As part of CHIPS Alliance’s mission to enable a software-driven approach to silicon, Google, Antmicro and other CHIPS members have been developing and improving a growing number of open source tools to enable effective, CI-driven silicon development.
Fully reproducible and scalable workflows based on open source tooling are especially beneficial for efforts spanning across multiple industrial and academic actors such as Caliptra, a Root of Trust project driven by Google, AMD, NVIDIA and Microsoft which joined CHIPS in order to host the ongoing development and provide the necessary structure, working environment and support for the reference implementation of the standard, originally hosted by Open Compute Project.
In this blog post, we describe Antmicro and Google’s collaborative effort focused on introducing a Continuous Integration (CI) based code quality checks, code indexing, coverage and functional testing pipeline into the RISC-V VeeR core family, as used within the Caliptra project.
Open source RTL CI testing and verification for Caliptra/VeeR
Caliptra and VeeR
VeeR (Very Efficient & Elegant RISC-V) is an open source production-grade RISC-V core family hosted by CHIPS Alliance and comes in three variants:
Caliptra’s hardware block structure with an EL2 VeeR CPU core includes the following elements:
Caliptra’s hardware block structure
As can be seen in the diagram, VeeR EL2 plays a central role in the implementation and, while it is a mature and well-tested technology, keeping both the core itself and its integration with Caliptra consistently tested is important.
Advanced code processing with Verible and Kythe
Many of Antmicro’s efforts focus around building not only the end products but the scalable CI solutions for collaborative hardware development environments that power them. Caliptra’s needs for establishing a more open process tie in perfectly with Antmicro’s and all of CHIPS Alliance’s open source-based approach to tooling.
One of the core parts of this effort involved Verible, an open source SystemVerilog parser developed by Google in collaboration with Antmicro within CHIPS Alliance, offering a number of code processing functionalities, including linting, formatting, indexing and producing a Kythe schema. Verible comes with a Language Server Protocol which enables integration with popular text editors such as VS Code, Vim, Neovim, Emacs, Sublime, Kakoune and Kate, described in detail in a separate article on Antmicro's blog.
Antmicro’s work for Google around Caliptra involved [adding the Verible formatter to the VeeR CI which marks non-compliant formatting changes and uses the reviewdog bot to add comments in the Pull Request Discussion with suggested fixes. Furthermore, we added a Verible linting Action that helps developers maintain good coding practices by providing lint rules for continuous validation of the code, before it even reaches the compilation phase. Notably, the provided lint rules are flexible and can be adjusted based on the project's requirements, or even turned off completely through creation of a waiver-file or by an inline directive.
Verible linting example
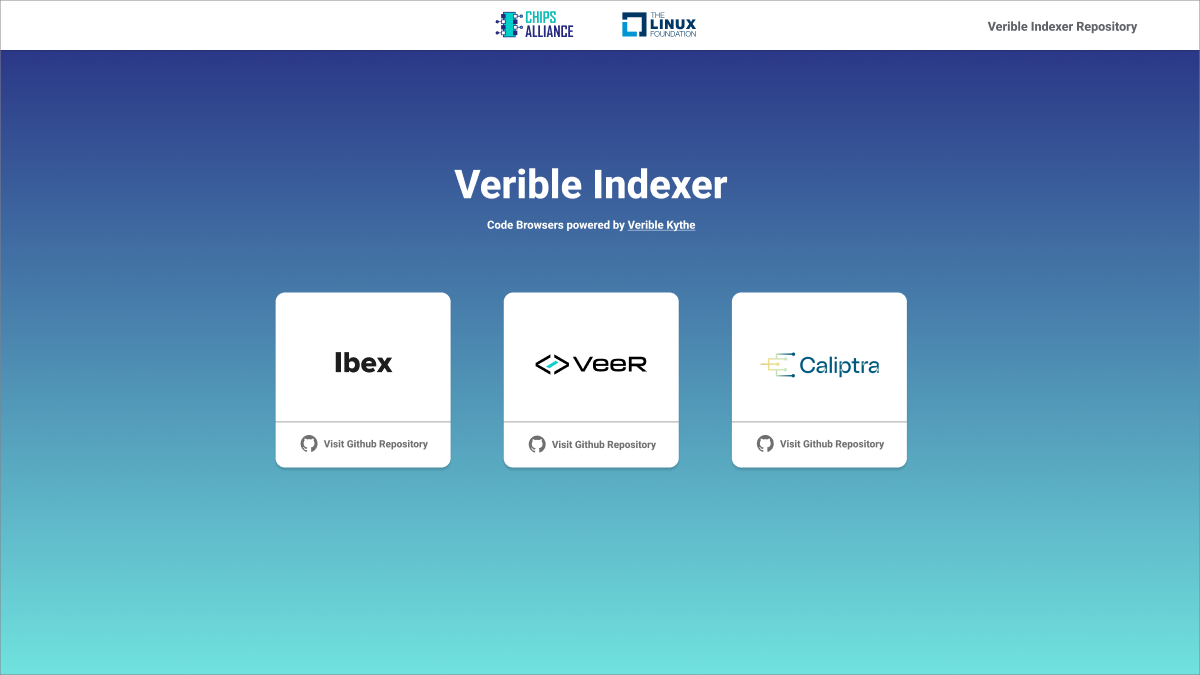
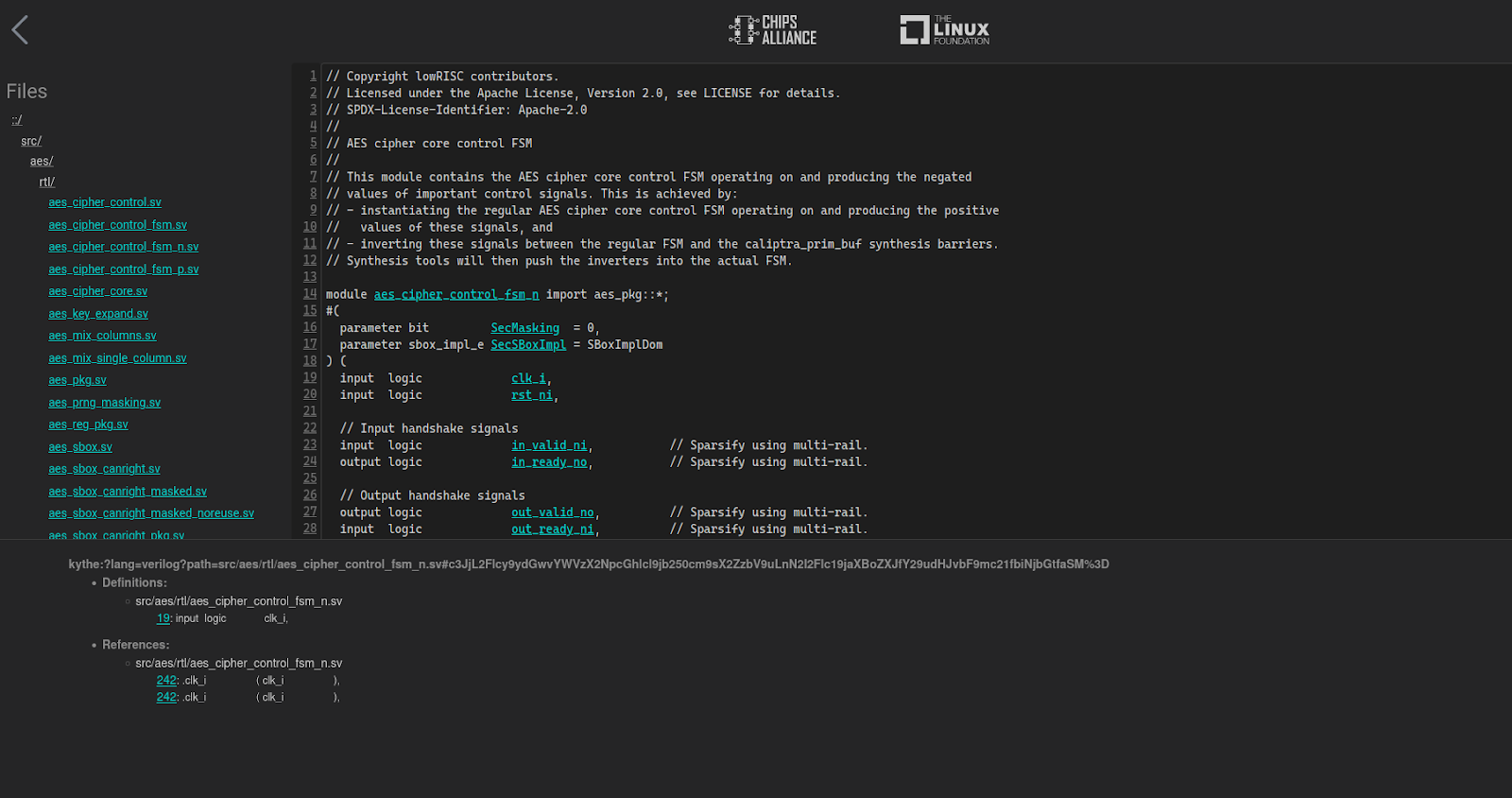
Thanks to Verible’s ability to output a Kythe schema, besides linting and formatting code changes we can also provide an indexed overview of the entire codebase, viewable online. The Kythe Verible Indexer, using Verible Indexing Action, enables the user to select multiple repositories to create a set of indexed webpages. The source code is available in the Verible Indexer GitHub repo.
Verible Indexer landing page
The workflow also checks if a newer revision is available for any of the defined repositories and, if needed, performs indexing. The indexed code browser webpages were deployed for Cores-VeeR-EL2 and Caliptra-rtl.
Example from Caliptra-RTL Code Navigator demonstrating visual representation of the project structure (left pane), code browser (right pane) and usage of active references (bottom pane)
Putting riscv-dv to use
The riscv-dv framework is another tool hosted by CHIPS Alliance helping address the complexities of SoC design and verification. It is an SV/UVM based open source instruction generator for RISC-V processors, originally developed for Google’s own needs but currently in use by a wide array of organizations and companies working with verification of RISC-V cores.
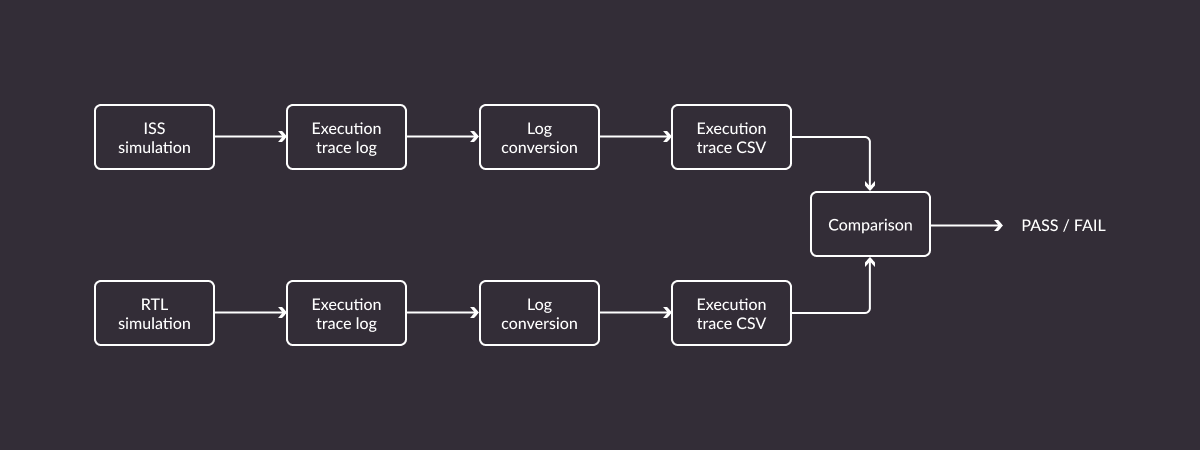
The riscv-dv framework generates random instruction chains to exercise certain core features. These instructions are then simultaneously executed by the core (through RTL simulation) and by a reference RISC-V ISS (instruction set simulator), for example Spike or Renode, Antmicro’s open source simulation framework.
Core states of both are then compared after each executed instruction and an error is reported in case of a mismatch.
riscv-dv flow
While working on the Caliptra project, Antmicro introduced the riscv-dv framework for testing the VeeR-EL2 core as well as a GH Actions CI flow which builds or downloads all the dependencies (Verilator, Spike, VeeR-ISS and Renode) and runs the tests. For the purpose of using riscv-dv with VeeR we had to write a VeeR-specific execution trace log parser. The task of this parser is to translate the log to the format understandable by the riscv-dv framework.
As an interesting detail, VeeR implements division (div) and remainder (rem) instructions in a way it delegates the calculations to the division logic and proceeds with the execution of the program. Once the division core ends, the result is written back to the div/rem instruction result register. This flow takes into account the situation where any instruction following div/rem requires the div/rem result. In such cases the pipeline is stalled until the result is available. If any instruction following div/rem overwrites the result register before division logic finishes, the division operation is canceled.
To handle the case where the division results are available after a few other instructions were executed we’ve developed a lazy parsing method of the VeeR trace log to be able to catch the result register update even if it is not immediate. The second case - cancellation of the division calculation has been handled by adding a code post-processing script. It can detect a situation where a cancellation would happen and prevent it by injecting a number of the NOP instructions (allowing the division core to finish).
Custom GitHub Actions runners for greater scalability and more flexibility to mix tools
Much like a large part of the industry, the Caliptra project uses Universal Verification Methodology (UVM) as its verification methodology. While Antmicro’s ongoing work on enabling fully open source UVM support in Verilator should ultimately enable completely open source verification, today UVM testbenches or tools like RISC-V DV cannot be run using open source tools only.
Fortunately, this problem already has a solution, also developed within the CHIPS Alliance - custom GitHub Actions Runners that are already in use by a large number of CHIPS projects.
A custom runner setup, currently in development for Caliptra, allows mixing and matching open and closed source tools for CI testing purposes, exposing only the results (such as pass/fail or coverage) with fine-grained control.
What is more, given that RTL design testing and verification of RISC-V based cores and SoCs often require long, memory-consuming and computationally demanding simulations, the custom runners will play another very important role in Caliptra. While GitHub is the obvious choice for hosting the reference RTL, the processing power and throughput of the CI machines available in GitHub Actions is simply not enough to cover the needs of simulation of complex designs, especially in a highly dynamic, collaborative environment with lots of CI angles.
In order to enable public-facing yet secure CI, and improve the flexibility and scalability of Caliptra’s/VeeR’s pipelines, the custom runners will be deployed for the respective repositories. This setup will enable us to precisely select machines to be used for specific workloads (i.e. the architecture, virtual CPU count, memory size and disk space) but also to use tools stored on an external cloud disk that can be attached to a virtual machine running the job workload.
Seeding other verification methods
The Caliptra SoC is meant as a macro for use in a variety of chip designs, big and small. Various teams adopting Caliptra/VeeR as their Root of Trust solution will need to plug it into a larger ecosystem of tools used in their organization (of course hopefully using Caliptra as a good reference and role model).
As part of the project, on top of the original Caliptra test suite we implemented more specific tests around the VeeR integration in cocotb, a co-simulation testbench library that enables connecting Python coroutines with your HDL simulator of choice. We prepared a cocotb testbench that is able to not only run programs from the generator, but also apply dedicated stimuli and monitor the results in a Python coroutine.
Furthermore, for projects who prefer a more UVM-like testing methodology but need an open source option today, we also provide some example tests using pyuvm, a Pythonic library that mirrors the industry accepted SystemVerilog implementation. We have implemented a minimal UVM Agent for the programmable interrupt controller of the VeeR-EL2 Core, which will be used to verify handling of the interrupt service routines triggered by external or local-to-core timer interrupts. The verification environment is expected to grow as more test cases could be added, covering the DMA controller, close coupled memory buses or the debug interface.
For system level tests we decided to connect to an interactive simulation of the complete design via JTAG with commonly used tools: Open On-Chip Debugger OpenOCD and the GNU Project Debugger (GDB). The simulation exposes a virtual JTAG port, which is used to establish a connection with OpenOCD. Then the OpenOCD instance connects to the GNU debugger. Finally, test scripts are run in GDB, which verify core registers content, memory access and peripheral accesses.
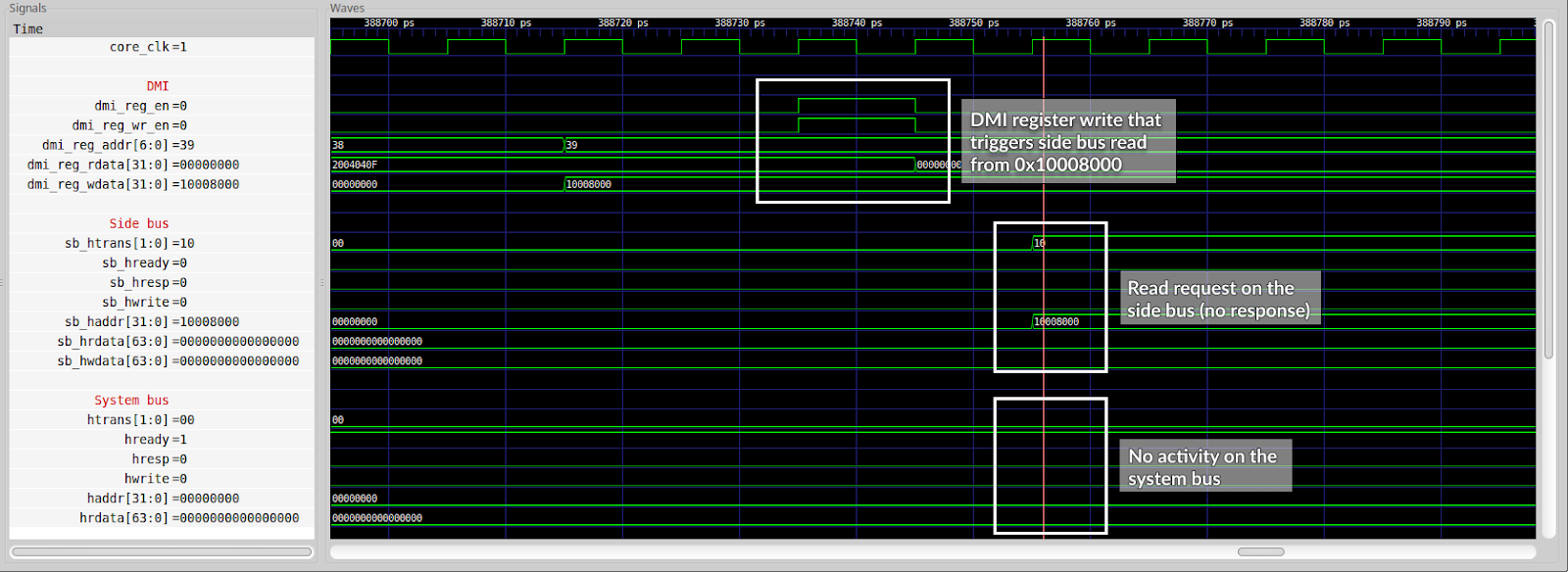
With this testing methodology we exposed an actual problem in the design which prevented accessing system peripherals via JTAG. As it turned out the issue was caused by the side AHB bus of the debug core being disconnected.
Incorrect waveform - no system bus activity
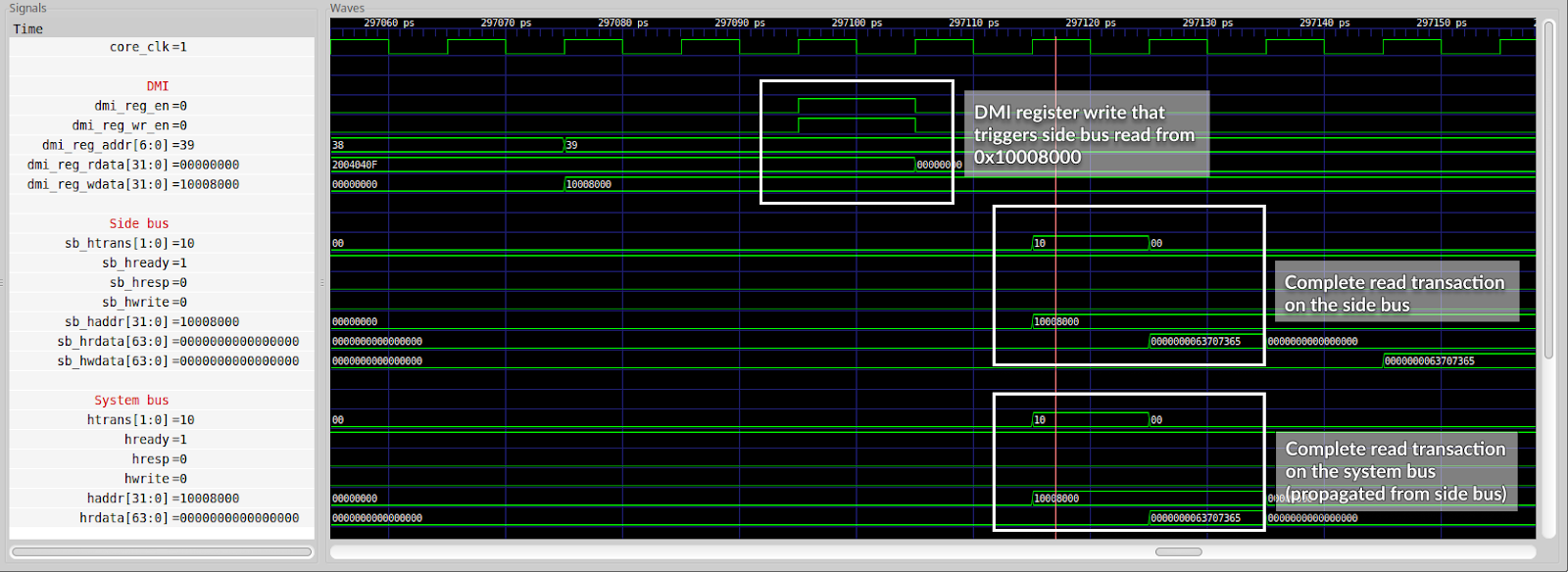
Once a connection of the side bus had been made it became possible to access all the peripherals. A 2-to-1 AHB multiplexer was used to join the system and side AHB master ports and forward requests to the peripherals.
Correct waveform - correct system bus activity
To verify the effectiveness of all kinds of tests, both ISS and RTL level, and help ensure that all design states are properly tested, we use coverage analysis. While open source tools and frameworks have some support for gathering and presenting these metrics, e.g. Verilator supports line, toggle and functional coverage, some additional work needs to be done to integrate all of those and present them in a comprehensive, visual form, which will be part of our future efforts.
Transparent and open source-driven hardware ecosystem
In addition to the efforts described in this article, there are other interesting developments within CHIPS Alliance, including improving Verilator to better handle large designs and verification tasks, which are helping bring more open source-driven development and verification solutions to the Caliptra project and the entire open hardware ecosystem.
To learn more about the Caliptra project, watch a recording from a joint talk by Google and Antmicro given at this year’s RISC-V Summit Europe. You can also join the contributors at the upcoming 2023 OCP Global Summit for several talks about the latest developments in the project and future plans.
If you are interested in the work of CHIPS Alliance, keep an eye out for updates during their next Technology Update coinciding with the RISC-V Summit this Fall.
By Michael Gielda – Antmicro