Posted by Google for Developers
Posted by Google for Developers

This month, Google Search turns 25. A lot has changed over the last quarter of a century when it comes to the development space, but one thing has remained a constant - whether you’re stuck on a problem, reading documentation, learning about new technology, or figuring out the best tech stack for your project, Search has been a helpful tool in getting your questions answered.
What you searched for is a strong signal when it comes to developer trends across web, mobile, cloud, and AI over the years. Let’s take a look at some of the interesting things you’ve looked up* – and some funny queries too – because everyone loves a good retrospective.
*Note: Google Trends data goes as far back as 2004.
Building a better web
After the internet dot-com bubble popped in 2000–2001, the web continued to advance and the internet exploded. Web development responded by enabling designers to incorporate multimedia into web pages. Cascading Style Sheets (CSS) (released in 1997) and Flash video (1996-2017) changed the way web pages looked and moved, and streaming changed the way people consumed video. However, the basic interface and structure of the web page remained the same. With the variety of browsers that came to market, JavaScript frameworks and libraries rose along since it can be run everywhere with both CSS and HTML. All these shifts led to some fun searches.
How to center a div
You can’t think of web development without CSS. And it turns out, “how to center a div” has been searched for from the beginning - it’s also provided the internet with a wealth of memes over the years.
JavaScript libraries
JavaScript is a front-end programming language that is used to add interactivity and dynamic behavior to web pages. It is one of the most popular programming languages in the world, and it is essential for building modern web applications. But at some point, most developers have to ask themselves what kind of JavaScript they should use. Vanilla? A framework? A library?
Starting in 2007 there was an uptick of searches for jQuery, which peaked in 2013 and started to fall after that. Meanwhile, developers started to show more interest in React and Angular right around the same time as jQuery’s peak. By April of 2018 they all had a similar volume of searches, and soon after React took over, followed by Angular. Nigeria searched for React the most, while Japan preferred jQuery, and Ecuador preferred Angular. Nowadays, the choice of JavaScript framework is the subject of a lot of controversy - what's your favorite? Share your thoughts with us.
Search term volume for “React”,” jQuery”, and “Angular” from 2004-present day
The rise of mobile
As the web improved, so did mobile. Phones went from cellular to smart. The app economy blossomed. Due to low infrastructure and financial restraints, many emerging markets in Asia, Africa, and Latin America skipped the desktop era in favor of mobile to get their information and entertainment. Mobile development –Android in particular– kicked into high gear as a response.
Android development
Starting in 2007, Android was released as a developer platform before devices were on the market, along with the first Android Developer Challenge which launched to support and recognize developers who build great applications. In 2008, the Android OS was released and open sourced, along with T-Mobile’s G1 as the first smartphone to run Android. That same year, the Android Market was released, allowing developers an easy way to distribute apps to the Android community. In 2012, the marketplace got rebranded to Google Play. All of this momentum helped add to the frenzy, but searches really took off starting in 2012.
Search term volume for “Android development” from 2007-2012
Mobilegeddon
Even web developers couldn’t escape the importance of mobile in its heyday. By 2010, “mobile-first” and “responsive design” became best practices for the web in order to support mobile traffic. As a response to the clear indication that mobile wasn’t going anywhere, by 2015, Google’s search ranking algorithm changed to favor content that is mobile-friendly. Dubbed ‘Mobilegeddon’ by Chuck Price in a post written on Search Engine Watch, developers quickly searched for the term and adjusted their best practices such as responsive and mobile-first design. By 2017, mobile traffic accounted for approximately half of web traffic worldwide before permanently surpassing it in 2020.
Moving to the cloud
Over the last 25 years, cloud development has evolved from a niche technology to a mainstream solution for organizations of all sizes. Being free from managing infrastructure and operations provides a number of advantages like cost savings, speed, and scalability. In the early days, it was mainly used for hosting static websites and applications. But as technology matured, it became increasingly popular for a wider range of applications, including IoT, big data, real-time data, and ML in addition to more modern development practices like containers, microservices, and security.
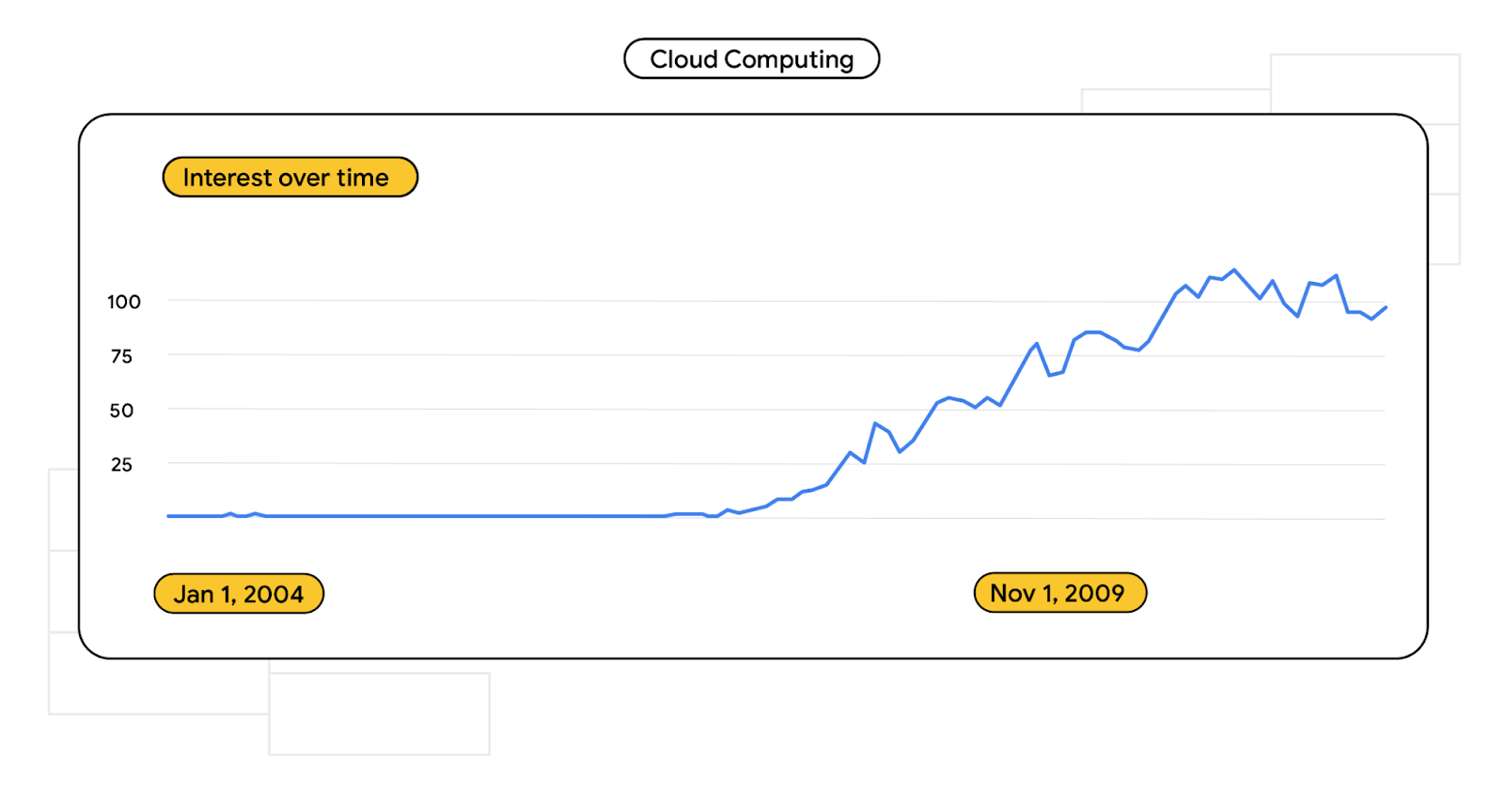
Cloud computing
As development continued to modernize, developers, IT, and operations figured out fairly quickly that managing infrastructure and servers was painful and expensive. In response, many cloud environment providers launched between 2002-2010, including Google Cloud Platform.
Search term volume for “cloud computing” from 2004-2012
Cloud databases
Cloud services extend to storage, databases, and so much more – a necessity as technology becomes more robust, supporting large amounts of data in real time from IoT devices or use cases like ML and large language models. While there were searches for the term “cloud database” as far back as 2004, it spiked in 2017, coinciding with Google Cloud’s Cloud Spanner. And with the latest renaissance of AI technology, it’s pretty likely that this search term will keep going up in the coming months and years.
Present day innovations
Disruptive developer technology like artificial intelligence and machine learning are infused in development today. From AI-assisted coding to solving problems leveraging big data, AI is permeating our lives. So it’s no wonder developers are searching for some key terms.
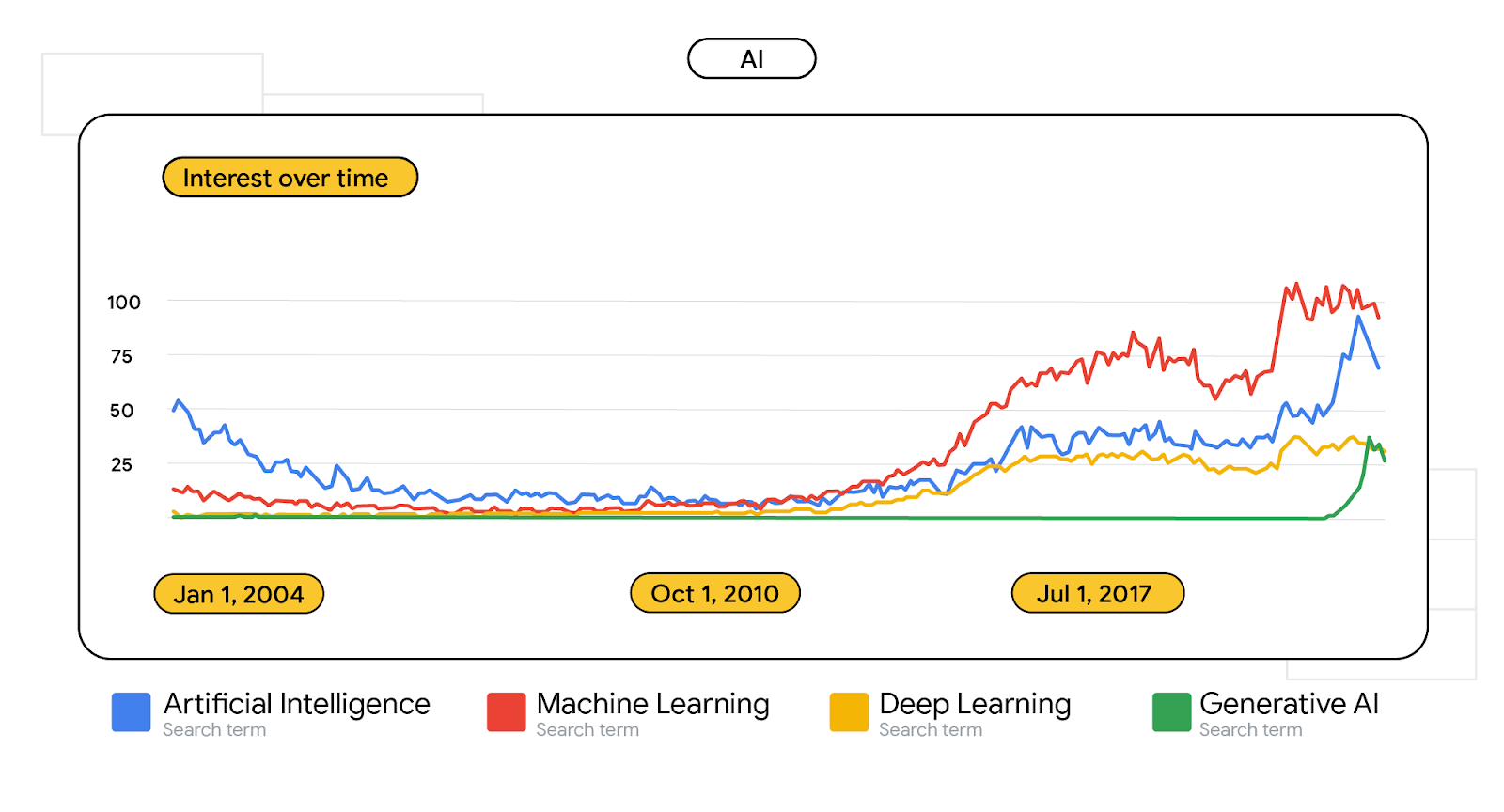
Artificial intelligence, machine learning, and more
While some applications of AI, ML, deep learning, large language models (LLMs) are new, most of the terms aren’t. Even in 2004, AI and ML were search terms of interest. In 2015, most of these terms started to pick back up and continue to trend upwards, with a sheer spike in interest in 2022. That same year, ‘generative AI’ was formally introduced to the world. Python is the most searched coding language closely associated with AI, becoming the most popularly searched language in 2019, finally surpassing Java.
Search term volume for “artificial intelligence”, “machine learning”, “deep learning”, and “generative AI” from 2004-present day
Looking ahead
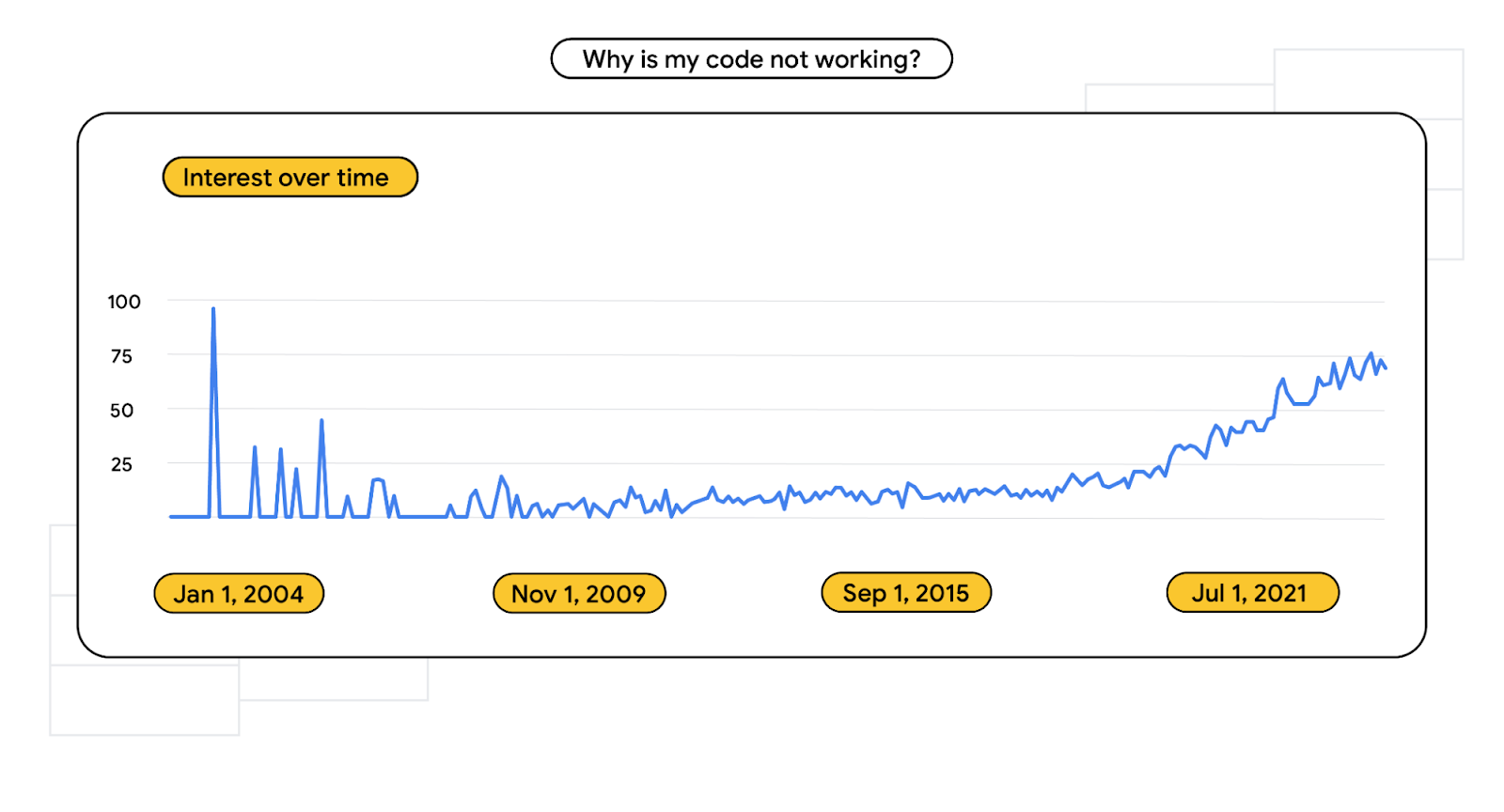
While some aspects of development have gotten progressively cleaner, more modern, and more lightweight - there’s now more choice and complexity when it comes to your tech stack. So it’s no wonder “why is my code not working” spiked in both the early days and today. At Google, we’ll do our best to help streamline and simplify technology to help you build smarter and ship faster with new technology like Project IDX, Android Studio Bot, and coding for Bard.
Search term volume for “why is my code not working?” from 2004-present day
It’s inspiring to see what you have done with the answers to your questions, whether you’re trying to solve specific problems, learning new skills or best practices, figuring out what technology you want to use, or dreaming up your next big idea. We look forward to seeing what the next 25 years bring.
Follow more developer trends and insights on Google for Developers across YouTube, LinkedIn, and Instagram.
 Posted by Joe Fernandez – Google AI Developer Relations
Posted by Joe Fernandez – Google AI Developer Relations

 Posted by Jeanine Banks – VP & General Manager, Developer X, and Head of Developer Relations
Posted by Jeanine Banks – VP & General Manager, Developer X, and Head of Developer Relations

 Posted by Max Saltonstall – Developer Relations Engineer
Posted by Max Saltonstall – Developer Relations Engineer

 Posted by Lillian Chen – Global Brand and Content Marketing Manager, Google Accelerator Programs
Posted by Lillian Chen – Global Brand and Content Marketing Manager, Google Accelerator Programs





 Posted by Brian Craft, Satish Shreenivasa, Huikun Zhang, Manisha Arora and Paul Cubre – gTech Data Science Team
Posted by Brian Craft, Satish Shreenivasa, Huikun Zhang, Manisha Arora and Paul Cubre – gTech Data Science Team



 Posted by Bradford Lee – Product Marketing Manager, Augmented Reality, and Ahsan Ashraf – Product Marketing Manager, Google Maps Platform
Posted by Bradford Lee – Product Marketing Manager, Augmented Reality, and Ahsan Ashraf – Product Marketing Manager, Google Maps Platform