When you come to Google Search, our goal is to connect you with useful information as quickly as possible. That information can take many forms, and over the years the search results page has evolved to include not only a list of blue links to pages across the web, but also useful features to help you find what you’re looking for even faster. Some examples include featured snippets, which highlight results that are likely to contain what you’re looking for; Knowledge Panels, which can help you find key facts about an individual or other topic in the world; and predictive features like Autocomplete that help you navigate Search more quickly.
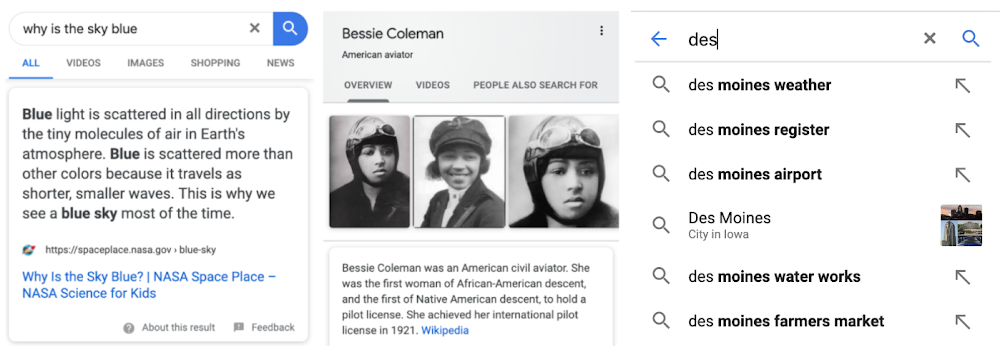
Left-right: Examples of a featured snippet, a Knowledge Panel and an Autocomplete prediction
Because these features are highlighted in a unique way on the page, or may show up when you haven’t explicitly asked for them, we have policies around what should and should not appear in those spaces. This means that in some cases, we may correct information or remove those features from a page.
This is quite different from how we approach our web and image search listings and how those results rank in Search, and we thought it would be helpful to explain why, using a few examples.
Featured Snippets
One helpful information format is featured snippets, which highlight web pages that our systems determine are especially likely to contain what you’re looking for. Because their unique formatting and positioning can be interpreted as a signal of quality or credibility, we’ve published standards for what can appear as a featured snippet.
We don’t allow the display of any snippets that violate our policies by being sexually explicit, hateful, violent, harmful or lacking expert consensus on public interest topics.
Our automated systems are designed to avoid showing snippets that violate these policies. However, if our systems don’t work as intended and a violating snippet appears, we’ll remove it. In such cases, the page is not removed as a web search listing; it’s simply not highlighted as a featured snippet.
The Knowledge Graph
The Knowledge Graph in Google Search reflects our algorithmic understanding of facts about people, places and things in the world. The Knowledge Graph automatically maps the attributes and relationships of these real-world entities from information gathered from the web, structured databases, licensed data and other sources. This collection of facts allows us to respond to queries like "Bessie Coleman" with a Knowledge Panel with facts about the famous aviator.
Information from the Knowledge Graph is meant to be factual and is presented as such. However, while we aim to be as accurate as possible, our systems aren’t perfect, nor are all the sources of data available. So we collect user feedback and may manually verify and update information if we learn something is incorrect and our systems have not self-corrected. We have developed tools and processes to provide these corrections back to sources like Wikipedia, with the goal of improving the information ecosystem more broadly.
Furthermore, we give people and organizations the ability to claim their Knowledge Panels and provide us with authoritative feedback on facts about themselves, and if we otherwise are made aware of incorrect information, we work to fix those errors. If an image or a Google Images results preview that’s shown in a Knowledge Panel does not accurately represent the person, place or thing, we’ll also fix the error.
Predictive features
There are other features that are “predictive,” like Autocomplete and Related Searches, which are tools to help you navigate Search more quickly. As you type each character into the search bar, Autocomplete will match what you’re typing to common searches to help you save time. On the search results page, you may see a section of searches labeled “People also search for,” which is designed to help you navigate to related topics if you didn’t find what you were looking for, or to explore a different dimension of a topic.
Because you haven’t asked to see these searches, we’re careful about not showing predictions that might be shocking or offensive or could have a negative impact on groups or individuals. Read more about our policies.
You can still issue any search you’d like, but we won’t necessarily show all possible predictions for common searches. If no predictions appear or if you’re expecting to see a related search and it’s not there, it might be that our algorithms have detected that it contains potentially policy-violating content, the prediction has been reported and found to violate our policies, or the search may not be particularly popular.
While we do our best to prevent inappropriate predictions, we don’t always get it right. If you think a prediction violates one of our policies, you can report a prediction.
Across all of these features, we do not want to shock or offend anyone with content that they did not explicitly seek out, so we work to prevent things like violence or profanity from appearing in these special formats.
Organic search results
While we’ve talked mostly about helpful features that appear on the search results page, the results that probably come to mind most are our organic listings—the familiar “blue links” of web page results, thumbnails displayed in a grid in Google Images or videos from the web in video mode.
In these cases, the ranking of the results is determined algorithmically. We do not use human curation to collect or arrange the results on a page. Rather, we have automated systems that are able to quickly find content in our index--from the hundreds of billions of pages we have indexed by crawling the web--that are relevant to the words in your search.
To rank these, our systems take into account a number of factors to determine what pages are likely to be the most helpful for what you’re looking for. You can learn more about this on our How Search Works site.
While we intend to provide relevant results and prioritize the most reliable sources on a given topic, as with any automated system, our search algorithms aren’t perfect. You might see sites that aren’t particularly relevant to your search term rising to the top, or perhaps a page that does not contain trustworthy information rank above a more official website.
When these problems arise, people often take notice and ask us whether we intend to “fix” the issue. Often what they might have in mind is that we’d manually re-order or remove a particular result from a page. As we’ve said many times in the past, we do not take the approach of manually intervening on a particular search result to address ranking challenges.
This is for a variety of reasons. We receive trillions of searches each year, so “fixing” one query doesn’t improve the issue for the many other variations of the same query or help improve search overall.
So what do we do instead? We approach all changes to our Search systems in the same way: we learn from these examples to identify areas of improvement. We come up with solutions that we believe could help not just those queries, but a broad range of similar searches. We then rigorously test the change using insights from live experiments and data from human search rater evaluations. If we determine that the change provides overall positive benefits-- making a large number of search results more helpful, while preventing significant losses elsewhere-- we launch that change.
Our search algorithms are complex math equations that rely on hundreds of variables, and last year alone, we made more than 3,200 changes to our search systems. Some of these were visible launches of new features, while many others were regular updates meant to keep our results relevant as content on the web changes. And some are also improvements based on issues we identified, either via public reports or our own ongoing quality evaluations. Unlike with Search features where we are able to quickly correct issues that violate our policies, sometimes identifying the root cause of ranking issues can take time, and improvements may not happen immediately.. But as we have been for more than 20 years, we are always committed to identifying these challenges and working to make Search better.
Spam Protections
This is not to say that there aren’t policies and guidelines that apply to our organic listings. Content there has to meet our long-standing webmaster guidelines, which protect users against things like spam, malware and deceptive sites. Our spam protection systems automatically work to prevent our ranking systems from rewarding such content.
In cases where our spam systems don’t work, we have long taken manual actions against pages or sites. We report these actions through the Manual Actions report in our Search Console tool, in hopes that site owners will curb such behavior. These actions are not linked to any particular search results or query. They’re taken against affected content generally.
Legal and Policy-based Removals
As our mission is to provide broad access to information, we remove pages from our results in limited circumstances, when required by law--such as child abuse imagery and copyright infringement claims--and in narrow cases where we have developed policies to protect people, such as content that has sensitive personal information.
Some of these legal and policy actions do remove results for particular searches, such as someone’s name. However, none of these removals happen because Google has chosen to “fix” poor results. Rather, these are acts of legal compliance and applications of publicly documented policies to help keep people safe.
Overall, we’re constantly striving to make our search results and features on the results page as useful and reliable as possible, and we value your feedback to help us understand where we can do better.