompted to generate a series of intermediate steps before giving the final answer. Chain-of-thought prompting enables language models to perform tasks requiring complex reasoning, such as a multi-step math word problem. Notably, models acquire the ability to do chain-of-thought reasoning without being explicitly trained to do so. An example of chain-of-thought prompting is shown in the figure below.
Chain of thought prompting enables sufficiently large models to solve multi-step reasoning problems.
The empirical results of chain-of-thought prompting are shown below. For smaller models, applying chain-of-thought prompting does not outperform standard prompting, for example, when applied to GSM8K, a challenging benchmark of math word problems. However, for large models (1024 FLOPs), chain-of-thought prompting substantially improves performance in our tests, reaching a 57% solve rate on GSM8K.
Chain-of-thought prompting is an emergent ability — it fails to improve performance for small language models, but substantially improves performance for large models. Here we illustrate the difference between standard and chain-of-thought prompting at different scales for two language models, LaMDA and PaLM.
Implications of Emergent Abilities
The existence of emergent abilities has a range of implications. For example, because emergent few-shot prompted abilities and strategies are not explicitly encoded in pre-training, researchers may not know the full scope of few-shot prompted abilities of current language models. Moreover, the emergence of new abilities as a function of model scale raises the question of whether further scaling will potentially endow even larger models with new emergent abilities.
Identifying emergent abilities in large language models is a first step in understanding such phenomena and their potential impact on future model capabilities. Why does scaling unlock emergent abilities? Because computational resources are expensive, can emergent abilities be unlocked via other methods without increased scaling (e.g., better model architectures or training techniques)? Will new real-world applications of language models become unlocked when certain abilities emerge? Analyzing and understanding the behaviors of language models, including emergent behaviors that arise from scaling, is an important research question as the field of NLP continues to grow.
Acknowledgements
It was an honor and privilege to work with Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus.
Posted by Yi Tay and Mostafa Dehghani, Research Scientists, Google Research, Brain Team
Building models that understand and generate natural language well is one the grand goals of machine learning (ML) research and has a direct impact on building smart systems for everyday applications. Improving the quality of language models is a key target for researchers to make progress toward such a goal.
Most common paradigms to build and train language models use either autoregressive decoder-only architectures (e.g., PaLM or GPT-3), where the model is trained to predict the next word for a given prefix phrase, or span corruption-based encoder-decoder architectures (e.g., T5, ST-MoE), where the training objective is to recover the subset of words masked out of the input. On the one hand, T5-like models perform well on supervised fine-tuning tasks, but struggle with few-shot in-context learning. On the other hand, autoregressive language models are great for open-ended generation (e.g., dialog generation with LaMDA) and prompt-based learning (e.g., in-context learning with PaLM), but may perform suboptimally on fine-tuning tasks. Thus, there remains an opportunity to create an effective unified framework for pre-training models.
In “Unifying Language Learning Paradigms”, we present a novel language pre-training paradigm called Unified Language Learner (UL2) that improves the performance of language models universally across datasets and setups. UL2 frames different objective functions for training language models as denoising tasks, where the model has to recover missing sub-sequences of a given input. During pre-training it uses a novel mixture-of-denoisers that samples from a varied set of such objectives, each with different configurations. We demonstrate that models trained using the UL2 framework perform well in a variety of language domains, including prompt-based few-shot learning and models fine-tuned for down-stream tasks. Additionally, we show that UL2 excels in generation, language understanding, retrieval, long-text understanding and question answering tasks. Finally, we are excited to publicly release the checkpoints for our best performing UL2 20 billion parameter model.
Background: Language Modeling Objectives and Architectures Common objective functions for training language models can mostly be framed as learning data transformations that map inputs to targets. The model is conditioned on different forms of input to predict target tokens. To this end, different objectives utilize different properties of the inputs.
The standard Causal Language modeling objective (CausalLM) is trained to predict full sequence lengths and so, only recognizes tokens in the target output. The prefix language modeling objective (PrefixLM) modifies this process by randomly sampling a contiguous span of k tokens from the given tokenized text to form the input of the model, referred to as the “prefix”. The span corruption objective masks contiguous spans from the inputs and trains the model to predict these masked spans.
In the table below, we list the common objectives on which state-of-the-art language models are trained along with different characteristics of the input, i.e., how it is presented to the model. Moreover, we characterize the example efficiency of each objective in terms of the ability of the model for exploiting supervision signals from a single input, e.g., how much of the input tokens contribute to the calculation of the loss.
Objective Function
Inputs (Bi-directional)
Targets (Causal)
Input Properties
Example Efficiency
CausalLM
none
text
N/A
full seq_len
PrefixLM
text (up to position k)
text (after position k)
contiguous
seq_len - k
Span corruption
masked text
masked_tokens
non-contiguous, may be bi-directional
typically lower than others
Common objectives used in today’s language models. Throughout, “text” indicates tokenized text.
UL2 leverages the strengths of each of these objective functions through a framework that generalizes over each of them, which enables the ability to reason and unify common pre-training objectives. Based on this framework, the main task for training a language model is to learn the transformation of a sequence of input tokens to a sequence of target tokens. Then all the objective functions introduced above can be simply reduced to different ways of generating input and target tokens. For instance, the PrefixLM objective can be viewed as a transformation that moves a segment of k contiguous tokens from the inputs to the targets. Meanwhile, the span corruption objective is a data transformation that corrupts spans (a subsequence of tokens in the input), replacing them with mask tokens that are shifted to the targets.
It is worth noting that one can decouple the model architecture and the objective function with which it’s trained. Thus, it is possible to train different architectures, such as the common single stack decoder-only and two-stack encoder-decoder models, with any of these objectives.
Mixture of Denoisers The UL2 framework can be used to train a model on a mixture of pre-training objectives and supply it with capabilities and inductive bias benefits from different pre-training tasks. Training on the mixture helps the model leverage the strengths of different tasks and mitigates the weaknesses of others. For instance, the mixture-of-denoisers objective can strongly improve the prompt-based learning capability of the model as opposed to a span corruption-only T5 model.
UL2 is trained using a mixture of three denoising tasks: (1) R-denoising (or regular span corruption), which emulates the standard T5 span corruption objective; (2) X-denoising (or extreme span corruption); and (3) S-denoising (or sequential PrefixLM). During pre-training, we sample from the available denoising tasks based on user-specified ratios (i.e., different combinations of the R, X, and S-denoisers) and prepare the input and target appropriately. Then, a paradigm token is appended to the input (one of [R], [X], or [S]) indicating the denoising task at hand.
An overview of the denoising objectives used in UL2’s mixture-of-denoisers.
Improving Trade-Offs Across Learning Paradigms Many existing commonly used language learning paradigms typically excel at one type of task or application, such as fine-tuning performance or prompt-based in-context learning. In the plot below, we show baseline objective functions on different tasks compared to UL2: CausalLM (referred to as GPT-like), PrefixLM, Span Corrupt (also referred to as T5 in the plot), and a baseline objective function proposed by UniLM. We use these objectives for training decoder only architectures (green) and encoder-decoder architectures (blue) and evaluate different combinations of objective functions and architectures on two main sets of tasks:
Fine-tuning, by measuring performance on SuperGLUE (y-axis of the plot below)
For most of the existing language learning paradigms, there is a trade-off between the quality of the model on these two sets of tasks. We show that UL2 bridges this trade-off across in-context learning and fine-tuning.
In both decoder-only and encoder-decoder setups, UL2 strikes a significantly improved balance in performance between fine-tuned discriminative tasks and prompt-based 1-shot open-ended text generation compared to previous methods. (All models are comparable in terms of computational costs, i.e., FLOPs (EncDec models are 300M and Dec models are 150M parameters).
UL2 for Few-Shot Prompting and Chain-of-Thought Reasoning We scale up UL2 and train a 20 billion parameter encoder-decoder model on the public C4 corpus and demonstrate some impressive capabilities of the UL2 20B model.
UL2 is a powerful in-context learner that excels at both few-shot and chain-of-thought (CoT) prompting. In the table below, we compare UL2 with other state-of-the-art models (e.g, T5 XXL and PaLM) for few-shot prompting on the XSUM summarization dataset. Our results show that UL2 20B outperforms PaLM and T5, both of which are in the same ballpark of compute cost.
Model
ROUGE-1
ROUGE-2
ROUGE-L
LaMDA 137B
–
5.4
–
PaLM 62B
–
11.2
–
PaLM 540B
–
12.2
–
PaLM 8B
–
4.5
–
T5 XXL 11B
0.6
0.1
0.6
T5 XXL 11B + LM
13.3
2.3
10.7
UL2 20B
25.5
8.6
19.8
Comparison of UL2 with T5 XXL, PaLM and LamDA 137B on 1-shot summarization (XSUM) in terms of ROUGE-1/2/L (higher is better), which captures the quality by comparing the generated summaries with the gold summaries as reference.
Most CoT prompting results have been obtained using much larger language models, such as GPT-3 175B, PaLM 540B, or LaMDA 137B. We show that reasoning via CoT prompting can be achieved with UL2 20B, which is both publicly available and several times smaller than prior models that leverage chain-of-thought prompting. This enables an open avenue for researchers to conduct research on CoT prompting and reasoning at an accessible scale. In the table below, we show that for UL2, CoT prompting outperforms standard prompting on math word problems with a range of difficulties (GSM8K, SVAMP, ASDiv, AQuA, and MAWPS). We also show that self-consistency further improves performance.
Chain-of-thought (CoT) prompting and self-consistency (SC) results on five arithmetic reasoning benchmarks.
Conclusion and Future Directions UL2 demonstrates superior performance on a plethora of fine-tuning and few-shot tasks. We publicly release checkpoints of our best performing UL2 model with 20 billion parameters, which we hope will inspire faster progress in developing better language models in the machine learning community as a whole.
Acknowledgements It was an honor and privilege to work on this with Vinh Q. Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Denny Zhou, Neil Houlsby and Donald Metzler. We further acknowledge Alexey Gritsenko, Andrew M. Dai, Jacob Devlin, Jai Gupta, William Fedus, Orhan Firat, Sebastian Gerhmann, Nan Du, Dave Uthus, Siamak Shakeri, Slav Petrov and Quoc Le for support and discussions. We thank the Jax and T5X team for building such wonderful infrastructure that made this research possible.
Posted by Jason Wei and Denny Zhou, Research Scientists, Google Research, Brain team
In recent years, scaling up the size of language models has been shown to be a reliable way to improve performance on a range of natural language processing (NLP) tasks. Today’s language models at the scale of 100B or more parameters achieve strong performance on tasks like sentiment analysis and machine translation, even with little or no training examples. Even the largest language models, however, can still struggle with certain multi-step reasoning tasks, such as math word problems and commonsense reasoning. How might we enable language models to perform such reasoning tasks?
In “Chain of Thought Prompting Elicits Reasoning in Large Language Models,” we explore a prompting method for improving the reasoning abilities of language models. Called chain of thought prompting, this method enables models to decompose multi-step problems into intermediate steps. With chain of thought prompting, language models of sufficient scale (~100B parameters) can solve complex reasoning problems that are not solvable with standard prompting methods.
Comparison to Standard Prompting With standard prompting (popularized by GPT-3) the model is given examples of input–output pairs (formatted as questions and answers) before being asked to predict the answer for a test-time example (shown below on the left). In chain of thought prompting (below, right), the model is prompted to produce intermediate reasoning steps before giving the final answer to a multi-step problem. The idea is that a model-generated chain of thought would mimic an intuitive thought process when working through a multi-step reasoning problem. While producing a thought process has been previously accomplished via fine-tuning, we show that such thought processes can be elicited by including a few examples of chain of thought via prompting only, which does not require a large training dataset or modifying the language model’s weights.
Whereas standard prompting asks the model to directly give the answer to a multi-step reasoning problem, chain of thought prompting induces the model to decompose the problem into intermediate reasoning steps, in this case leading to a correct final answer.
Chain of thought reasoning allows models to decompose complex problems into intermediate steps that are solved individually. Moreover, the language-based nature of chain of thought makes it applicable to any task that a person could solve via language. We find through empirical experiments that chain of thought prompting can improve performance on various reasoning tasks, and that successful chain of thought reasoning is an emergent property of model scale — that is, the benefits of chain of thought prompting only materialize with a sufficient number of model parameters (around 100B).
Arithmetic Reasoning One class of tasks where language models typically struggle is arithmetic reasoning (i.e., solving math word problems). Two benchmarks in arithmetic reasoning are MultiArith and GSM8K, which test the ability of language models to solve multi-step math problems similar to the one shown in the figure above. We evaluate both the LaMDA collection of language models ranging from 422M to 137B parameters, as well as the PaLM collection of language models ranging from 8B to 540B parameters. We manually compose chains of thought to include in the examples for chain of thought prompting.
For these two benchmarks, using standard prompting leads to relatively flat scaling curves: increasing the scale of the model does not substantially improve performance (shown below). However, we find that when using chain of thought prompting, increasing model scale leads to improved performance that substantially outperforms standard prompting for large model sizes.
Employing chain of thought prompting enables language models to solve arithmetic reasoning problems for which standard prompting has a mostly flat scaling curve.
On the GSM8K dataset of math word problems, PaLM shows remarkable performance when scaled to 540B parameters. As shown in the table below, combining chain of thought prompting with the 540B parameter PaLM model leads to new state-of-the-art performance of 58%, surpassing the prior state of the art of 55% achieved by fine-tuning GPT-3 175B on a large training set and then ranking potential solutions via a specially trained verifier. Moreover, follow-up work on self-consistency shows that the performance of chain of thought prompting can be improved further by taking the majority vote of a broad set of generated reasoning processes, which results in 74% accuracy on GSM8K.
Chain of thought prompting with PaLM achieves a new state of the art on the GSM8K benchmark of math word problems. For a fair comparison against fine-tuned GPT-3 baselines, the chain of thought prompting results shown here also use an external calculator to compute basic arithmetic functions (i.e., addition, subtraction, multiplication and division).
Commonsense Reasoning In addition to arithmetic reasoning, we consider whether the language-based nature of chain of thought prompting also makes it applicable to commonsense reasoning, which involves reasoning about physical and human interactions under the presumption of general background knowledge. For these evaluations, we use the CommonsenseQA and StrategyQA benchmarks, as well as two domain-specific tasks from BIG-Bench collaboration regarding date understanding and sports understanding. Example questions are below:
As shown below, for CommonsenseQA, StrategyQA, and Date Understanding, performance improved with model scale, and employing chain of thought prompting led to additional small improvements. Chain of thought prompting had the biggest improvement on sports understanding, for which PaLM 540B’s chain of thought performance surpassed that of an unaided sports enthusiast (95% vs 84%).
Chain of thought prompting also improves performance on various types of commonsense reasoning tasks.
Conclusions Chain of thought prompting is a simple and broadly applicable method for improving the ability of language models to perform various reasoning tasks. Through experiments on arithmetic and commonsense reasoning, we find that chain of thought prompting is an emergent property of model scale. Broadening the range of reasoning tasks that language models can perform will hopefully inspire further work on language-based approaches to reasoning.
Acknowledgements It was an honor and privilege to work with Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Quoc Le on this project.
Posted by Maxwell Bileschi, Staff Software Engineer and Lucy Colwell, Research Scientist, Google Research, Brain Team
Proteins are essential molecules found in all living things. They play a central role in our bodies’ structure and function, and they are also featured in many products that we encounter every day, from medications to household items like laundry detergent. Each protein is a chain of amino acid building blocks, and just as an image may include multiple objects, like a dog and a cat, a protein may also have multiple components, which are called protein domains. Understanding the relationship between a protein’s amino acid sequence — for example, its domains — and its structure or function are long-standing challenges with far-reaching scientific implications.
An example of a protein with known structure, TrpCF from E. coli, for which areas used by a model to predict function are highlighted (green). This protein produces tryptophan, which is an essential part of a person’s diet.
Many are familiar with recent advances in computationally predicting protein structure from amino acid sequences, as seen with DeepMind’s AlphaFold. Similarly, the scientific community has a long history of using computational tools to infer protein function directly from sequences. For example, the widely-used protein family database Pfam contains numerous highly-detailed computational annotations that describe a protein domain's function, e.g., the globin and trypsin families. While existing approaches have been successful at predicting the function of hundreds of millions of proteins, there are still many more with unknown functions — for example, at least one-third of microbial proteins are not reliably annotated. As the volume and diversity of protein sequences in public databases continue to increase rapidly, the challenge of accurately predicting function for highly divergent sequences becomes increasingly pressing.
In “Using Deep Learning to Annotate the Protein Universe”, published in Nature Biotechnology, we describe a machine learning (ML) technique to reliably predict the function of proteins. This approach, which we call ProtENN, has enabled us to add about 6.8 million entries to Pfam’s well-known and trusted set of protein function annotations, about equivalent to the sum of progress over the last decade, which we are releasing as Pfam-N. To encourage further research in this direction, we are releasing the ProtENN model and a distill-like interactive article where researchers can experiment with our techniques. This interactive tool allows the user to enter a sequence and get results for a predicted protein function in real time, in the browser, with no setup required. In this post, we’ll give an overview of this achievement and how we’re making progress toward revealing more of the protein universe.
The Pfam database is a large collection of protein families and their sequences. Our ML model ProtENN helped annotate 6.8 million more protein regions in the database.
Protein Function Prediction as a Classification Problem In computer vision, it’s common to first train a model for image classification tasks, like CIFAR-100, before extending it to more specialized tasks, like object detection and localization. Similarly, we develop a protein domain classification model as a first step towards future models for classification of entire protein sequences. We frame the problem as a multi-class classification task in which we predict a single label out of 17,929 classes — all classes contained in the Pfam database — given a protein domain’s sequence of amino acids.
Models that Link Sequence to Function While there are a number of models currently available for protein domain classification, one drawback of the current state-of-the-art methods is that they are based on the alignment of linear sequences and don’t consider interactions between amino acids in different parts of protein sequences. But proteins don’t just stay as a line of amino acids, they fold in on themselves such that nonadjacent amino acids have strong effects on each other.
Aligning a new query sequence to one or more sequences with known function is a key step of current state-of-the-art methods. This reliance on sequences with known function makes it challenging to predict a new sequence’s function if it is highly dissimilar to any sequence with known function. Furthermore, alignment-based methods are computationally intensive, and applying them to large datasets, such as the metagenomic database MGnify, which contains >1 billion protein sequences, can be cost prohibitive.
To address these challenges, we propose to use dilatedconvolutional neural networks (CNNs), which should be well-suited to modeling non-local pairwise amino-acid interactions and can be run on modern ML hardware like GPUs. We train 1-dimensional CNNs to predict the classification of protein sequences, which we call ProtCNN, as well as an ensemble of independently trained ProtCNN models, which we call ProtENN. Our goal for using this approach is to add knowledge to the scientific literature by developing a reliable ML approach that complements traditional alignment-based methods. To demonstrate this, we developed a method to accurately measure our method's accuracy.
Evaluation with Evolution in Mind Similar to well-known classification problems in other fields, the challenge in protein function prediction is less in developing a completely new model for the task, and more in creating fair training and test sets to ensure that the models will make accurate predictions for unseen data. Because proteins have evolved from shared common ancestors, different proteins often share a substantial fraction of their amino acid sequence. Without proper care, the test set could be dominated by samples that are highly similar to the training data, which could lead to the models performing well by simply “memorizing” the training data, rather than learning to generalize more broadly from it.
We create a test set that requires ProtENN to generalize well on data far from its training set.
To guard against this, it is essential to evaluate model performance using multiple separate setups. For each evaluation, we stratify model accuracy as a function of similarity between each held-out test sequence and the nearest sequence in the train set.
The first evaluation includes a clustered split training and test set, consistent with prior literature. Here, protein sequence samples are clustered by sequence similarity, and entire clusters are placed into either the train or test sets. As a result, every test example is at least 75% different from every training example. Strong performance on this task demonstrates that a model can generalize to make accurate predictions for out-of-distribution data.
For the second evaluation, we use a randomly split training and test set, where we stratify examples based on an estimate of how difficult they will be to classify. These measures of difficulty include: (1) the similarity between a test example and the nearest training example, and (2) the number of training examples from the true class (it is much more difficult to accurately predict function given just a handful of training examples).
To place our work in context, we evaluate the performance of the most widely used baseline models and evaluation setups, with the following baseline models in particular: (1) BLAST, a nearest-neighbor method that uses sequence alignment to measure distance and infer function, and (2) profile hidden Markov models (TPHMM and phmmer). For each of these, we include the stratification of model performance based on sequence alignment similarity mentioned above. We compared these baselines against ProtCNN and the ensemble of CNNs, ProtENN.
We measure each model’s ability to generalize, from the hardest examples (left) to the easiest (right).
Reproducible and Interpretable Results We also worked with the Pfam team to test whether our methodological proof of concept could be used to label real-world sequences. We demonstrated that ProtENN learns complementary information to alignment-based methods, and created an ensemble of the two approaches to label more sequences than either method could by itself. We publicly released the results of this effort, Pfam-N, a set of 6.8 million new protein sequence annotations.
After seeing the success of these methods and classification tasks, we inspected these networks to understand whether the embeddings were generally useful. We built a tool that enables users to explore the relation between the model predictions, embeddings, and input sequences, which we have made available through our interactive manuscript, and we found that similar sequences were clustered together in embedding space. Furthermore, the network architecture that we selected, a dilated CNN, allows us to employ previously-discovered interpretability methods like class activation mapping (CAM) and sufficient input subsets (SIS) to identify the sub-sequences responsible for the neural network predictions. With this approach, we find that our network generally focuses on the relevant elements of a sequence to predict its function.
Conclusion and Future Work We’re excited about the progress we’ve seen by applying ML to the understanding of protein structure and function over the last few years, which has been reflected in contributions from the broader research community, from AlphaFold and CAFA to the multitude of workshops and research presentations devoted to this topic at conferences. As we look to build on this work, we think that continuing to collaborate with scientists across the field who’ve shared their expertise and data, combined with advances in ML will help us further reveal the protein universe.
Acknowledgments We’d like to thank all of the co-authors of the manuscripts, Maysam Moussalem, Jamie Smith, Eli Bixby, Babak Alipanahi, Shanqing Cai, Cory McLean, Abhinay Ramparasad, Steven Kearnes, Zack Nado, and Tom Small.
Posted by Jeff Dean, Senior Fellow and SVP of Google Research, on behalf of the entire Google Research community
Over the last several decades, I've witnessed a lot of change in the fields of machine learning (ML) and computer science. Early approaches, which often fell short, eventually gave rise to modern approaches that have been very successful. Following that long-arc pattern of progress, I think we'll see a number of exciting advances over the next several years, advances that will ultimately benefit the lives of billions of people with greater impact than ever before. In this post, I’ll highlight five areas where ML is poised to have such impact. For each, I’ll discuss related research (mostly from 2021) and the directions and progress we’ll likely see in the next few years.
Trend 1: More Capable, General-Purpose ML Models Researchers are training larger, more capable machine learning models than ever before. For example, just in the last couple of years models in the language domain have grown from billions of parameters trained on tens of billions of tokens of data (e.g., the 11B parameter T5 model), to hundreds of billions or trillions of parameters trained on trillions of tokens of data (e.g., dense models such as OpenAI’s 175B parameter GPT-3 model and DeepMind’s 280B parameter Gopher model, and sparse models such as Google’s 600B parameter GShard model and 1.2T parameter GLaM model). These increases in dataset and model size have led to significant increases in accuracy for a wide variety of language tasks, as shown by across-the-board improvements on standard natural language processing (NLP) benchmark tasks (as predicted by work on neural scaling laws for language models and machine translation models).
Many of these advanced models are focused on the single but important modality of written language and have shown state-of-the-art results in language understanding benchmarks and open-ended conversational abilities, even across multiple tasks in a domain. They have also shown exciting capabilities to generalize to new language tasks with relatively little training data, in some cases, with few to no training examples for a new task. A couple of examples include improved long-form question answering, zero-label learning in NLP, and our LaMDA model, which demonstrates a sophisticated ability to carry on open-ended conversations that maintain significant context across multiple turns of dialog.
A dialog with LaMDA mimicking a Weddell seal with the preset grounding prompt, “Hi I’m a weddell seal. Do you have any questions for me?” The model largely holds down a dialog in character. (Weddell Seal image cropped from Wikimedia CC licensed image.)
Example of a cascade diffusion models that generate novel images from a given category and then use those as the seed to create high-resolution examples: the first model generates a low resolution image, and the rest perform upsampling to the final high resolution image.
The SR3 super-resolution diffusion model takes as input a low-resolution image, and builds a corresponding high resolution image from pure noise.
Because these are powerful capabilities that come with great responsibility, we carefully vet potential applications of these sorts of models against our AI Principles.
Example of a vision-based robotic manipulation system that is able to generalize to novel tasks. Left: The robot is performing a task described in natural language to the robot as “place grapes in ceramic bowl”, without the model being trained on that specific task. Right: As on the left, but with the novel task description of “place bottle in tray”.
Often these models are trained using self-supervised learning approaches, where the model learns from observations of “raw” data that has not been curated or labeled, e.g., language models used in GPT-3 and GLaM, the self-supervised speech model BigSSL, the visual contrastive learning model SimCLR, and the multimodal contrastive model VATT. Self-supervised learning allows a large speech recognition model to match the previous Voice Search automatic speech recognition (ASR) benchmark accuracy while using only 3% of the annotated training data. These trends are exciting because they can substantially reduce the effort required to enable ML for a particular task, and because they make it easier (though by no means trivial) to train models on more representative data that better reflects different subpopulations, regions, languages, or other important dimensions of representation.
All of these trends are pointing in the direction of training highly capable general-purpose models that can handle multiple modalities of data and solve thousands or millions of tasks. By building in sparsity, so that the only parts of a model that are activated for a given task are those that have been optimized for it, these multimodal models can be made highly efficient. Over the next few years, we are pursuing this vision in a next-generation architecture and umbrella effort called Pathways. We expect to see substantial progress in this area, as we combine together many ideas that to date have been pursued relatively independently.
Pathways: a depiction of a single model we are working towards that can generalize across millions of tasks.
Trend 2: Continued Efficiency Improvements for ML Improvements in efficiency — arising from advances in computer hardware design as well as ML algorithms and meta-learning research — are driving greater capabilities in ML models. Many aspects of the ML pipeline, from the hardware on which a model is trained and executed to individual components of the ML architecture, can be optimized for efficiency while maintaining or improving on state-of-the-art performance overall. Each of these different threads can improve efficiency by a significant multiplicative factor, and taken together, can reduce computational costs, including CO2 equivalent emissions (CO2e), by orders of magnitude compared to just a few years ago. This greater efficiency has enabled a number of critical advances that will continue to dramatically improve the efficiency of machine learning, enabling larger, higher quality ML models to be developed cost effectively and further democratizing access. I’m very excited about these directions of research!
Continued Improvements in ML Accelerator Performance
Each generation of ML accelerator improves on previous generations, enabling faster performance per chip, and often increasing the scale of the overall systems. Last year, we announced our TPUv4 systems, the fourth generation of Google’s Tensor Processing Unit, which demonstrated a 2.7x improvement over comparable TPUv3 results in the MLPerf benchmarks. Each TPUv4 chip has ~2x the peak performance per chip versus the TPUv3 chip, and the scale of each TPUv4 pod is 4096 chips (4x that of TPUv3 pods), yielding a performance of approximately 1.1 exaflops per pod (versus ~100 petaflops per TPUv3 pod). Having pods with larger numbers of chips that are connected together with high speed networks improves efficiency for larger models.
ML capabilities on mobile devices are also increasing significantly. The Pixel 6 phone features a brand new Google Tensor processor that integrates a powerful ML accelerator to better support important on-device features.
Left: TPUv4 board; Center: Part of a TPUv4 pod; Right: Google Tensor chip found in Pixel 6 phones.
Our use of ML to accelerate the design of computer chips of all kinds (more on this below) is also paying dividends, particularly to produce better ML accelerators.
Continued Improvements in ML Compilation and Optimization of ML Workloads
Even when the hardware is unchanged, improvements in compilers and other optimizations in system software for machine learning accelerators can lead to significant improvements in efficiency. For example, “A Flexible Approach to Autotuning Multi-pass Machine Learning Compilers” shows how to use machine learning to perform auto-tuning of compilation settings to get across-the-board performance improvements of 5-15% (and sometimes as much as 2.4x improvement) for a suite of ML programs on the same underlying hardware. GSPMD describes an automatic parallelization system based on the XLA compiler that is capable of scaling most deep learning network architectures beyond the memory capacity of an accelerator and has been applied to many large models, such as GShard-M4, LaMDA, BigSSL, ViT, MetNet-2, and GLaM, leading to state-of-the-art results across several domains.
End-to-end model speedups from using ML-based compiler autotuning on 150 ML models. Included are models that achieve improvements of 5% or more. Bar colors represent relative improvement from optimizing different model components.
Human-Creativity–Driven Discovery of More Efficient Model Architectures
Continued improvements in model architectures give substantial reductions in the amount of computation needed to achieve a given level of accuracy for many problems. For example, the Transformer architecture, which we developed in 2017, was able to improve the state of the art on several NLP and translation benchmarks while simultaneously using 10x to 100x less computation to achieve these results than a variety of other prevalent methods, such as LSTMs and other recurrent architectures. Similarly, the Vision Transformer was able to show improved state-of-the-art results on a number of different image classification tasks despite using 4x to 10x less computation than convolutional neural networks.
Machine-Driven Discovery of More Efficient Model Architectures
Neural architecture search (NAS) can automatically discover new ML architectures that are more efficient for a given problem domain. A primary advantage of NAS is that it can greatly reduce the effort needed for algorithm development, because NAS requires only a one-time effort per search space and problem domain combination. In addition, while the initial effort to perform NAS can be computationally expensive, the resulting models can greatly reduce computation in downstream research and production settings, resulting in greatly reduced resource requirements overall. For example, the one-time search to discover the Evolved Transformer generated only 3.2 tons of CO2e (much less than the 284t CO2e reported elsewhere; see Appendix C and D in this joint Google/UC Berkeley preprint), but yielded a model for use by anyone in the NLP community that is 15-20% more efficient than the plain Transformer model. A more recent use of NAS discovered an even more efficient architecture called Primer (that has also been open-sourced), which reduces training costs by 4x compared to a plain Transformer model. In this way, the discovery costs of NAS searches are often recouped from the use of the more-efficient model architectures that are discovered, even if they are applied to only a handful of downstream uses (and many NAS results are reused thousands of times).
The Primer architecture discovered by NAS is 4x as efficient compared with a plain Transformer model. This image shows (in red) the two main modifications that give Primer most of its gains: depthwise convolution added to attention multi-head projections and squared ReLU activations (blue indicates portions of the original Transformer).
NAS has also been used to discover more efficient models in the vision domain. The EfficientNetV2 model architecture is the result of a neural architecture search that jointly optimizes for model accuracy, model size, and training speed. On the ImageNet benchmark, EfficientNetV2 improves training speed by 5–11x while substantially reducing model size over previous state-of-the-art models. The CoAtNet model architecture was created with an architecture search that uses ideas from the Vision Transformer and convolutional networks to create a hybrid model architecture that trains 4x faster than the Vision Transformer and achieves a new ImageNet state of the art.
EfficientNetV2 achieves much better training efficiency than prior models for ImageNet classification.
The broad use of search to help improve ML model architectures and algorithms, including the use of reinforcement learning and evolutionary techniques, has inspired other researchers to apply this approach to different domains. To aid others in creating their own model searches, we have open-sourced Model Search, a platform that enables others to explore model search for their domains of interest. In addition to model architectures, automated search can also be used to find new, more efficient reinforcement learning algorithms, building on the earlier AutoML-Zero work that demonstrated this approach for automating supervised learning algorithm discovery.
Use of Sparsity
Sparsity, where a model has a very large capacity, but only some parts of the model are activated for a given task, example or token, is another important algorithmic advance that can greatly improve efficiency. In 2017, we introduced the sparsely-gated mixture-of-experts layer, which demonstrated better results on a variety of translation benchmarks while using 10x less computation than previous state-of-the-art dense LSTM models. More recently, Switch Transformers, which pair a mixture-of-experts–style architecture with the Transformer model architecture, demonstrated a 7x speedup in training time and efficiency over the dense T5-Base Transformer model. The GLaM model showed that transformers and mixture-of-expert–style layers can be combined to produce a model that exceeds the accuracy of the GPT-3 model on average across 29 benchmarks using 3x less energy for training and 2x less computation for inference. The notion of sparsity can also be applied to reduce the cost of the attention mechanism in the core Transformer architecture.
The BigBird sparse attention model consists of global tokens that attend to all parts of an input sequence, local tokens, and a set of random tokens. Theoretically, this can be interpreted as adding a few global tokens on a Watts-Strogatz graph.
The use of sparsity in models is clearly an approach with very high potential payoff in terms of computational efficiency, and we are only scratching the surface in terms of research ideas to be tried in this direction.
Each of these approaches for improved efficiency can be combined together so that equivalent-accuracy language models trained today in efficient data centers are ~100 times more energy efficient and produce ~650 times less CO2e emissions, compared to a baseline Transformer model trained using P100 GPUs in an average U.S. datacenter using an average U.S. energy mix. And this doesn’t even account for Google’s carbon-neutral, 100% renewable energy offsets. We’ll have a more detailed blog post analyzing the carbon emissions trends of NLP models soon.
Trend 3: ML Is Becoming More Personally and Communally Beneficial A host of new experiences are made possible as innovation in ML and silicon hardware (like the Google Tensor processor on the Pixel 6) enable mobile devices to be more capable of continuously and efficiently sensing their surrounding context and environment. These advances have improved accessibility and ease of use, while also boosting computational power, which is critical for popular features like mobile photography, live translation and more. Remarkably, recent technological advances also provide users with a more customized experience while strengthening privacy safeguards.
More people than ever rely on their phone cameras to record their daily lives and for artistic expression. The clever application of ML to computational photography has continued to advance the capabilities of phone cameras, making them easier to use, improving performance, and resulting in higher-quality images. Advances, such as improved HDR+, the ability to take pictures in very low light, better handling of portraits, and efforts to make cameras more inclusive so they work for all skin tones, yield better photos that are more true to the photographer’s vision and to their subjects. Such photos can be further improved using the powerful ML-based tools now available in Google Photos, like cinematic photos, noise and blur reduction, and the Magic Eraser.
HDR+ starts from a burst of full-resolution raw images, each underexposed by the same amount (left). The merged image has reduced noise and increased dynamic range, leading to a higher quality final result (right).
In addition to using their phones for creative expression, many people rely on them to help communicate with others across languages and modalities in real-time using Live Translate in messaging apps and Live Caption for phone calls. Speech recognition accuracy has continued to make substantial improvements thanks to techniques like self-supervised learning and noisy student training, with marked improvements for accented speech, noisy conditions or environments with overlapping speech, and across many languages. Building on advances in text-to-speech synthesis, people can listen to web pages and articles using our Read Aloud technology on a growing number of platforms, making information more available across barriers of modality and languages. Live speech translations in the Google Translate app have become significantly better by stabilizing the translations that are generated on-the-fly, and high quality, robust and responsible direct speech-to-speech translation provides a much better user experience in communicating with people speaking a different language. New work on combining ML with traditional codec approaches in the Lyra speech codec and the more general SoundStream audio codec enables higher fidelity speech, music, and other sounds to be communicated reliably at much lower bitrate.
Recent work demonstrates the ability of gaze recognition as an important biomarker of mental fatigue.
Given the potentially sensitive nature of the data that underlies these new capabilities, it is essential that they are designed to be private by default. Many of them run inside of Android's Private Compute Core — an open source, secure environment isolated from the rest of the operating system. Android ensures that data processed in the Private Compute Core is not shared to any apps without the user taking an action. Android also prevents any feature inside the Private Compute Core from having direct access to the network. Instead, features communicate over a small set of open-source APIs to Private Compute Services, which strips out identifying information and makes use of privacy technologies, including federated learning, federated analytics, and private information retrieval, enabling learning while simultaneously ensuring privacy.
Federated Reconstruction is a novel partially local federated learning technique in which models are partitioned into global and local parameters. For each round of Federated Reconstruction training: (1) The server sends the current global parameters g to each user i; (2) Each user i freezes g and reconstructs their local parameters li; (3) Each user i freezes li and updates g to produce gi; (4) Users’ gi are averaged to produce the global parameters for the next round.
These technologies are critical to evolving next-generation computation and interaction paradigms, whereby personal or communal devices can both learn from and contribute to training a collective model of the world without compromising privacy. A federated unsupervised approach to privately learn the kinds of aforementioned general-purpose models with fine-tuning for a given task or context could unlock increasingly intelligent systems that are far more intuitive to interact with — more like a social entity than a machine. Broad and equitable access to these intelligent interfaces will only be possible with deep changes to our technology stacks, from the edge to the datacenter, so that they properly support neural computing.
Trend 4: Growing Impact of ML in Science, Health and Sustainability In recent years, we have seen an increasing impact of ML in the basic sciences, from physics to biology, with a number of exciting practical applications in related realms, such as renewable energy and medicine. Computer vision models have been deployed to address problems at both personal and global scales. They can assist physicians in their regular work, expand our understanding of neural physiology, and also provide better weather forecasts and streamline disaster relief efforts. Other types of ML models are proving critical in addressing climate change by discovering ways to reduce emissions and improving the output of alternative energy sources. Such models can even be leveraged as creative tools for artists! As ML becomes more robust, well-developed, and widely accessible, its potential for high-impact applications in a broad array of real-world domains continues to expand, helping to solve some of our most challenging problems.
Large-Scale Application of Computer Vision for New Insights
The advances in computer vision over the past decade have enabled computers to be used for a wide variety of tasks across different scientific domains. In neuroscience, automated reconstruction techniques can recover the neural connective structure of brain tissues from high resolution electron microscopy images of thin slices of brain tissue. In previous years, we have collaborated to create such resources for fruit fly, mouse, and songbird brains, but last year, we collaborated with the Lichtman Lab at Harvard University to analyze the largest sample of brain tissue imaged and reconstructed in this level of detail, in any species, and produced the first large-scale study of synaptic connectivity in the human cortex that spans multiple cell types across all layers of the cortex. The goal of this work is to produce a novel resource to assist neuroscientists in studying the stunning complexity of the human brain. The image below, for example, shows six neurons out of about 86 billion neurons in an adult human brain.
A single human chandelier neuron from our human cortex reconstruction, along with some of the pyramidal neurons that make a connection with that cell. Here’s an interactive version and a gallery of other interactive examples.
Computer vision technology also provides powerful tools to address challenges at much larger, even global, scales. A deep-learning–based approach to weather forecasting that uses satellite and radar imagery as inputs, combined with other atmospheric data, produces weather and precipitation forecasts that are more accurate than traditional physics-based models at forecasting times up to 12 hours. They can also produce updated forecasts much more quickly than traditional methods, which can be critical in times of extreme weather.
Comparison of 0.2 mm/hr precipitation on March 30, 2020 over Denver, Colorado. Left: Ground truth, source MRMS. Center: Probability map as predicted by MetNet-2. Right: Probability map as predicted by the physics-based HREFmodel. MetNet-2 is able to predict the onset of the storm earlier in the forecast than HREF as well as the storm’s starting location, whereas HREF misses the initiation location, but captures its growth phase well.
Having an accurate record of building footprints is essential for a range of applications, from population estimation and urban planning to humanitarian response and environmental science. In many parts of the world, including much of Africa, this information wasn’t previously available, but new work shows that using computer vision techniques applied to satellite imagery can help identify building boundaries at continental scales. The results of this approach have been released in the Open Buildings dataset, a new open-access data resource that contains the locations and footprints of 516 million buildings with coverage across most of the African continent. We’ve also been able to use this unique dataset in our collaboration with the World Food Programme to provide fast damage assessment after natural disasters through application of ML.
Example of segmenting buildings in satellite imagery. Left: Source image; Center: Semantic segmentation, with each pixel assigned a confidence score that it is a building vs. non-building; Right: Instance segmentation, obtained by thresholding and grouping together connected components.
A common theme across each of these cases is that ML models are able to perform specialized tasks efficiently and accurately based on analysis of available visual data, supporting high impact downstream tasks.
Automated Design Space Exploration
Another approach that has yielded excellent results across many fields is to allow an ML algorithm to explore and evaluate a problem’s design space for possible solutions in an automated way. In one application, a Transformer-based variational autoencoder learns to create aesthetically-pleasing and useful document layouts, and the same approach can be extended to explore possible furniture layouts. Another ML-driven approach automates the exploration of the huge design space of tweaks for computer game rules to improve playability and other attributes of a game, enabling human game designers to create enjoyable games more quickly.
A visualization of the Variational Transformer Network (VTN) model, which is able to extract meaningful relationships between the layout elements (paragraphs, tables, images, etc.) in order to generate realistic synthetic documents (e.g., with better alignment and margins).
Other ML algorithms have been used to evaluate the design space of computer architectural decisions for ML accelerator chips themselves. We’ve also shown that ML can be used to quickly create chip placements for ASIC designs that are better than layouts generated by human experts and can be generated in a matter of hours instead of weeks. This reduces the fixed engineering costs of chips and lowers the barrier to quickly creating specialized hardware for different applications. We’ve successfully used this automated placement approach in the design of our upcoming TPU-v5 chip.
Such exploratory ML approaches have also been applied to materials discovery. In a collaboration between Google Research and Caltech, several ML models, combined with a modified inkjet printer and a custom-built microscope, were able to rapidly search over hundreds of thousands of possible materials to hone in on 51 previously uncharacterized three-metal oxide materials with promising properties for applications in areas like battery technology and electrolysis of water.
These automated design space exploration approaches can help accelerate many scientific fields, especially when the entire experimental loop of generating the experiment and evaluating the result can all be done in an automated or mostly-automated manner. I expect to see this approach applied to good effect in many more areas in the coming years.
Application to Health
In addition to advancing basic science, ML can also drive advances in medicine and human health more broadly. The idea of leveraging advances in computer science in health is nothing new — in fact some of my own early experiences were in developing software to help analyze epidemiological data. But ML opens new doors, raises new opportunities, and yes, poses new challenges.
Take for example the field of genomics. Computing has been important to genomics since its inception, but ML adds new capabilities and disrupts old paradigms. When Google researchers began working in this area, the idea of using deep learning to help infer genetic variants from sequencer output was considered far-fetched by many experts. Today, this ML approach is considered state-of-the-art. But the future holds an even more important role for ML — genomics companies are developing new sequencing instruments that are more accurate and faster, but also present new inference challenges. Our release of open-source software DeepConsensus and, in collaboration with UCSC, PEPPER-DeepVariant, supports these new instruments with cutting-edge informatics. We hope that more rapid sequencing can lead to near term applicability with impact for real patients.
A schematic of the Transformer architecture for DeepConsensus, which corrects sequencing errors to improve yield and correctness.
There are other opportunities to use ML to accelerate our use of genomic information for personalized health outside of processing the sequencer data. Large biobanks of extensively phenotyped and sequenced individuals can revolutionize how we understand and manage genetic predisposition to disease. Our ML-based phenotyping method improves the scalability of converting large imaging and text datasets into phenotypes usable for genetic association studies, and our DeepNull method better leverages large phenotypic data for genetic discovery. We are happy to release both as open-source methods for the scientific community.
The process for generating large-scale quantification of anatomical and disease traits for combination with genomic data in Biobanks.
Just as ML helps us see hidden characteristics of genomics data, it can help us discover new information and glean new insights from other health data types as well. Diagnosis of disease is often about identifying a pattern, quantifying a correlation, or recognizing a new instance of a larger class — all tasks at which ML excels. Google researchers have used ML to tackle a wide range of such problems, but perhaps none of these has progressed farther than the applications of ML to medical imaging.
In fact, Google’s 2016 paper describing the application of deep learning to the screening for diabetic retinopathy, was selected by the editors of the Journal of the American Medical Association (JAMA) as one of the top 10 most influential papers of the decade — not just the most influential papers on ML and health, the most influential JAMA papers of the decade overall. But the strength of our research doesn’t end at contributions to the literature, but extends to our ability to build systems operating in the real world. Through our global network of deployment partners, this same program has helped screen tens of thousands of patients in India, Thailand, Germany and France who might otherwise have been untested for this vision-threatening disease.
We expect to see this same pattern of assistive ML systems deployed to improve breast cancer screening, detect lung cancer, accelerate radiotherapy treatments for cancer, flag abnormal X-rays, and stage prostate cancer biopsies. Each domain presents new opportunities to be helpful. ML-assisted colonoscopy procedures are a particularly interesting example of going beyond the basics. Colonoscopies are not just used to diagnose colon cancer — the removal of polyps during the procedure are the front line of halting disease progression and preventing serious illness. In this domain we’ve demonstrated that ML can help ensure doctors don’t miss polyps, can help detect elusive polyps, and can add new dimensions of quality assurance, like coverage mapping through the application of simultaneous localization and mapping techniques. In collaboration with Shaare Zedek Medical Center in Jerusalem, we’ve shown these systems can work in real time, detecting an average of one polyp per procedure that would have otherwise been missed, with fewer than four false alarms per procedure.
Sample chest X-rays (CXR) of true and false positives, and true and false negatives for (A) general abnormalities, (B) tuberculosis, and (C) COVID-19. On each CXR, red outlines indicate areas on which the model focused to identify abnormalities (i.e., the class activation map), and yellow outlines refer to regions of interest identified by a radiologist.
Another ambitious healthcare initiative, Care Studio, uses state-of-the-art ML and advanced NLP techniques to analyze structured data and medical notes, presenting clinicians with the most relevant information at the right time — ultimately helping them deliver more proactive and accurate care.
The custom ML model for contactless sleep sensing efficiently processes a continuous stream of 3D radar tensors (summarizing activity over a range of distances, frequencies, and time) to automatically compute probabilities for the likelihood of user presence and wakefulness (awake or asleep).
ML Applications for the Climate Crisis
Another realm of paramount importance is climate change, which is an incredibly urgent threat for humanity. We need to all work together to bend the curve of harmful emissions to ensure a safe and prosperous future. Better information about the climate impact of different choices can help us tackle this challenge in a number of different ways.
To this end, we recently rolled out eco-friendly routing in Google Maps, which we estimate will save about 1 million tons of CO2 emissions per year (the equivalent of removing more than 200,000 cars from the road). A recent case study shows that using Google Maps directions in Salt Lake City results in both faster and more emissions-friendly routing, which saves 1.7% of CO2 emissions and 6.5% travel time. In addition, making our Maps products smarter about electric vehicles can help alleviate range anxiety, encouraging people to switch to emissions-free vehicles. We are also working with multiple municipalities around the world to use aggregated historical traffic data to help suggest improved traffic light timing settings, with an early pilot study in Israel and Brazil showing a 10-20% reduction in fuel consumption and delay time at the examined intersections.
With eco-friendly routing, Google Maps will show you the fastest route and the one that’s most fuel-efficient — so you can choose whichever one works best for you.
On a longer time scale, fusion holds promise as a game-changing renewable energy source. In a long-standing collaboration with TAE Technologies, we have used ML to help maintain stable plasmas in their fusion reactor by suggesting settings of the more than 1000 relevant control parameters. With our collaboration, TAE achieved their major goals for their Norman reactor, which brings us a step closer to the goal of breakeven fusion. The machine maintains a stable plasma at 30 million Kelvin (don’t touch!) for 30 milliseconds, which is the extent of available power to its systems. They have completed a design for an even more powerful machine, which they hope will demonstrate the conditions necessary for breakeven fusion before the end of the decade.
We’re also expanding our efforts to address wildfires and floods, which are becoming more common (like millions of Californians, I’m having to adapt to having a regular “fire season”). Last year, we launched a wildfire boundary map powered by satellite data to help people in the U.S. easily understand the approximate size and location of a fire — right from their device. Building on this, we’re now bringing all of Google’s wildfire information together and launching it globally with a new layer on Google Maps. We have been applying graph optimization algorithms to help optimize fire evacuation routes to help keep people safe in the presence of rapidly advancing fires. In 2021, our Flood Forecasting Initiative expanded its operational warning systems to cover 360 million people, and sent more than 115 million notifications directly to the mobile devices of people at risk from flooding, more than triple our outreach in the previous year. We also deployed our LSTM-based forecast models and the new Manifold inundation model in real-world systems for the first time, and shared a detailed description of all components of our systems.
The wildfire layer in Google Maps provides people with critical, up-to-date information in an emergency.
We’re also working hard on our own set of sustainability initiatives. Google was the first major company to become carbon neutral in 2007. We were also the first major company to match our energy use with 100 percent renewable energy in 2017. We operate the cleanest global cloud in the industry, and we’re the world’s largest corporate purchaser of renewable energy. Further, in 2020 we became the first major company to make a commitment to operate on 24/7 carbon-free energy in all our data centers and campuses worldwide. This is far more challenging than the traditional approach of matching energy usage with renewable energy, but we’re working to get this done by 2030. Carbon emission from ML model training is a concern for the ML community, and we have shown that making good choices about model architecture, datacenter, and ML accelerator type can reduce the carbon footprint of training by ~100-1000x.
Trend 5: Deeper and Broader Understanding of ML As ML is used more broadly across technology products and society more generally, it is imperative that we continue to develop new techniques to ensure that it is applied fairly and equitably, and that it benefits all people and not just select subsets. This is a major focus for our Responsible AI and Human-Centered Technology research group and an area in which we conduct research on a variety of responsibility-related topics.
One area of focus is recommendation systems that are based on user activity in online products. Because these recommendation systems are often composed of multiple distinct components, understanding their fairness properties often requires insight into individual components as well as how the individual components behave when combined together. Recent work has helped to better understand these relationships, revealing ways to improve the fairness of both individual components and the overall recommendation system. In addition, when learning from implicit user activity, it is also important for recommendation systems to learn in an unbiased manner, since the straightforward approach of learning from items that were shown to previous users exhibits well-known forms of bias. Without correcting for such biases, for example, items that were shown in more prominent positions to users tend to get recommended to future users more often.
As in recommendation systems, surrounding context is important in machine translation. Because most machine translation systems translate individual sentences in isolation, without additional surrounding context, they can often reinforce biases related to gender, age or other areas. In an effort to address some of these issues, we have a long-standing line of research on reducing gender bias in our translation systems, and to help the entire translation community, last year we released a dataset to study gender bias in translation based on translations of Wikipedia biographies.
Another common problem in deploying machine learning models is distributional shift: if the statistical distribution of data on which the model was trained is not the same as that of the data the model is given as input, the model’s behavior can sometimes be unpredictable. In recent work, we employ the Deep Bootstrap framework to compare the real world, where there is finite training data, to an "ideal world", where there is infinite data. Better understanding of how a model behaves in these two regimes (real vs. ideal) can help us develop models that generalize better to new settings and exhibit less bias towards fixed training datasets.
Although work on ML algorithms and model development gets significant attention, data collection and dataset curation often gets less. But this is an important area, because the data on which an ML model is trained can be a potential source of bias and fairness issues in downstream applications. Analyzing such data cascades in ML can help identify the many places in the lifecycle of an ML project that can have substantial influence on the outcomes. This research on data cascades has led to evidence-backed guidelines for data collection and evaluation in the revised PAIR Guidebook, aimed at ML developers and designers.
Arrows of different color indicate various types of data cascades, each of which typically originate upstream, compound over the ML development process, and manifest downstream.
A screenshot from Know Your Data showing the relationship between words that describe attractiveness and gendered words. For example, “attractive” and “male/man/boy” co-occur 12 times, but we expect ~60 times by chance (the ratio is 0.2x). On the other hand, “attractive” and “female/woman/girl” co-occur 2.62 times more than chance.
Understanding dynamics of benchmark dataset usage is also important, given the central role they play in the organization of ML as a field. Although studies of individual datasets have become increasingly common, the dynamics of dataset usage across the field have remained underexplored. In recent work, we published the first large scale empirical analysis of dynamics of dataset creation, adoption, and reuse. This work offers insights into pathways to enable more rigorous evaluations, as well as more equitable and socially informed research.
Creating public datasets that are more inclusive and less biased is an important way to help improve the field of ML for everyone. In 2016, we released the Open Images dataset, a collection of ~9 million images annotated with image labels spanning thousands of object categories and bounding box annotations for 600 classes. Last year, we introduced the More Inclusive Annotations for People (MIAP) dataset in the Open Images Extended collection. The collection contains more complete bounding box annotations for the person class hierarchy, and each annotation is labeled with fairness-related attributes, including perceived gender presentation and perceived age range. With the increasing focus on reducing unfair bias as part of responsible AI research, we hope these annotations will encourage researchers already leveraging the Open Images dataset to incorporate fairness analysis in their research.
Because we also know that our teams are not the only ones creating datasets that can improve machine learning, we have built Dataset Search to help users discover new and useful datasets, wherever they might be on the Web.
Tackling various forms of abusive behavior online, such as toxic language, hate speech, and misinformation, is a core priority for Google. Being able to detect such forms of abuse reliably, efficiently, and at scale is of critical importance both to ensure that our platforms are safe and also to avoid the risk of reproducing such negative traits through language technologies that learn from online discourse in an unsupervised fashion. Google has pioneered work in this space through the Perspective API tool, but the nuances involved in detecting toxicity at scale remains a complex problem. In recent work, in collaboration with various academic partners, we introduced a comprehensive taxonomy to reason about the changing landscape of online hate and harassment. We also investigated how to detect covert forms of toxicity, such as microaggressions, that are often ignored in online abuse interventions, studied how conventional approaches to deal with disagreements in data annotations of such subjective concepts might marginalize minority perspectives, and proposed a new disaggregated modeling approach that uses a multi-task framework to tackle this issue. Furthermore, through qualitative research and network-level content analysis, Google’s Jigsaw team, in collaboration with researchers at George Washington University, studied how hate clusters spread disinformation across social media platforms.
Another potential concern is that ML language understanding and generation models can sometimes also produce results that are not properly supported by evidence. To confront this problem in question answering, summarization, and dialog, we developed a new framework for measuring whether results can be attributed to specific sources. We released annotation guidelines and demonstrated that they can be reliably used in evaluating candidate models.
Interactive analysis and debugging of models remains key to responsible use of ML. We have updated our Language Interpretability Tool with new capabilities and techniques to advance this line of work, including support for image and tabular data, a variety of features carried over from our previous work on the What-If Tool, and built-in support for fairness analysis through the technique of Testing with Concept Activation Vectors. Interpretability and explainability of ML systems more generally is also a key part of our Responsible AI vision; in collaboration with DeepMind, we made headway in understanding the acquisition of human chess concepts in the self-trained AlphaZero chess system.
Explore what AlphaZero might have learned about playing chess using this online tool.
We are also working hard to broaden the perspective of Responsible AI beyond western contexts. Our recent research examines how various assumptions of conventional algorithmic fairness frameworks based on Western institutions and infrastructures may fail in non-Western contexts and offers a pathway for recontextualizing fairness research in India along several directions. We are actively conducting survey research across several continents to better understand perceptions of and preferences regarding AI. Western framing of algorithmic fairness research tends to focus on only a handful of attributes, thus biases concerning non-Western contexts are largely ignored and empirically under-studied. To address this gap, in collaboration with the University of Michigan, we developed a weakly supervised method to robustly detect lexical biases in broader geo-cultural contexts in NLP models that reflect human judgments of offensive and inoffensive language in those geographic contexts.
Furthermore, we have explored applications of ML to contexts valued in the Global South, including developing a proposal for farmer-centered ML research. Through this work, we hope to encourage the field to be thoughtful about how to bring ML-enabled solutions to smallholder farmers in ways that will improve their lives and their communities.
Involving community stakeholders at all stages of the ML pipeline is key to our efforts to develop and deploy ML responsibly and keep us focused on tackling the problems that matter most. In this vein, we held a Health Equity Research Summit among external faculty, non-profit organization leads, government and NGO representatives, and other subject matter experts to discuss how to bring more equity into the entire ML ecosystem, from the way we approach problem-solving to how we assess the impact of our efforts.
Datasets Recognizing the value of open datasets to the general advancement of ML and related fields of research, we continue to grow our collection of open source datasets and resources and expand our global index of open datasets in Google Dataset Search. This year, we have released a number of datasets and tools across a range of research areas:
Wikipedia-based Image Text dataset for multimodal multilingual ML
Research Community Interaction To realize our goal for a more robust and comprehensive understanding of ML and related technologies, we actively engage with the broader research community. In 2021, we published over 750 papers, nearly 600 of which were presented at leading research conferences. Google Research sponsored over 150 conferences, and Google researchers contributed directly by serving on program committees and organizing workshops, tutorials and numerous other activities aimed at collectively advancing the field. To learn more about our contributions to some of the larger research conferences this year, please see our recent conference blog posts. In addition, we hosted 19 virtual workshops (like the 2021 Quantum Summer Symposium), which allowed us to further engage with the academic community by generating new ideas and directions for the research field and advancing research initiatives.
In 2021, Google Research also directly supported external research with $59M in funding, including $23M through Research programs to faculty and students, and $20M in university partnerships and outreach. This past year, we introduced new funding and collaboration programs that support academics all over the world who are doing high impact research. We funded 86 early career faculty through our Research Scholar Program to support general advancements in science, and funded 34 faculty through our Award for Inclusion Research Program who are doing research in areas like accessibility, algorithmic fairness, higher education and collaboration, and participatory ML. In addition to the research we are funding, we welcomed 85 faculty and post-docs, globally, through our Visiting Researcher program, to come to Google and partner with us on exciting ideas and shared research challenges. We also selected a group of 74 incredibly talented PhD student researchers to receive Google PhD Fellowships and mentorship as they conduct their research.
As part of our ongoing racial equity commitments, making computer science (CS) research more inclusive continues to be a top priority for us. In 2021, we continued expanding our efforts to increase the diversity of Ph.D. graduates in computing. For example, the CS Research Mentorship Program (CSRMP), an initiative by Google Research to support students from historically marginalized groups (HMGs) in computing research pathways, graduated 590 mentees, 83% of whom self-identified as part of an HMG, who were supported by 194 Google mentors — our largest group to date! In October, we welcomed 35 institutions globally leading the way to engage 3,400+ students in computing research as part of the 2021 exploreCSR cohort. Since 2018, this program has provided faculty with funding, community, evaluation and connections to Google researchers in order to introduce students from HMGs to the world of CS research. We are excited to expand this program to more international locations in 2022.
Other Work In writing these retrospectives, I try to focus on new research work that has happened (mostly) in the past year while also looking ahead. In past years’ retrospectives, I’ve tried to be more comprehensive, but this time I thought it could be more interesting to focus on just a few themes. We’ve also done great work in many other research areas that don’t fit neatly into these themes. If you’re interested, I encourage you to check out our research publications by area below or by year (and if you’re interested in quantum computing, our Quantum team recently wrote a retrospective of their work in 2021):
Conclusion Research is often a multi-year journey to real-world impact. Early stage research work that happened a few years ago is now having a dramatic impact on Google’s products and across the world. Investments in ML hardware accelerators like TPUs and in software frameworks like TensorFlow and JAX have borne fruit. ML models are increasingly prevalent in many different products and features at Google because their power and ease of expression streamline experimentation and productionization of ML models in performance-critical environments. Research into model architectures to create Seq2Seq, Inception, EfficientNet, and Transformer or algorithmic research like batch normalization and distillation is driving progress in the fields of language understanding, vision, speech, and others. Basic capabilities like better language and visual understanding and speech recognition can be transformational, and as a result, these sorts of models are widely deployed for a wide variety of problems in many of our products including Search, Assistant, Ads, Cloud, Gmail, Maps, YouTube, Workspace, Android, Pixel, Nest, and Translate.
These are truly exciting times in machine learning and computer science. Continued improvement in computers’ ability to understand and interact with the world around them through language, vision, and sound opens up entire new frontiers of how computers can help people accomplish things in the world. The many examples of progress along the five themes outlined in this post are waypoints in a long-term journey!
Acknowledgements Thanks to Alison Carroll, Alison Lentz, Andrew Carroll, Andrew Tomkins, Avinatan Hassidim, Azalia Mirhoseini, Barak Turovsky, Been Kim, Blaise Aguera y Arcas, Brennan Saeta, Brian Rakowski, Charina Chou, Christian Howard, Claire Cui, Corinna Cortes, Courtney Heldreth, David Patterson, Dipanjan Das, Ed Chi, Eli Collins, Emily Denton, Fernando Pereira, Genevieve Park, Greg Corrado, Ian Tenney, Iz Conroy, James Wexler, Jason Freidenfelds, John Platt, Katherine Chou, Kathy Meier-Hellstern, Kyle Vandenberg, Lauren Wilcox, Lizzie Dorfman, Marian Croak, Martin Abadi, Matthew Flegal, Meredith Morris, Natasha Noy, Negar Saei, Neha Arora, Paul Muret, Paul Natsev, Quoc Le, Ravi Kumar, Rina Panigrahy, Sanjiv Kumar, Sella Nevo, Slav Petrov, Sreenivas Gollapudi, Tom Duerig, Tom Small, Vidhya Navalpakkam, Vincent Vanhoucke, Vinodkumar Prabhakaran, Viren Jain, Yonghui Wu, Yossi Matias, and Zoubin Ghahramani for helpful feedback and contributions to this post, and to the entire Research and Health communities at Google for everyone’s contributions towards this work.
Posted by Cat Armato, Program Manager, Google Research
The International Conference on Computer Vision 2021 (ICCV 2021), one of the world's premier conferences on computer vision, starts this week. A Champion Sponsor and leader in computer vision research, Google will have a strong presence at ICCV 2021 with more than 50 research presentations and involvement in the organization of a number of workshops and tutorials.
If you are attending ICCV this year, we hope you’ll check out the work of our researchers who are actively pursuing the latest innovations in computer vision. Learn more about our research being presented in the list below (Google affilitation in bold).
Organizing Committee Diversity and Inclusion Chair: Negar Rostamzadeh Area Chairs: Andrea Tagliasacchi, Boqing Gong, Ce Liu, Dilip Krishnan, Jordi Pont-Tuset, Michael Rubinstein, Michael S. Ryoo, Negar Rostamzadeh, Noah Snavely, Rodrigo Benenson, Tsung-Yi Lin, Vittorio Ferrari





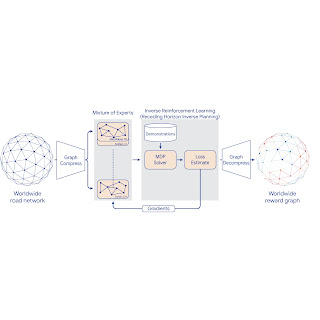













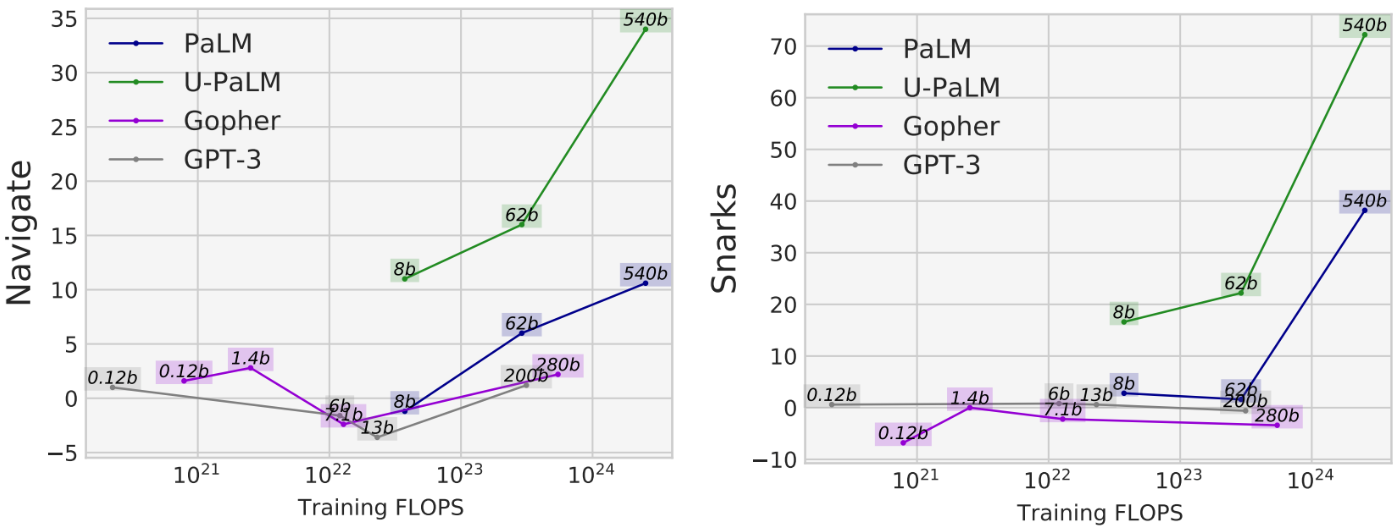







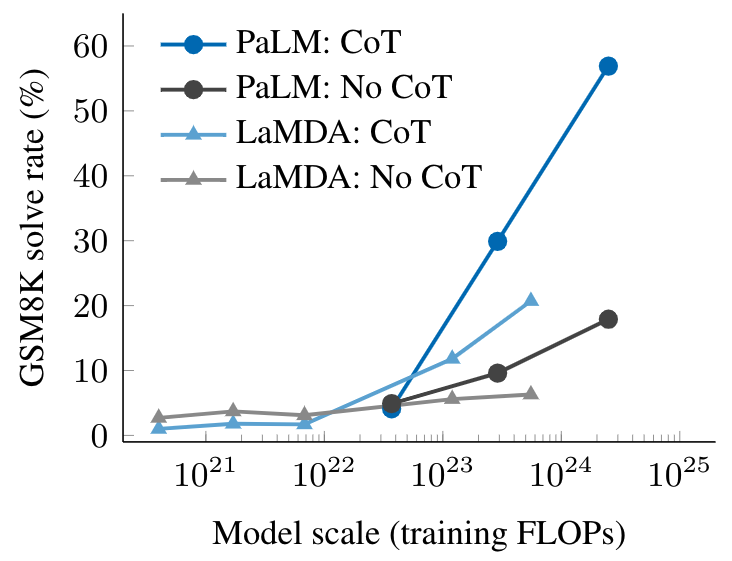









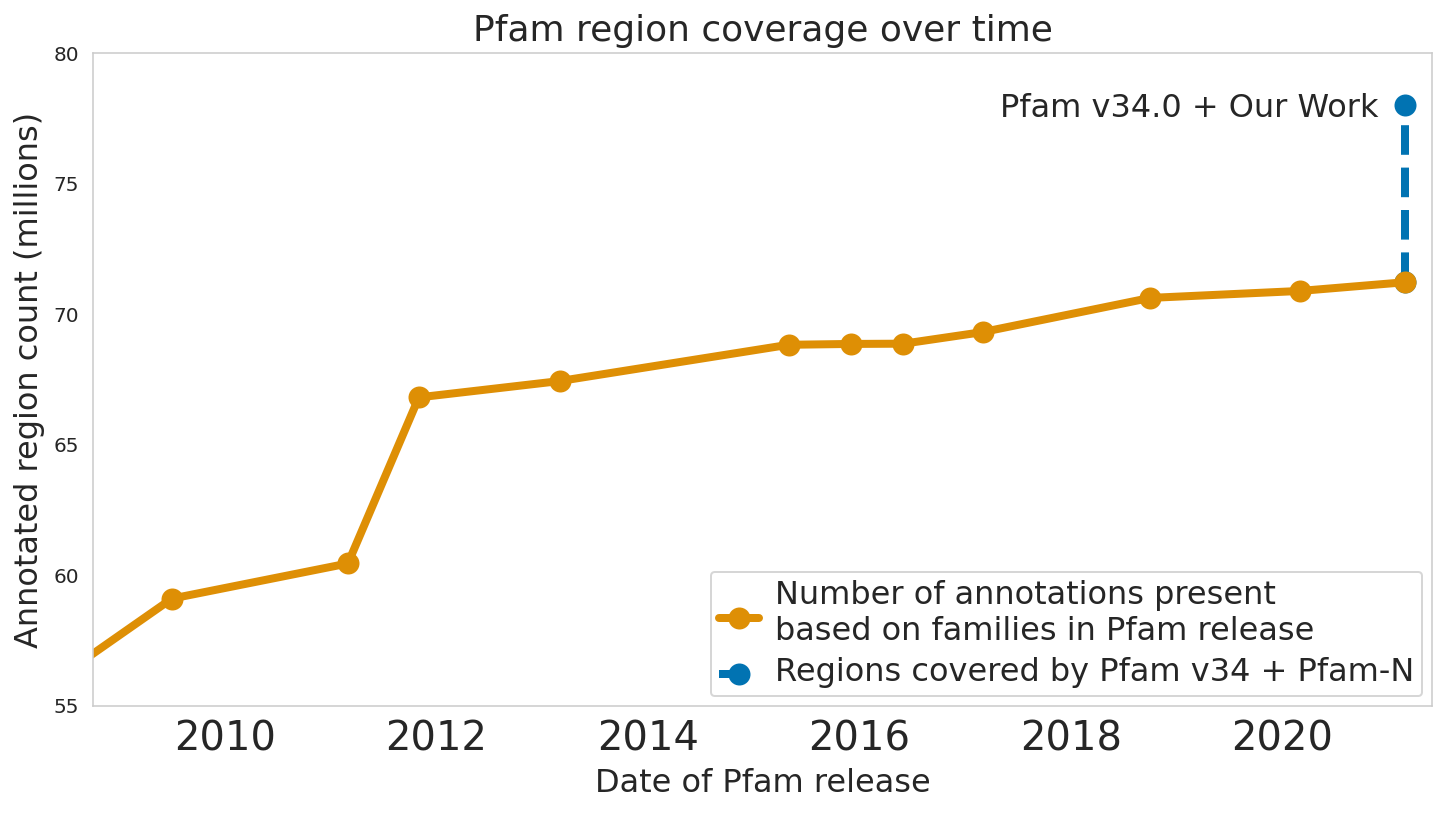
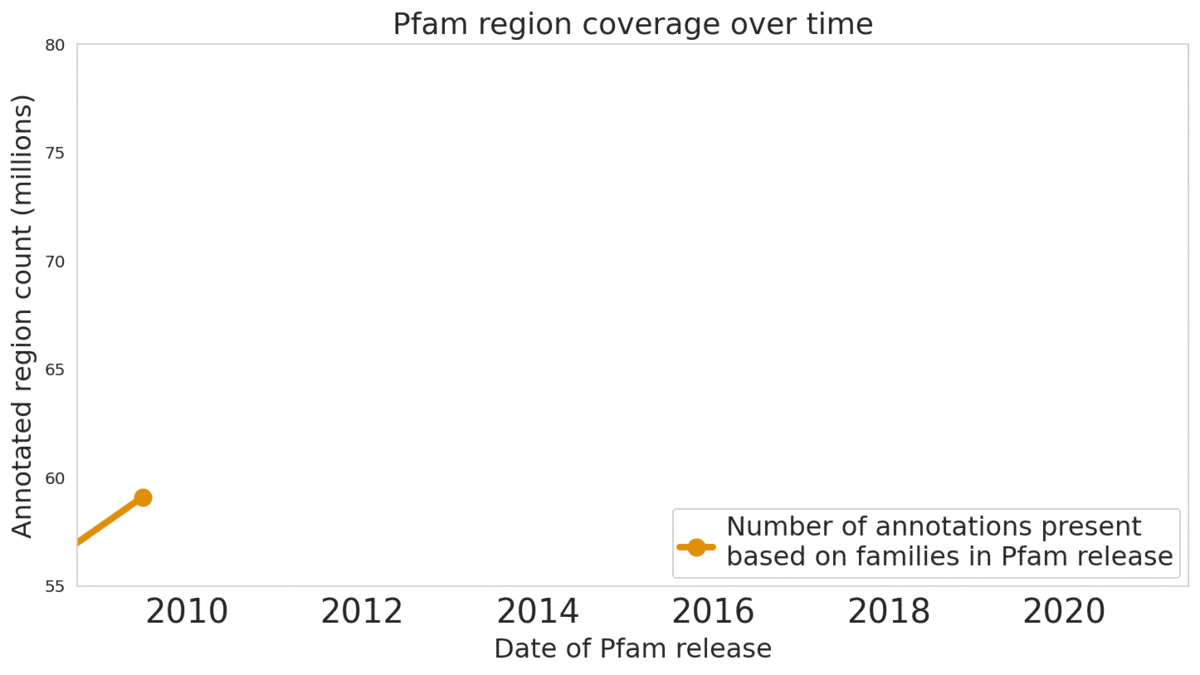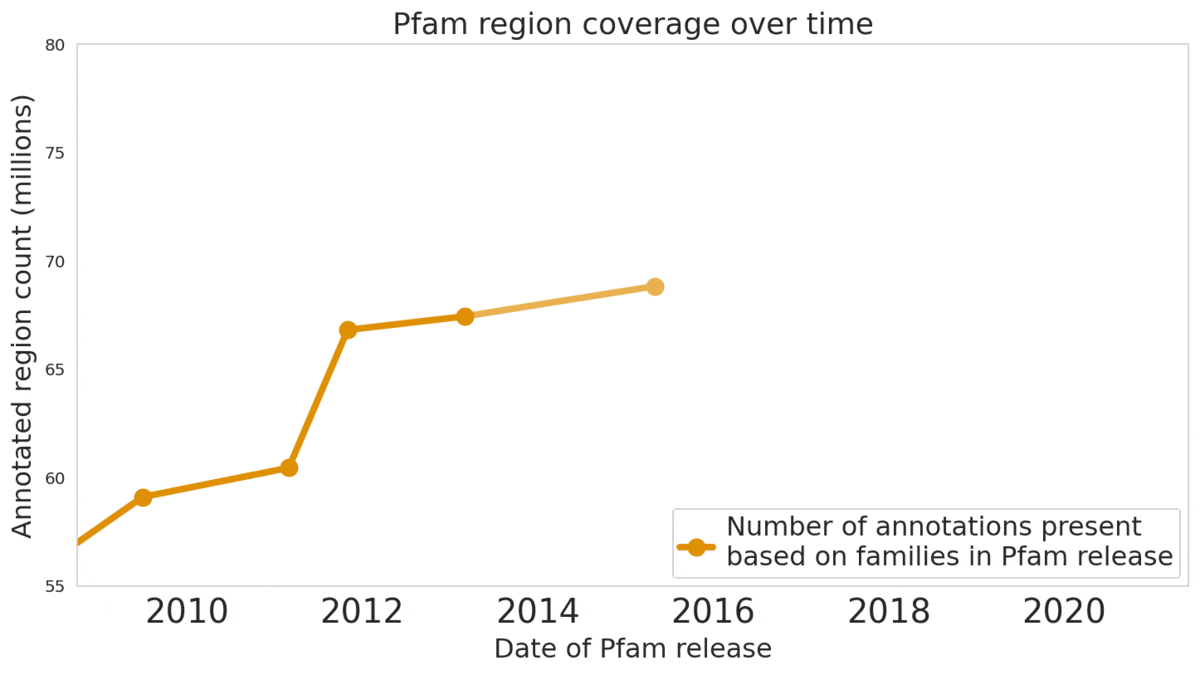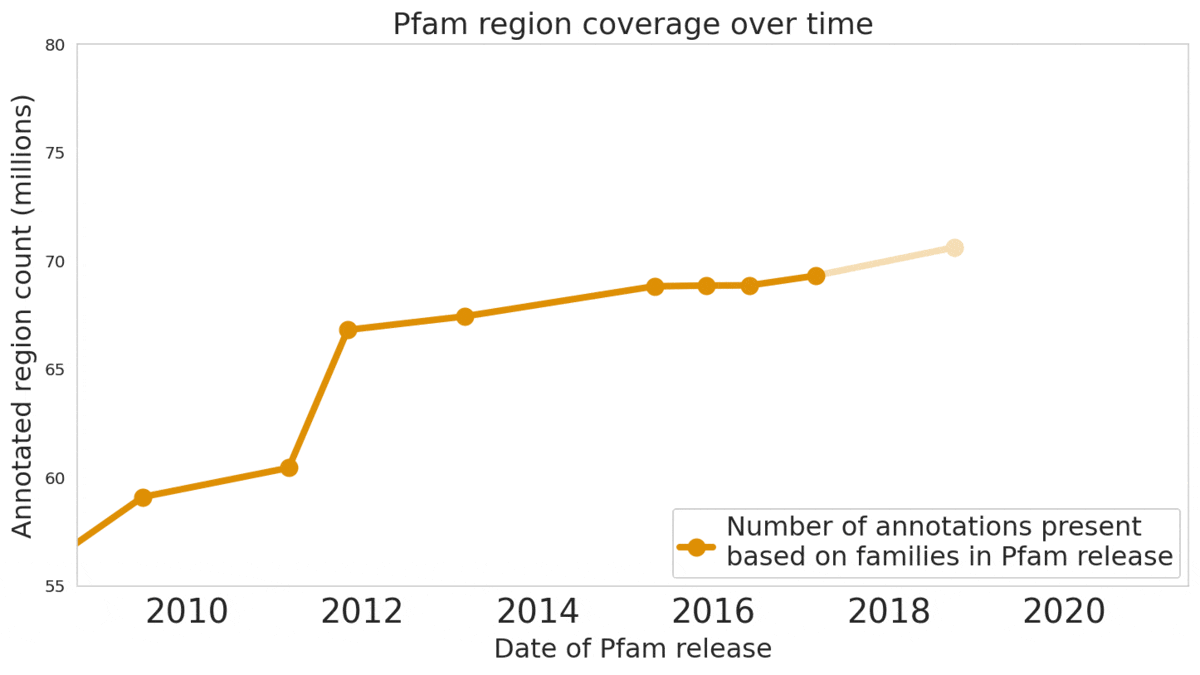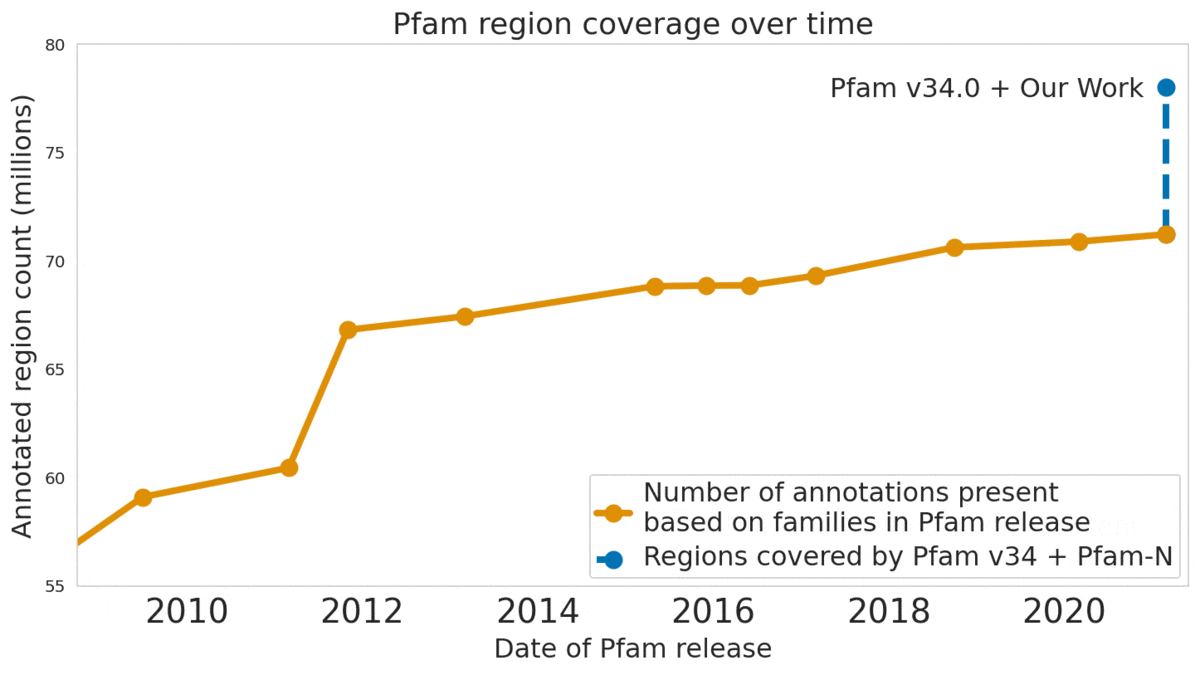
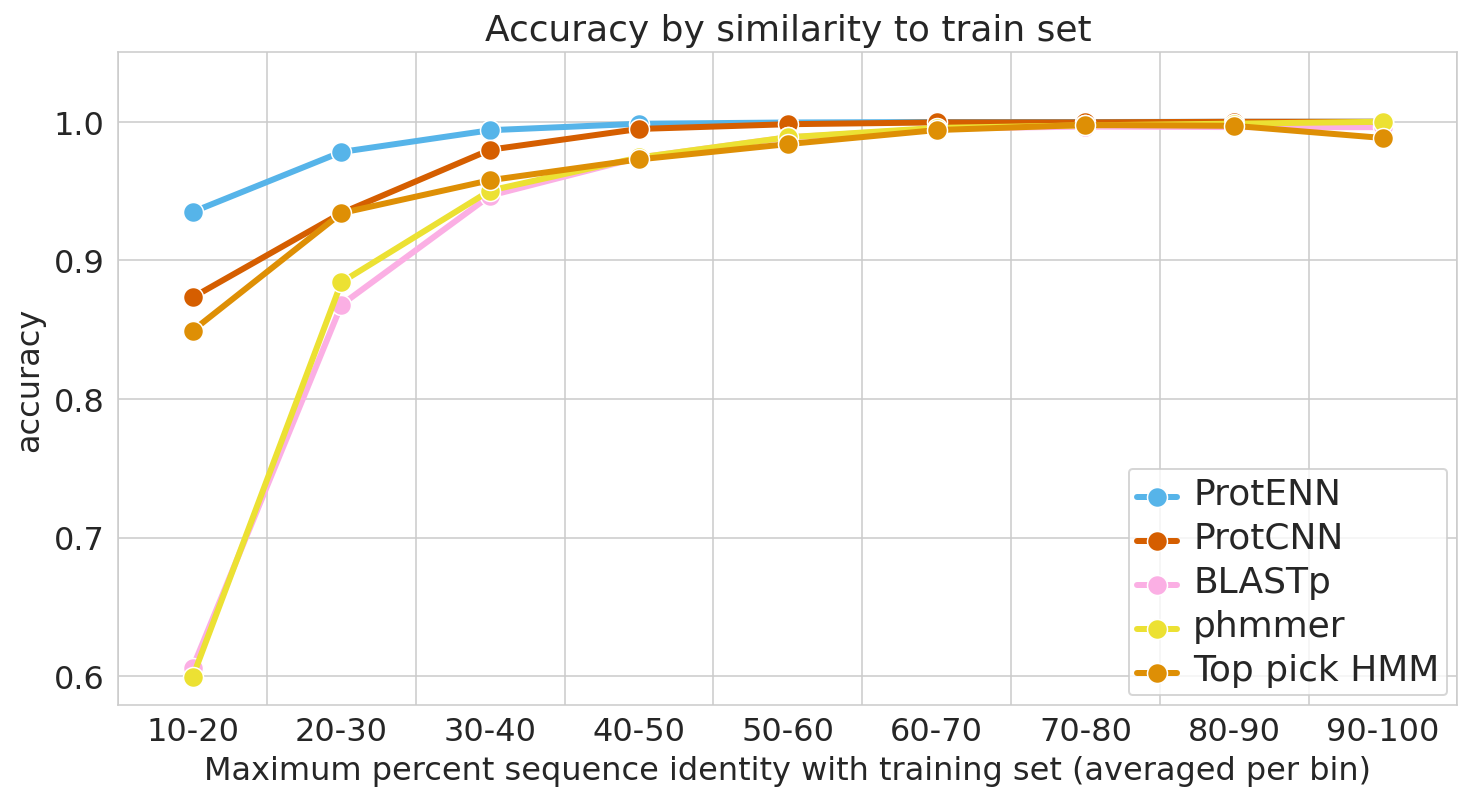


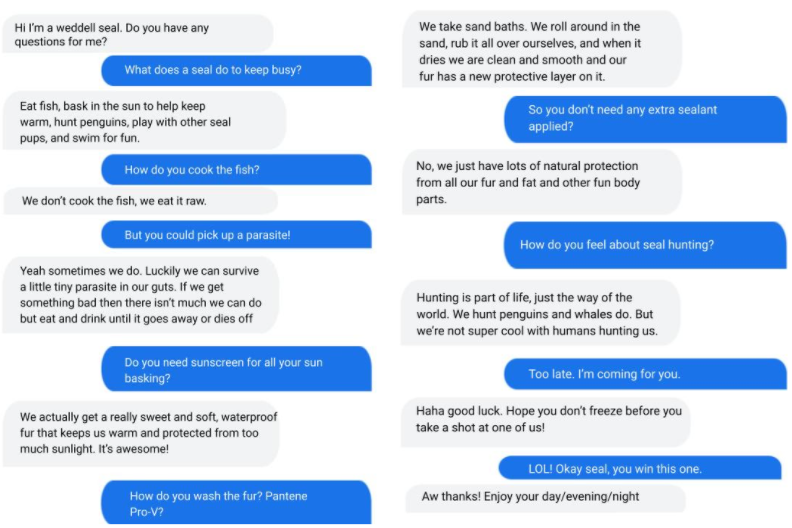


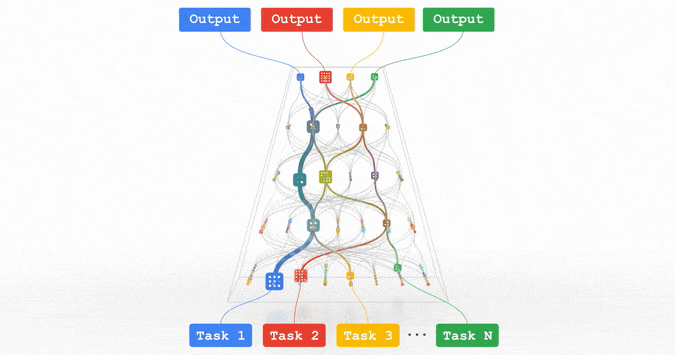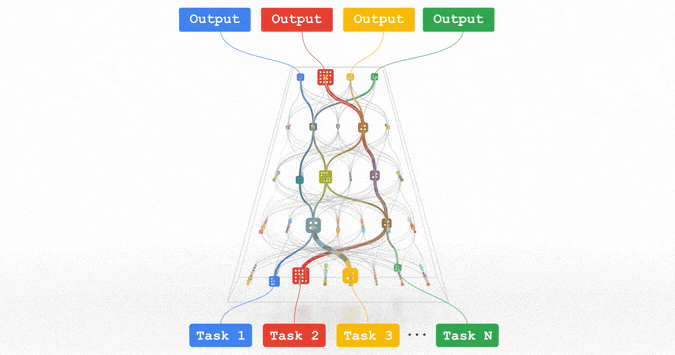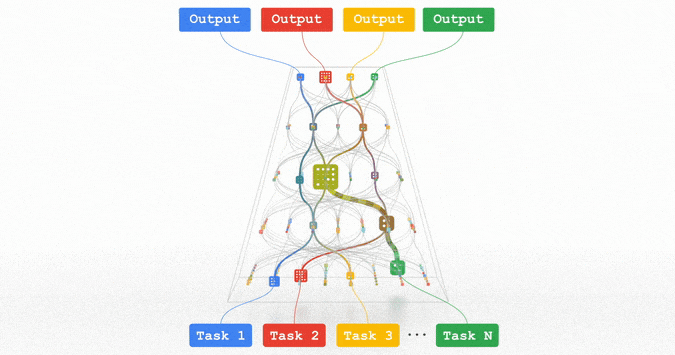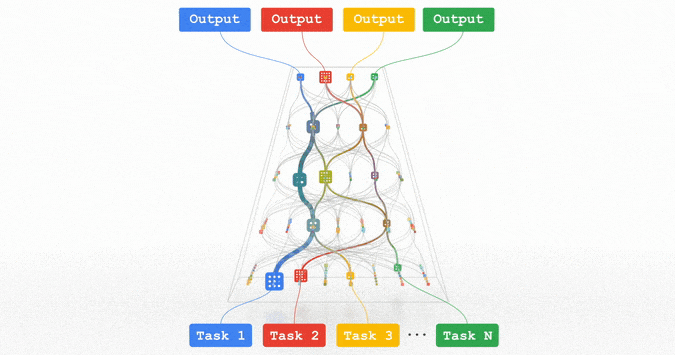

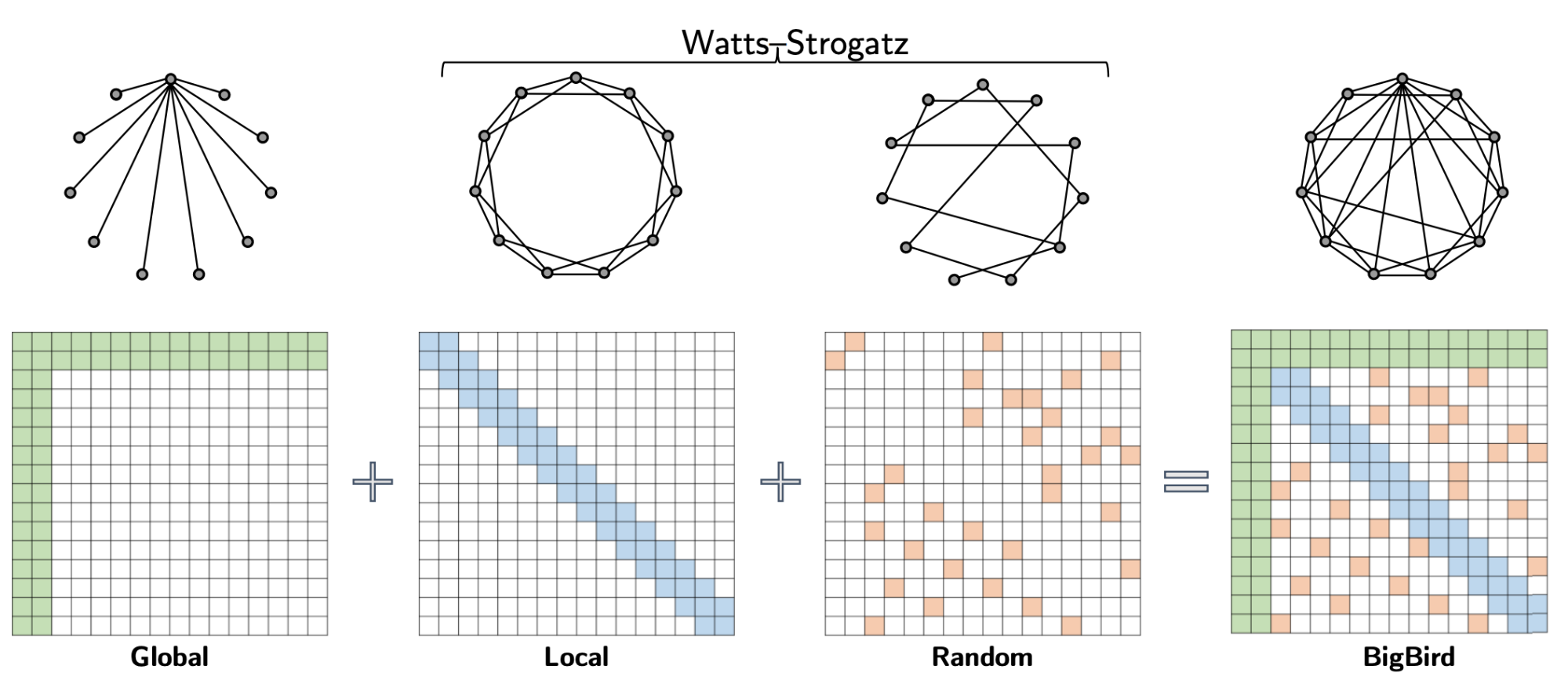

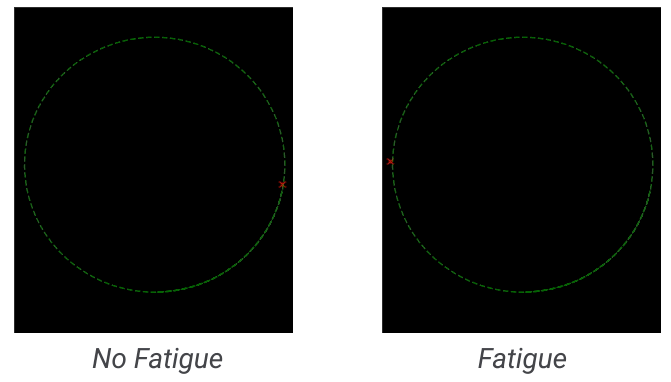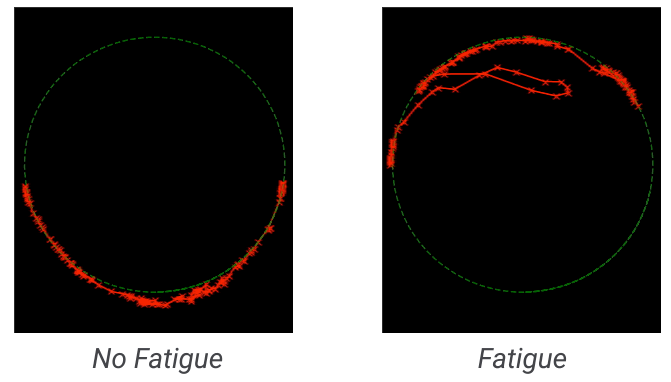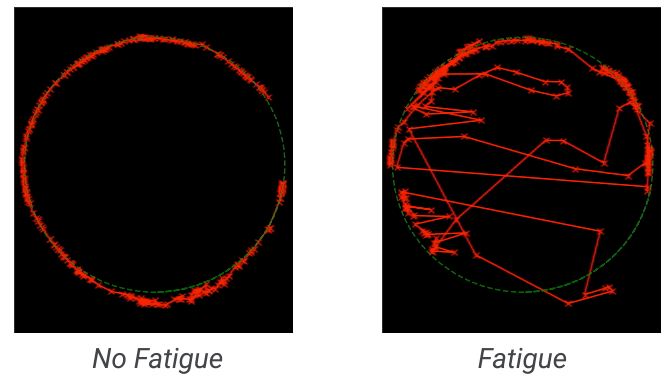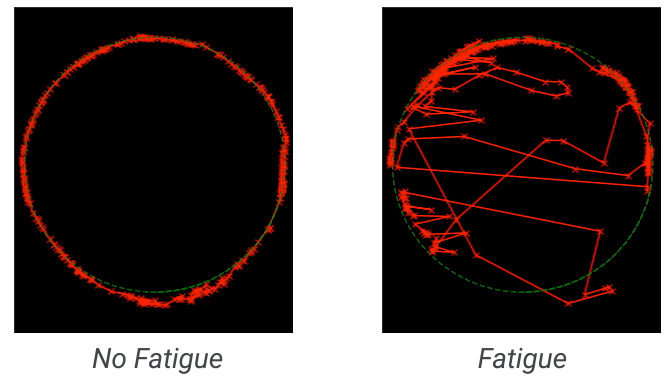

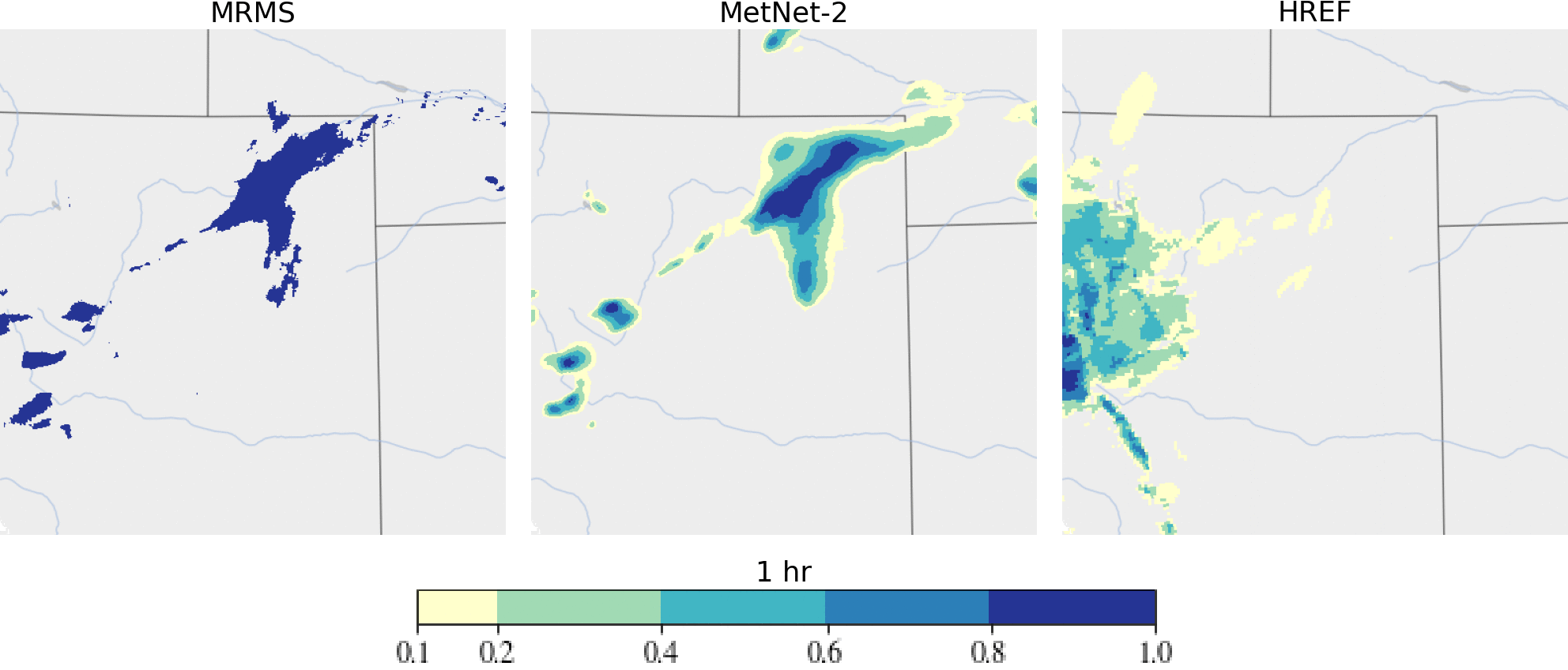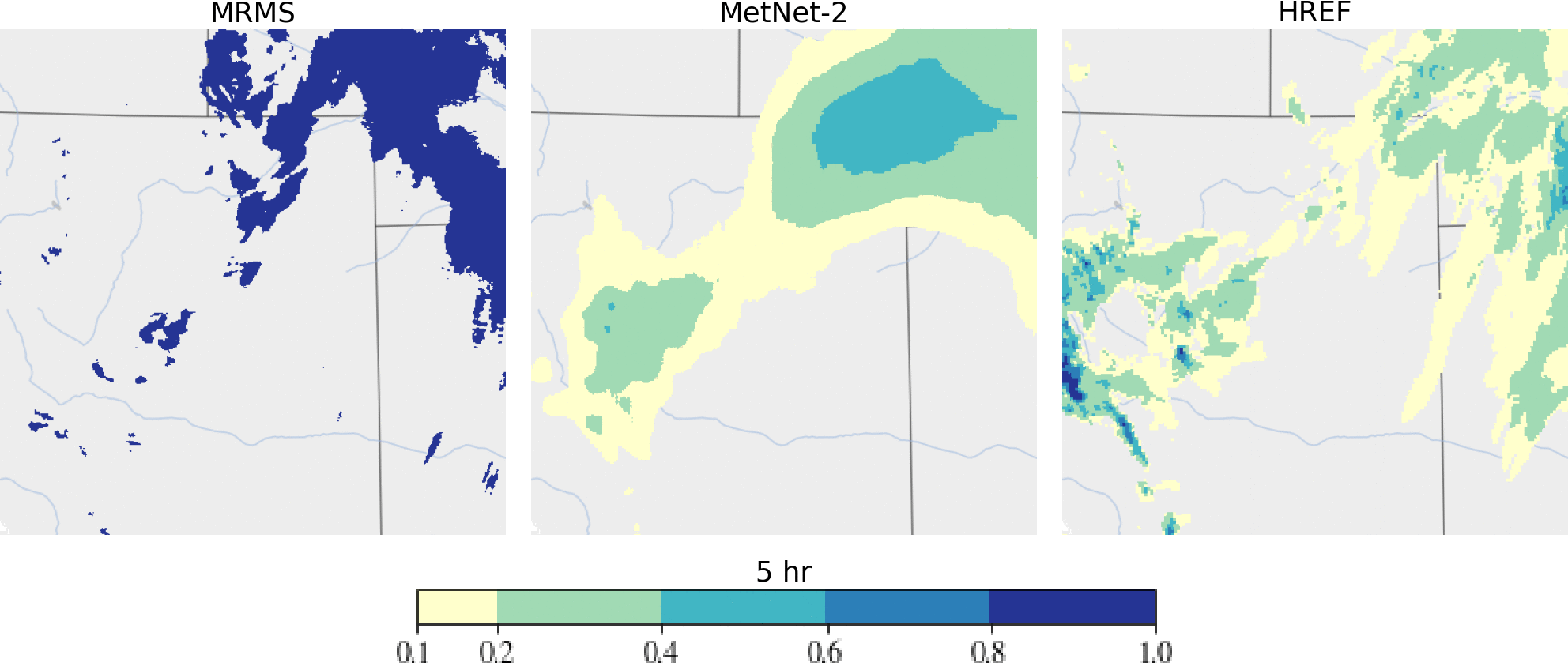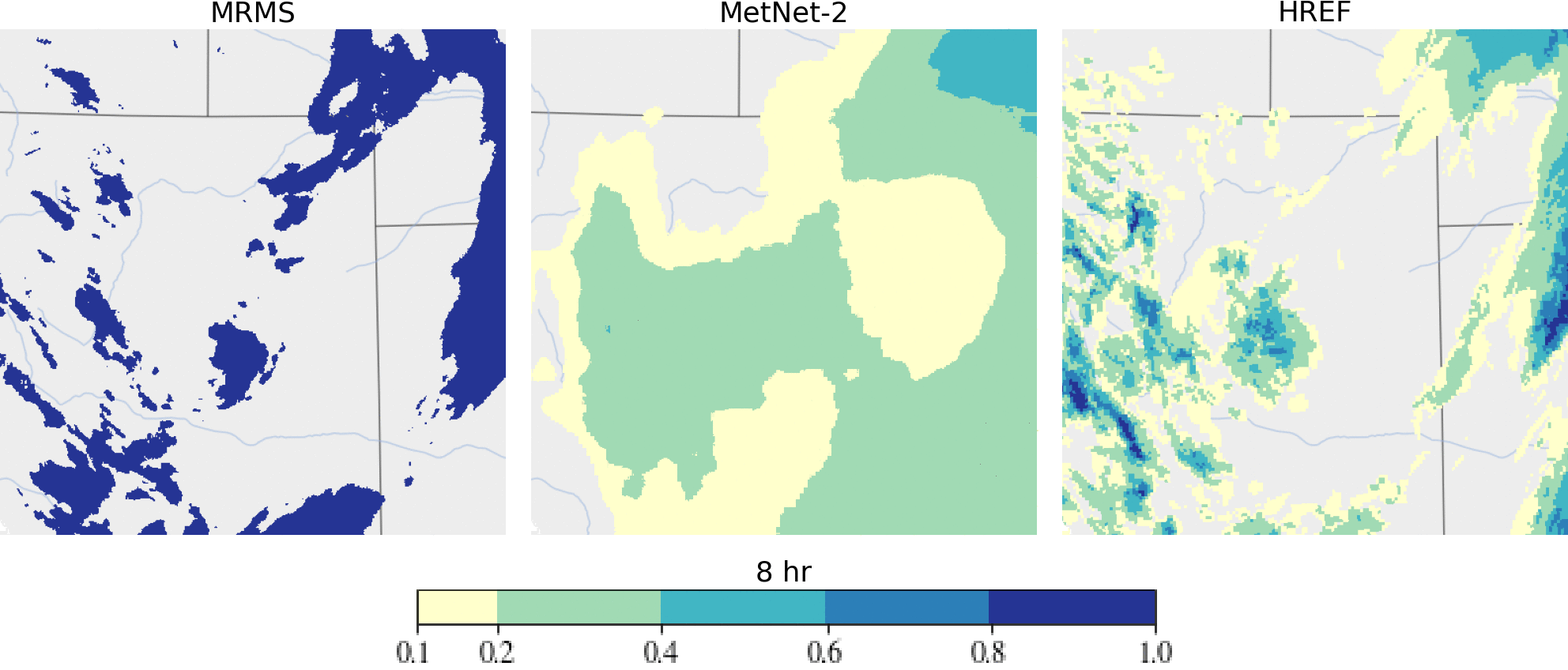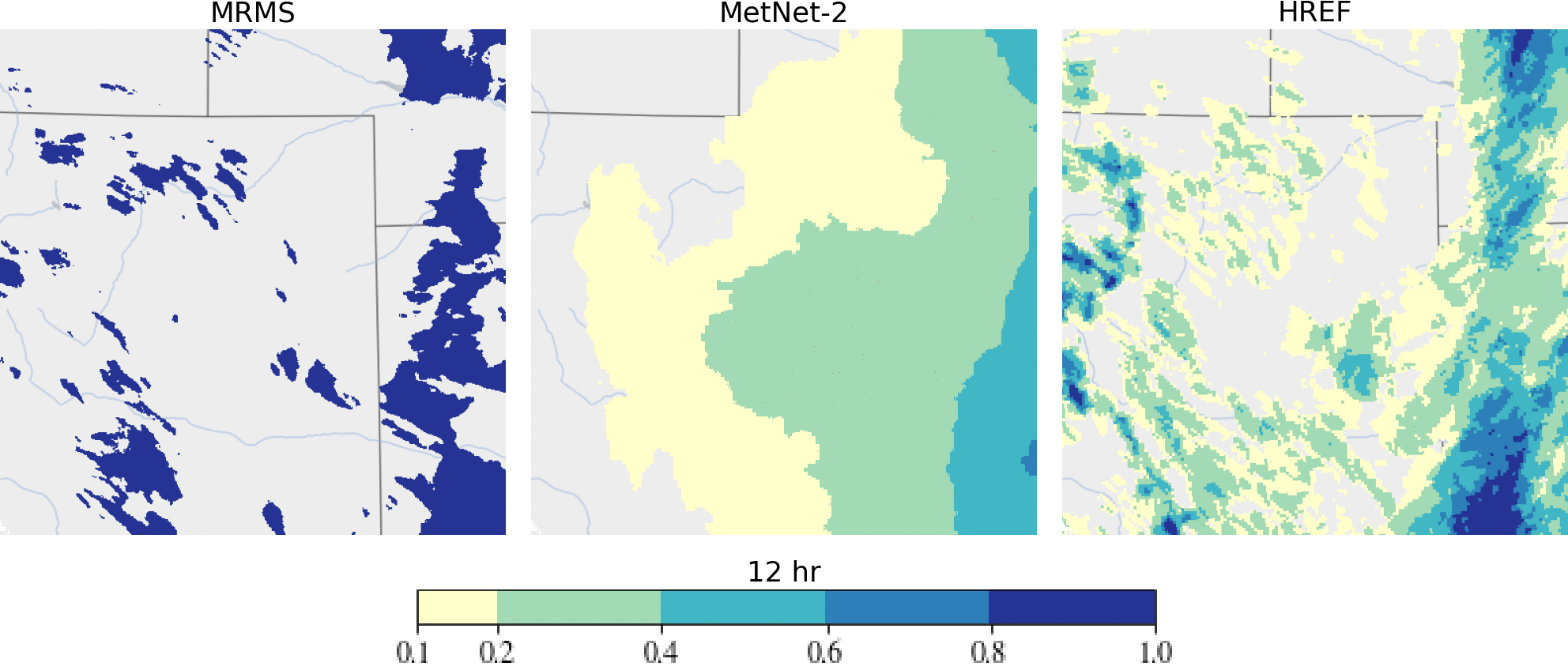


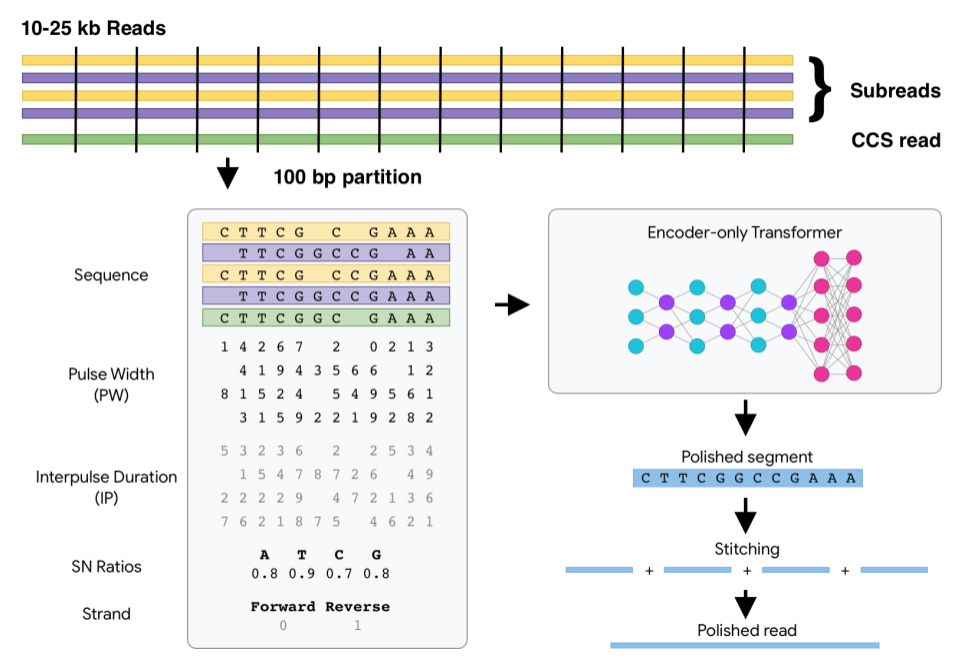

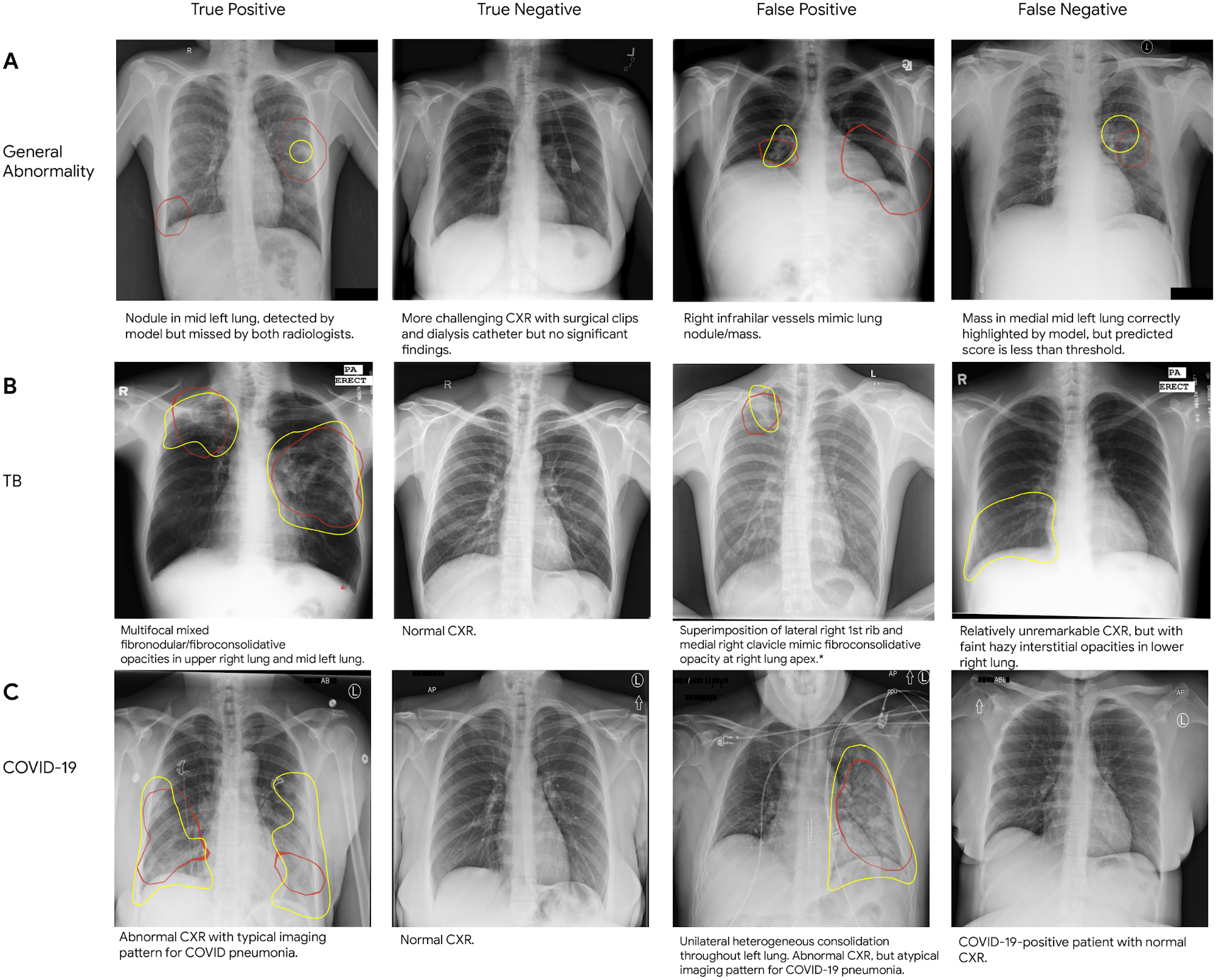
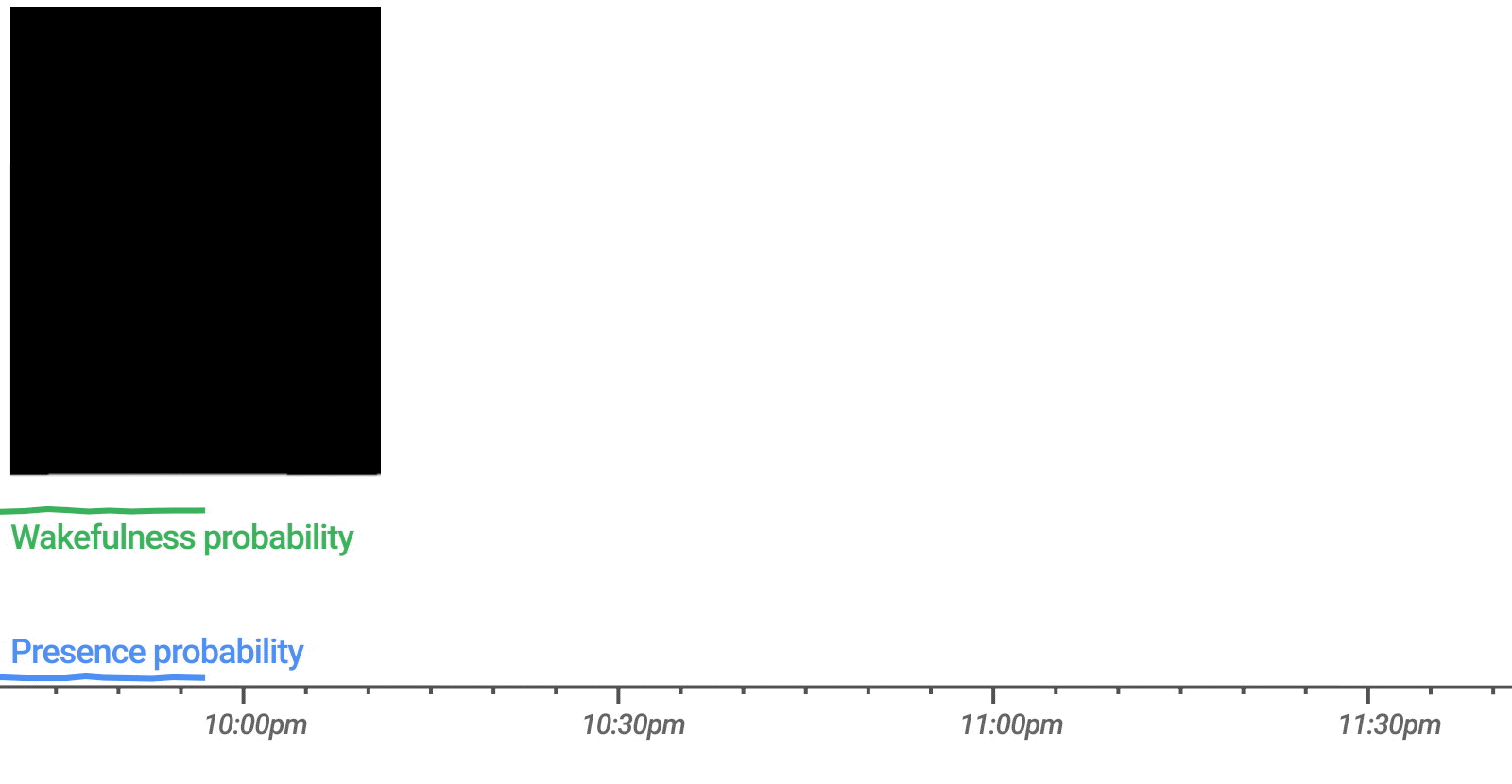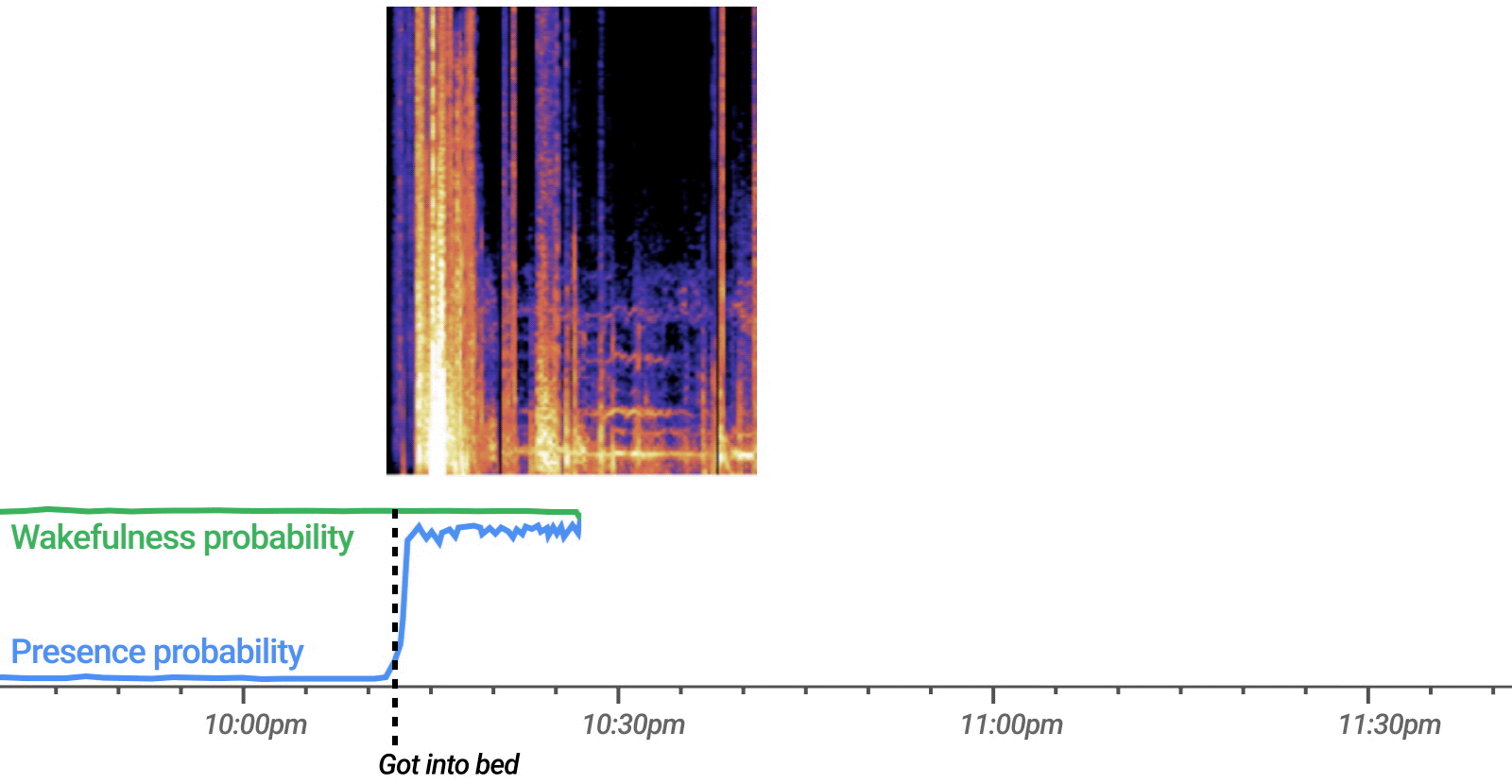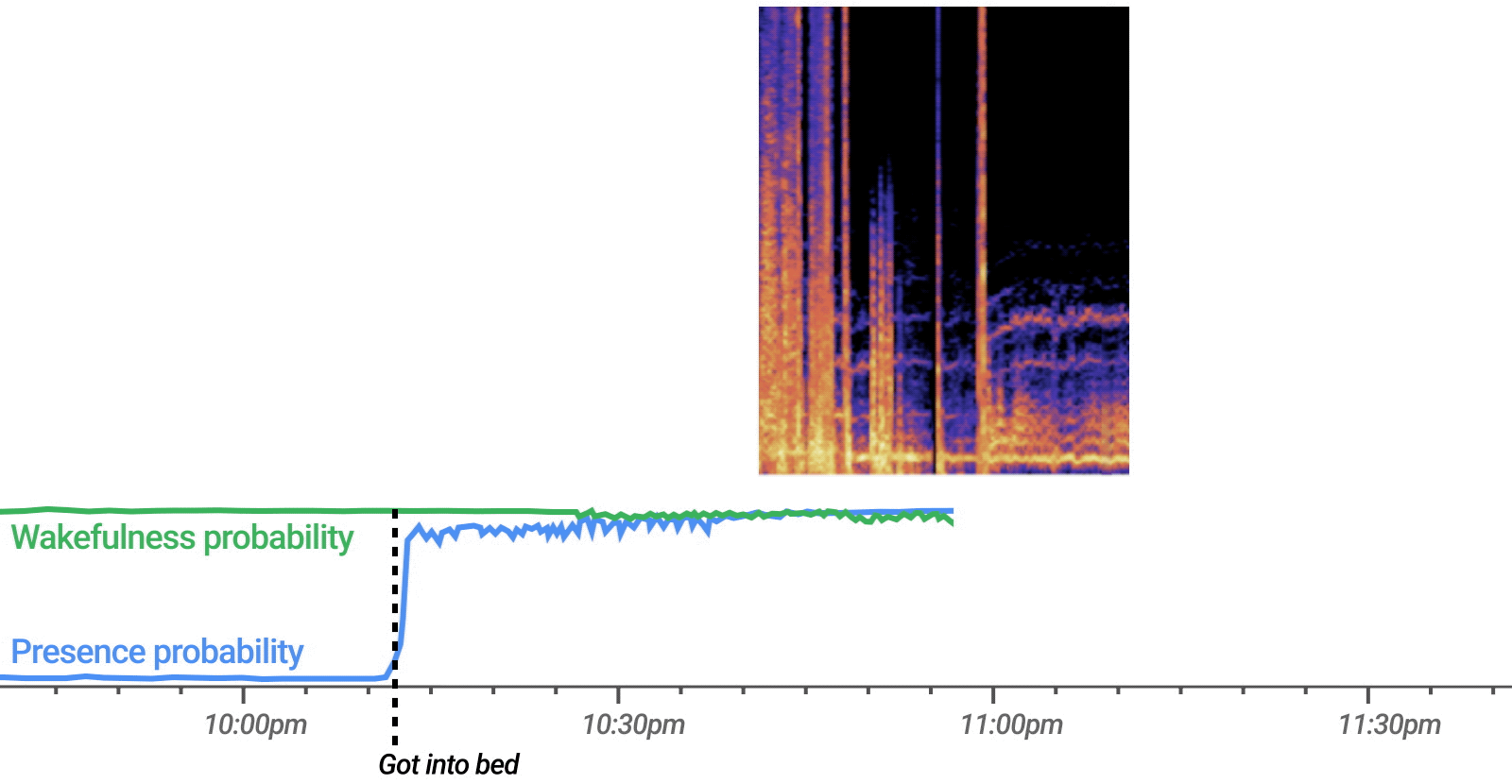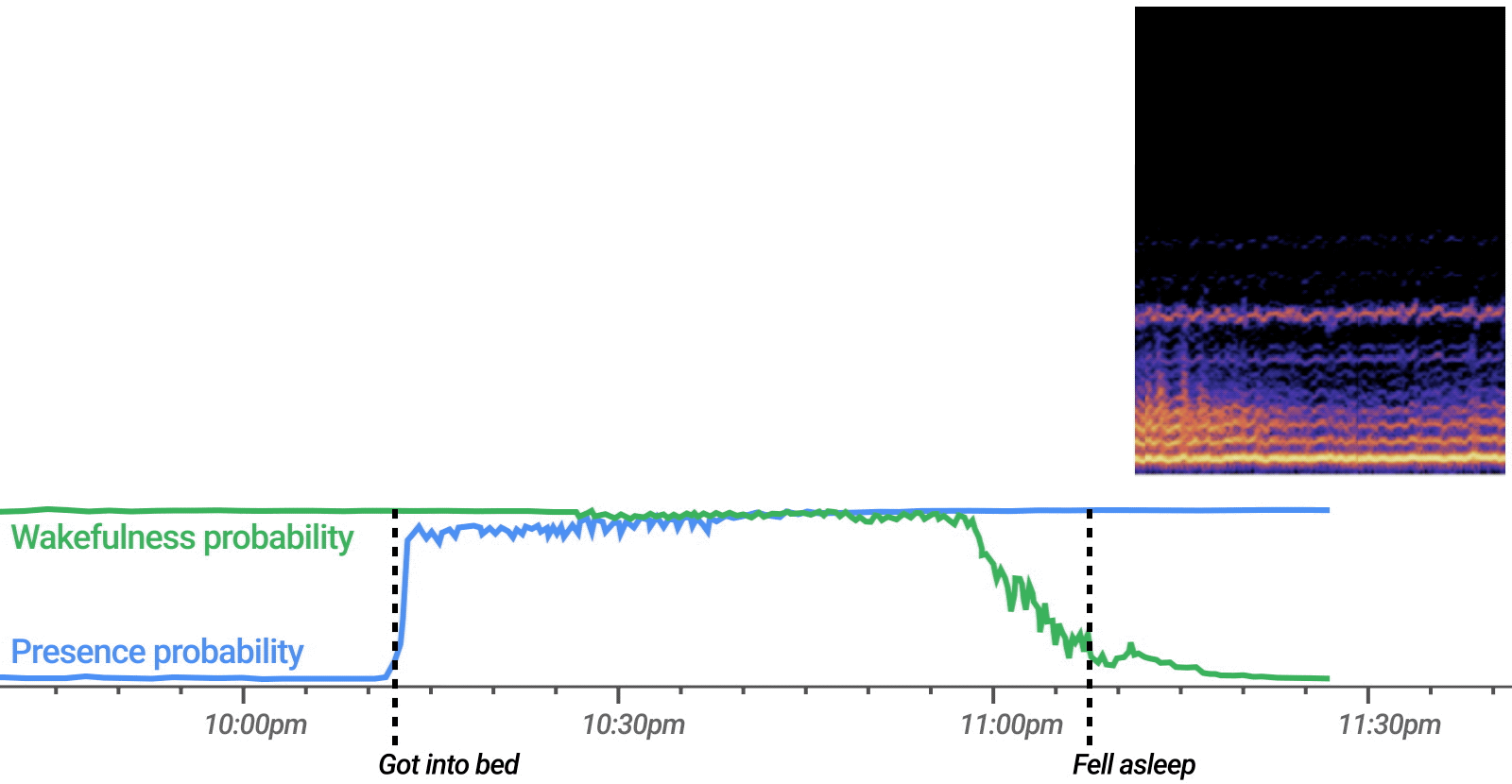
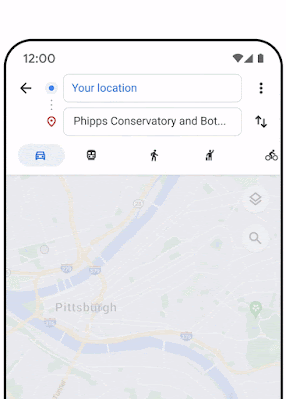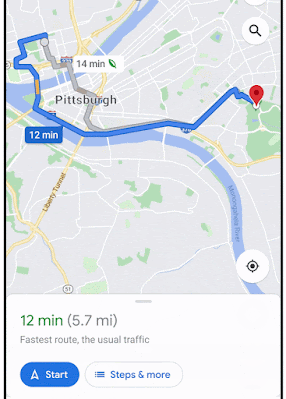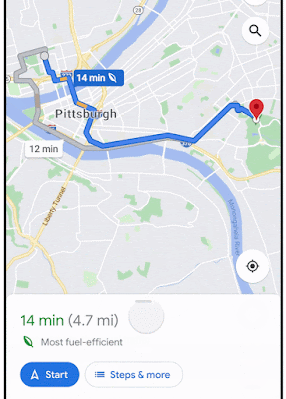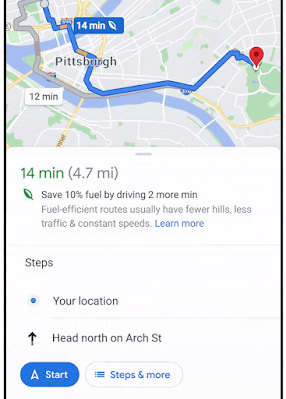
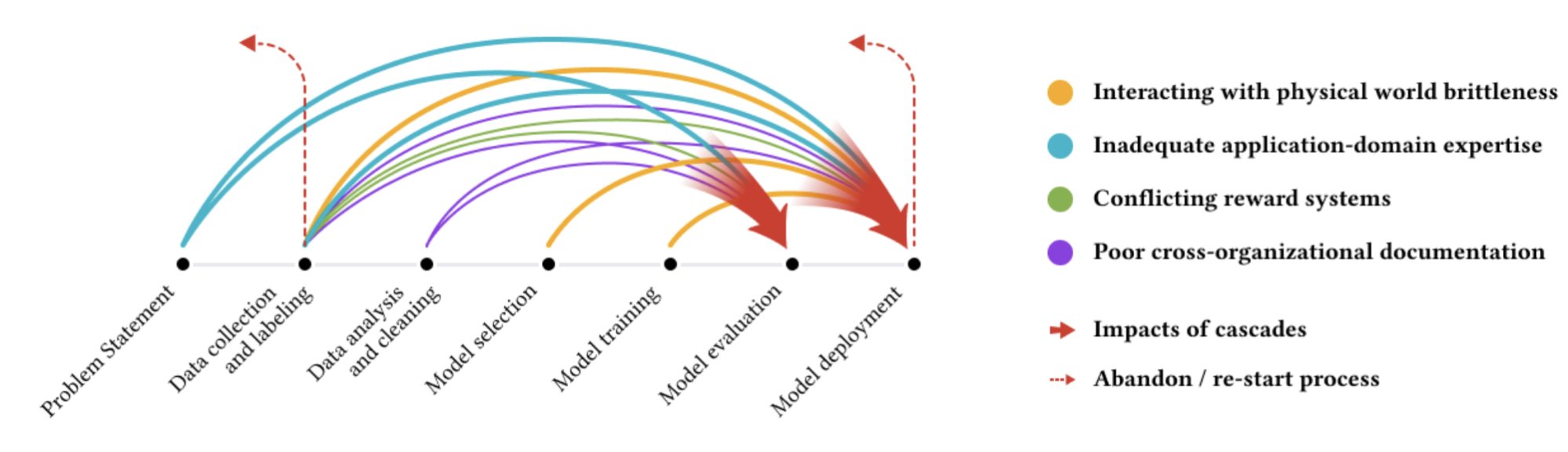

%E2%80%93Weddell_seal_(Leptonychotes_weddellii)_03.jpg){kind=link}