People turn to Google every day for information in the moments that matter most. Sometimes that’s to look for the best recipe for dinner, other times it’s to check the facts about a claim they heard about from a friend.
No matter what you’re searching for, we aim to connect you with high-quality information, and help you understand and evaluate that information. We have deeply invested in both information quality and information literacy on Google Search and News, and today we have a few new developments about this important work.
Our latest quality improvements to featured snippets
We design our ranking systems to surface relevant information from the most reliable sources available – sources that demonstrate expertise, authoritativeness and trustworthiness. We train our systems to identify and prioritize these signals of reliability. And we’re constantly refining these systems — we make thousands of improvements every year to help people get high-quality information quickly.
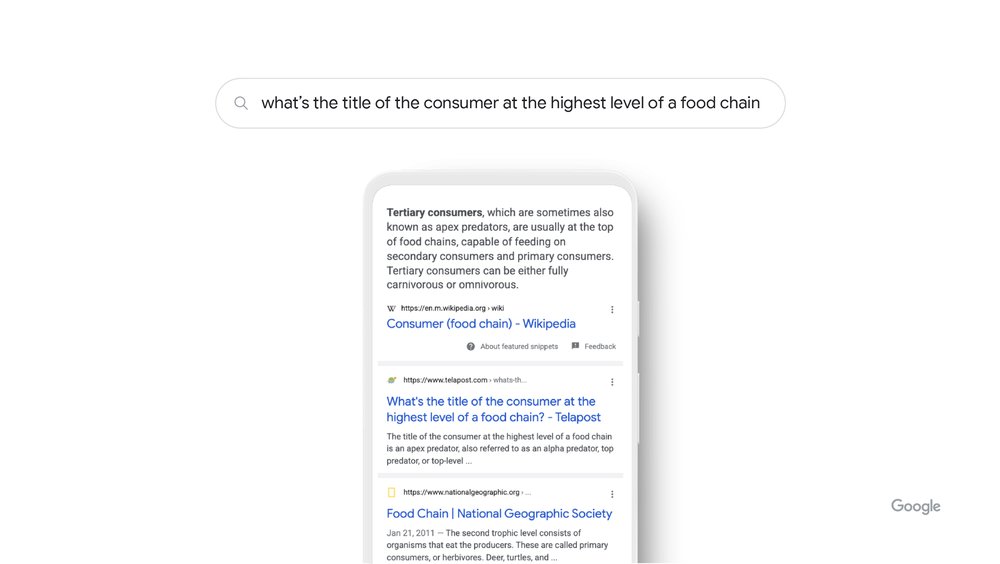
Today we’re announcing one such improvement: a significant innovation to improve the quality of featured snippets. Featured snippets are the descriptive box at the top of the page that prominently highlights a piece of information from a result and the source, in response to your query. They’re helpful both for people searching on Google, and for web publishers, as featured snippets drive traffic to sites.
By using our latest AI model, Multitask Unified Model (MUM), our systems can now understand the notion of consensus, which is when multiple high-quality sources on the web all agree on the same fact. Our systems can check snippet callouts (the word or words called out above the featured snippet in a larger font) against other high-quality sources on the web, to see if there’s a general consensus for that callout, even if sources use different words or concepts to describe the same thing. We've found that this consensus-based technique has meaningfully improved the quality and helpfulness of featured snippet callouts.
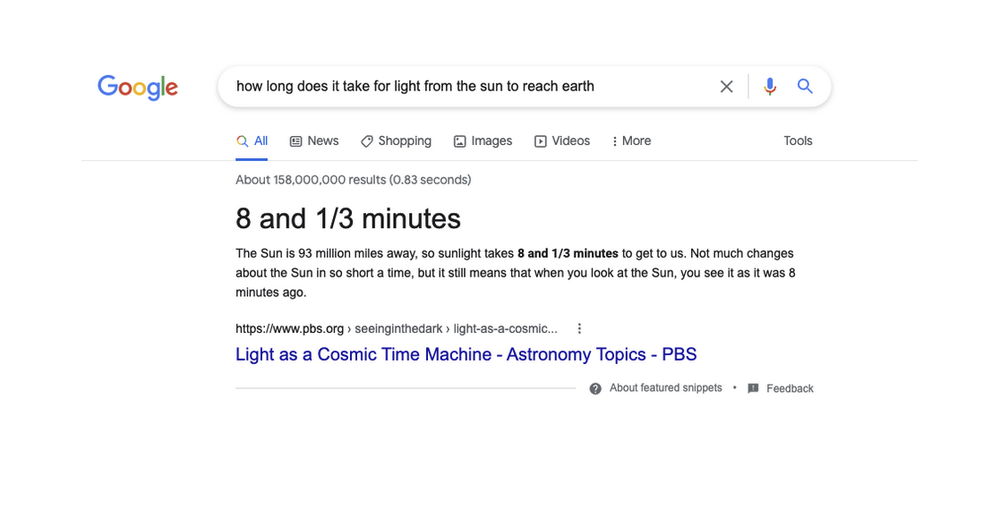
With a consensus-based technique, we’re improving featured snippets.
AI models are also helping our systems understand when a featured snippet might not be the most helpful way to present information. This is particularly helpful for questions where there is no answer: for example, a recent search for “when did snoopy assassinate Abraham Lincoln” provided a snippet highlighting an accurate date and information about Lincoln’s assassination, but this clearly isn’t the most helpful way to display this result.
We’ve trained our systems to get better at detecting these sorts of false premises, which are not very common, but are cases where it’s not helpful to show a featured snippet. We’ve reduced the triggering of featured snippets in these cases by 40% with this update.
Information literacy
Beyond designing our systems to return high-quality information, we also build information literacy features in Google Search that help people evaluate information, whether they found it on social media or in conversations with family or friends. In fact, in a study this year, researchers found that people regularly use Google as a tool to validate information encountered on other platforms. We’ve invested in building a growing range of information literacy features — including Fact Check Explorer, Reverse image search, and About this result — and today, we’re announcing several updates to make these features even more helpful.
Expanding About this result to more places
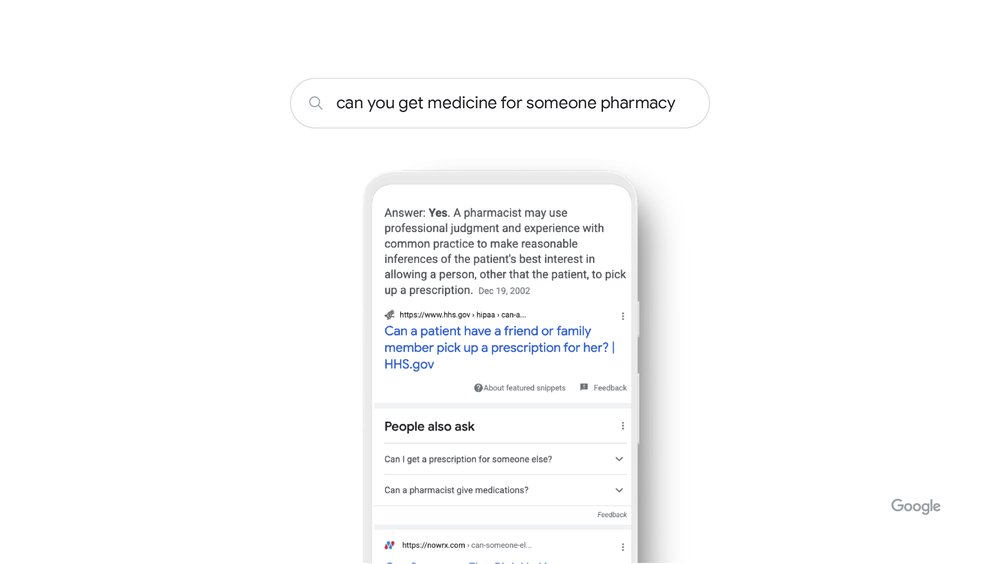
About this result helps you see more context about any Search result before you ever visit a web page, just by tapping the three dots next to the result. Since launching last year, people have used About this result more than 2.4 billion times, and we’re bringing it to even more people and places - with eight more languages including Portuguese (PT), French (FR), Italian (IT), German (DE), Dutch (NL), Spanish (ES), Japanese (JP) and Indonesian (ID), coming later this year.
This week, we’re adding more context to About this result, such as how widely a source is circulated, online reviews about a source or company, whether a company is owned by another entity, or even when our systems can’t find much info about a source – all pieces of information that can provide important context.
And we’ve now launched About this page in the Google app, so you can get helpful context about websites as you’re browsing the web. Just swipe up from the navigation bar on any page to get more information about the source – helping you explore with confidence, no matter where you are online.
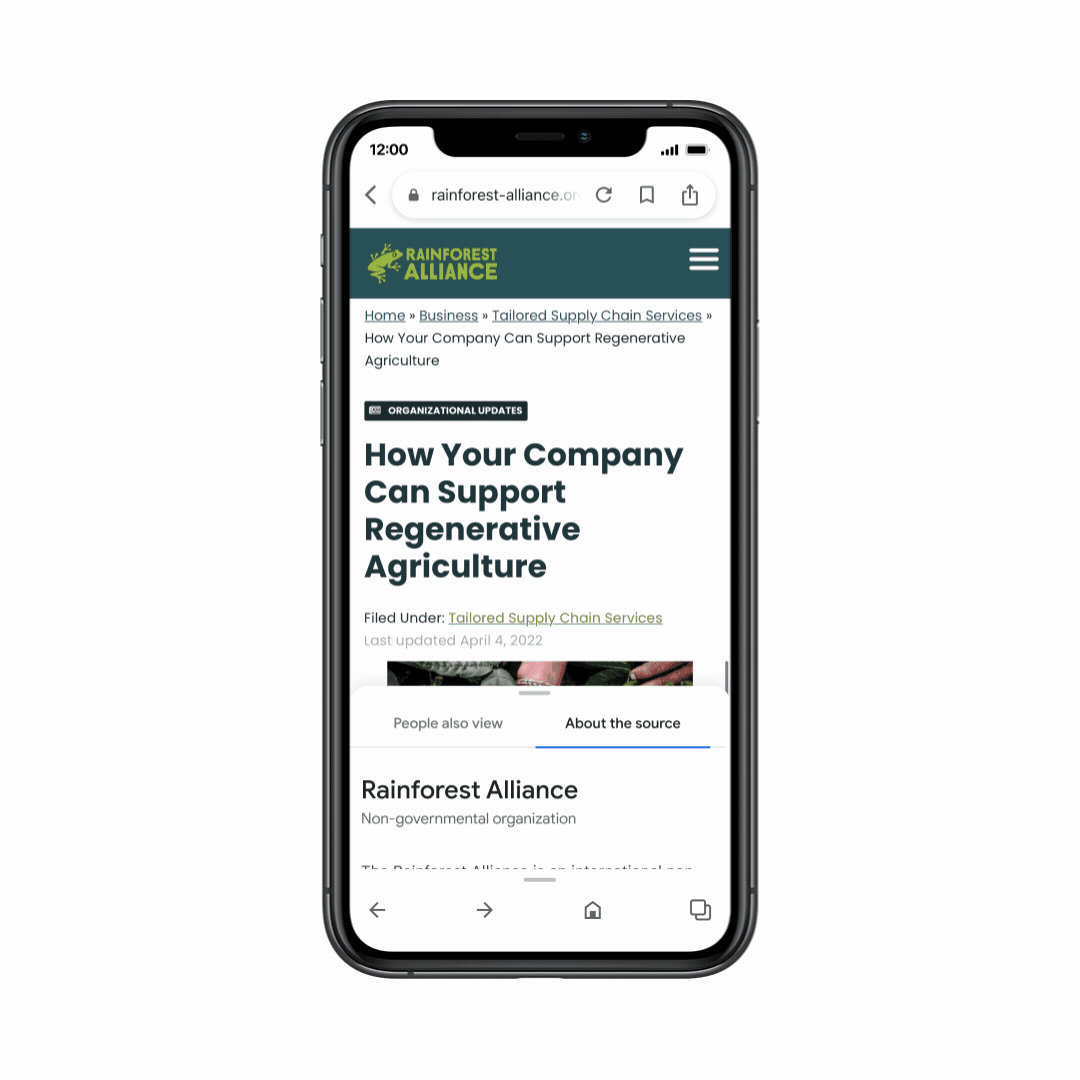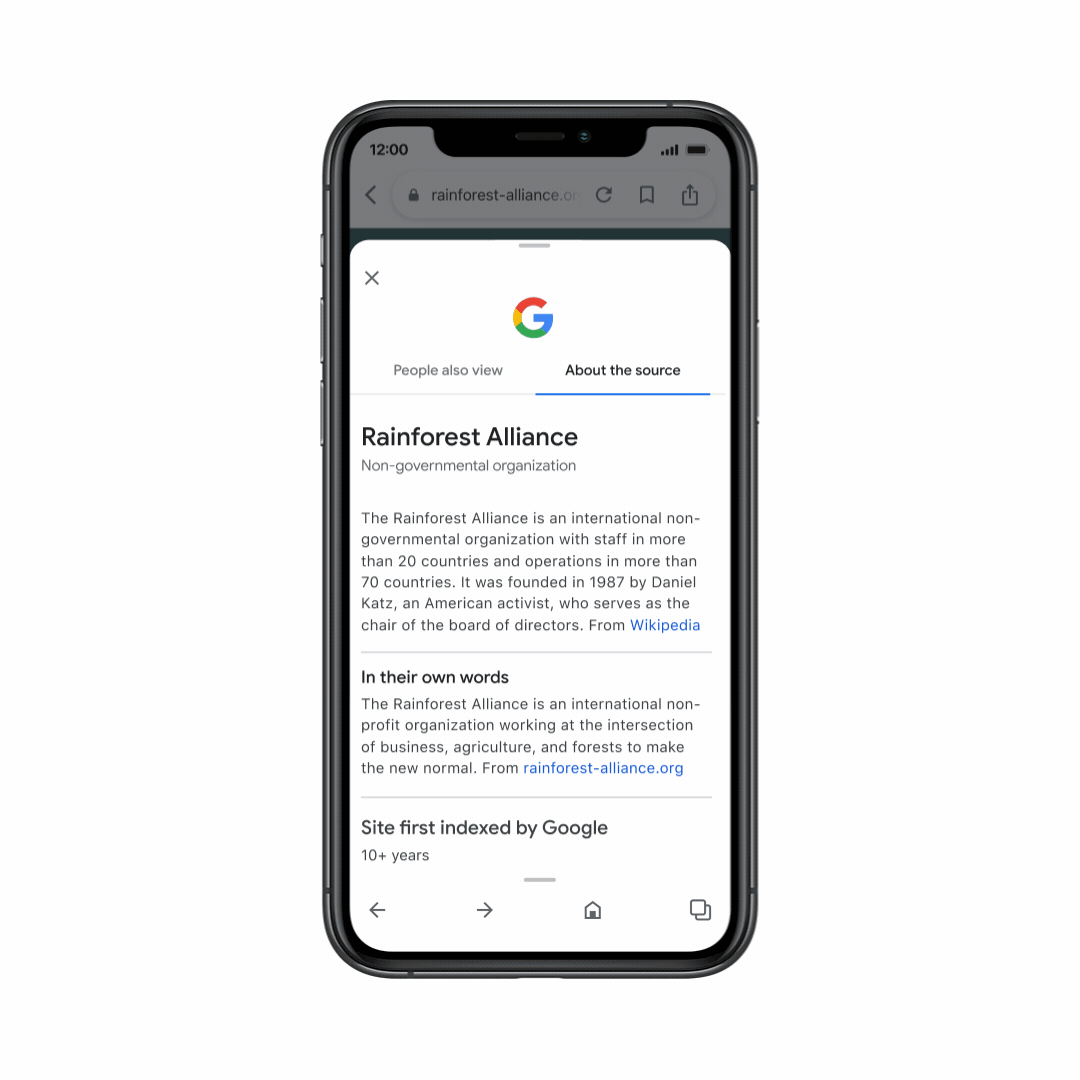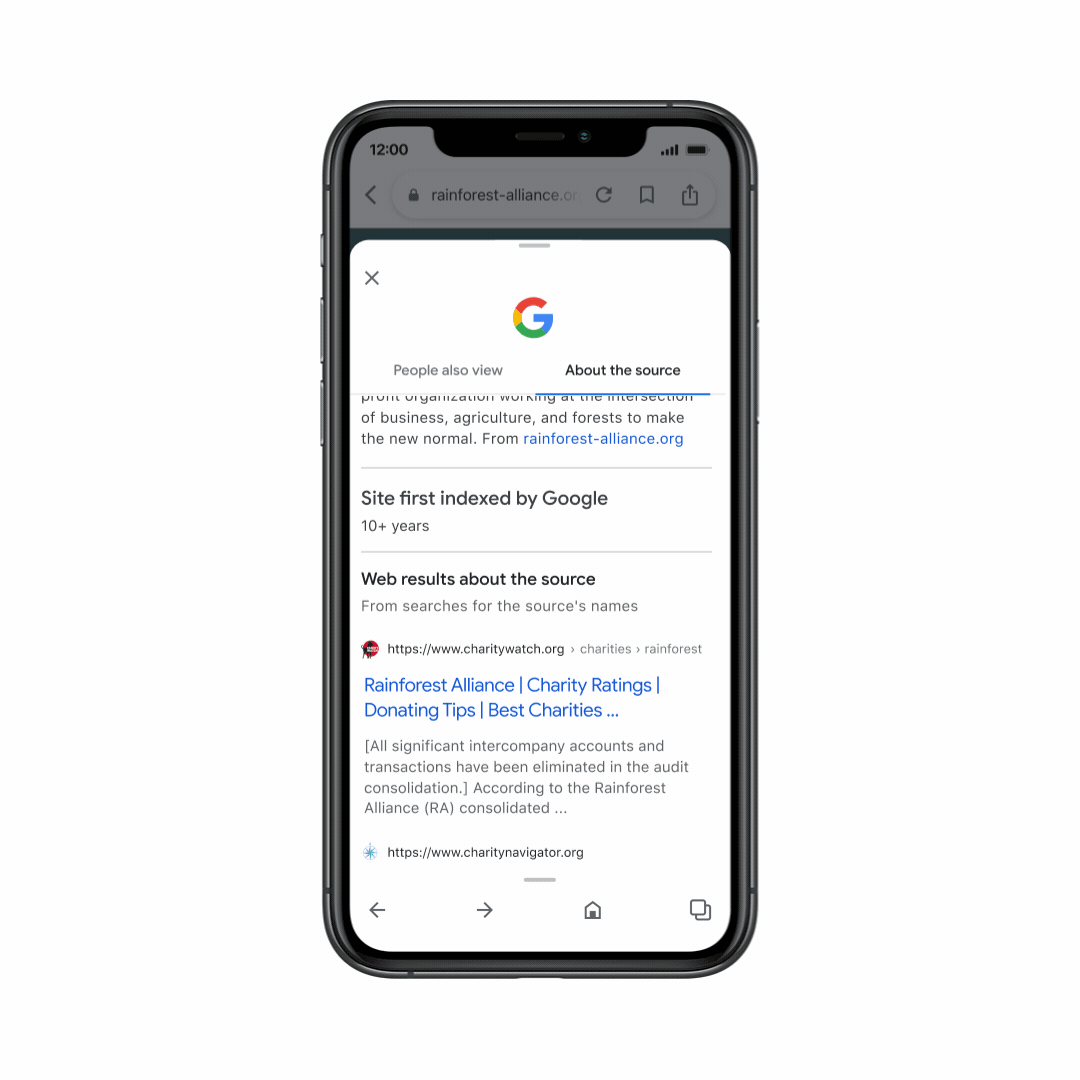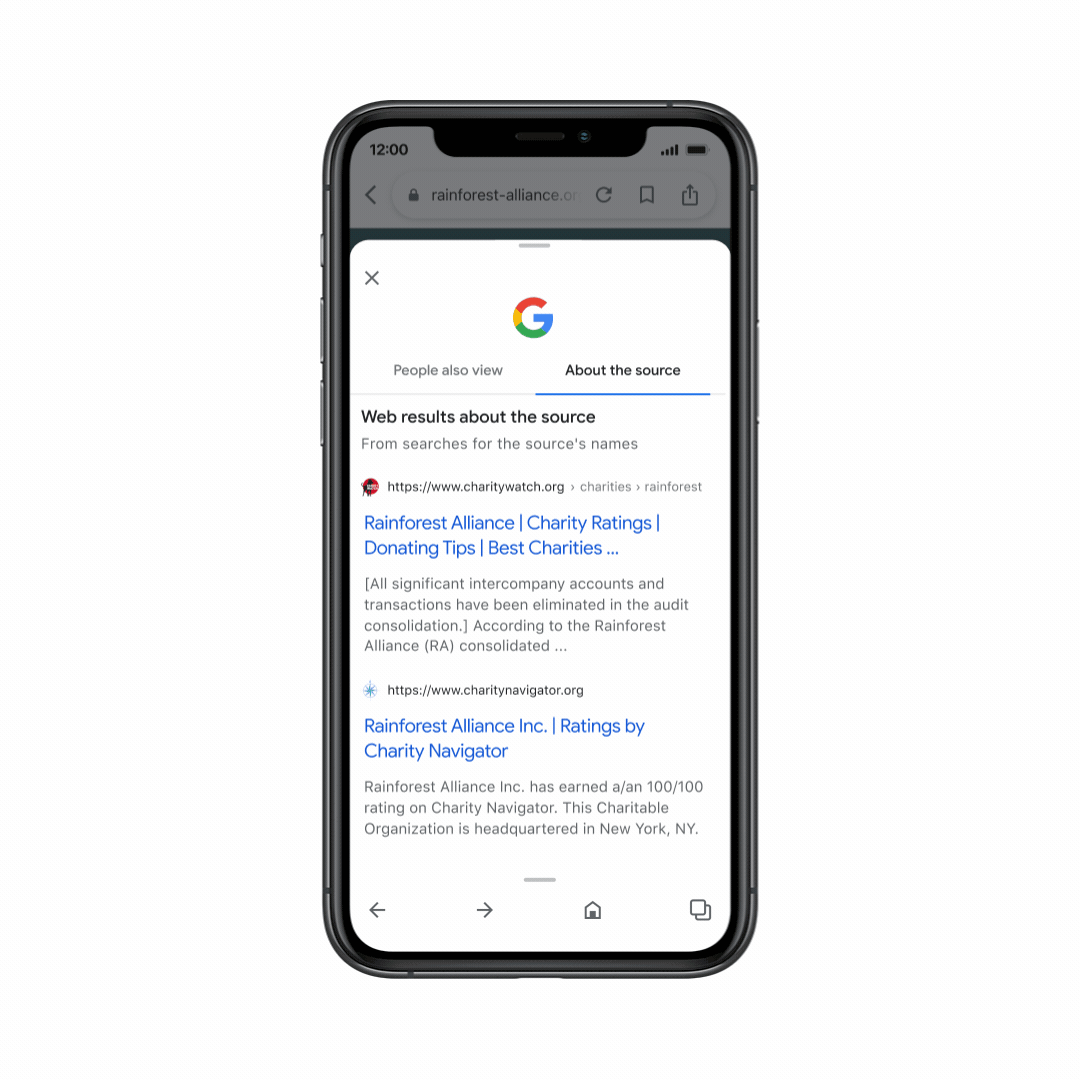
With About this page in the Google app, you can get helpful context on websites as you’re browsing.
Expanding content advisories for information gaps
Sometimes interest in a breaking news topic travels faster than facts, or there isn’t enough reliable information online about a given subject. Information literacy experts often refer to these situations as data voids. To address these, we show content advisories in situations when a topic is rapidly evolving, indicating that it might be best to check back later when more sources are available.
Now we’re expanding content advisories to searches where our systems don’t have high confidence in the overall quality of the results available for the search. This doesn’t mean that no helpful information is available, or that a particular result is low-quality. These notices provide context about the whole set of results on the page, and you can always see the results for your query, even when the advisory is present.
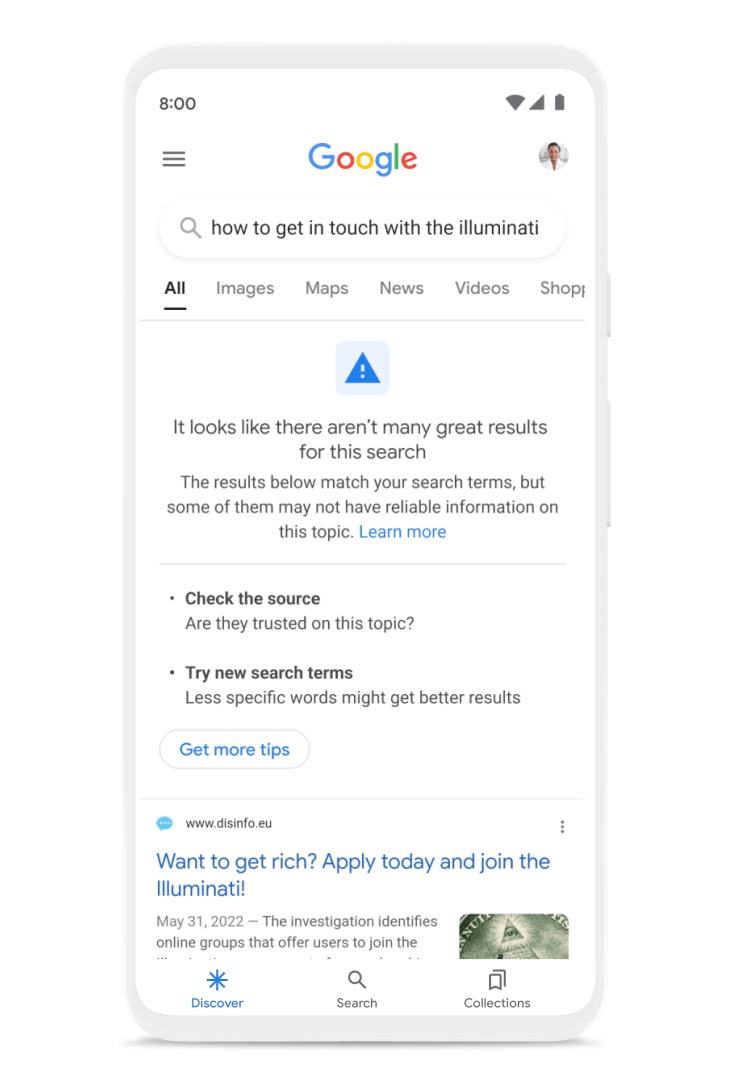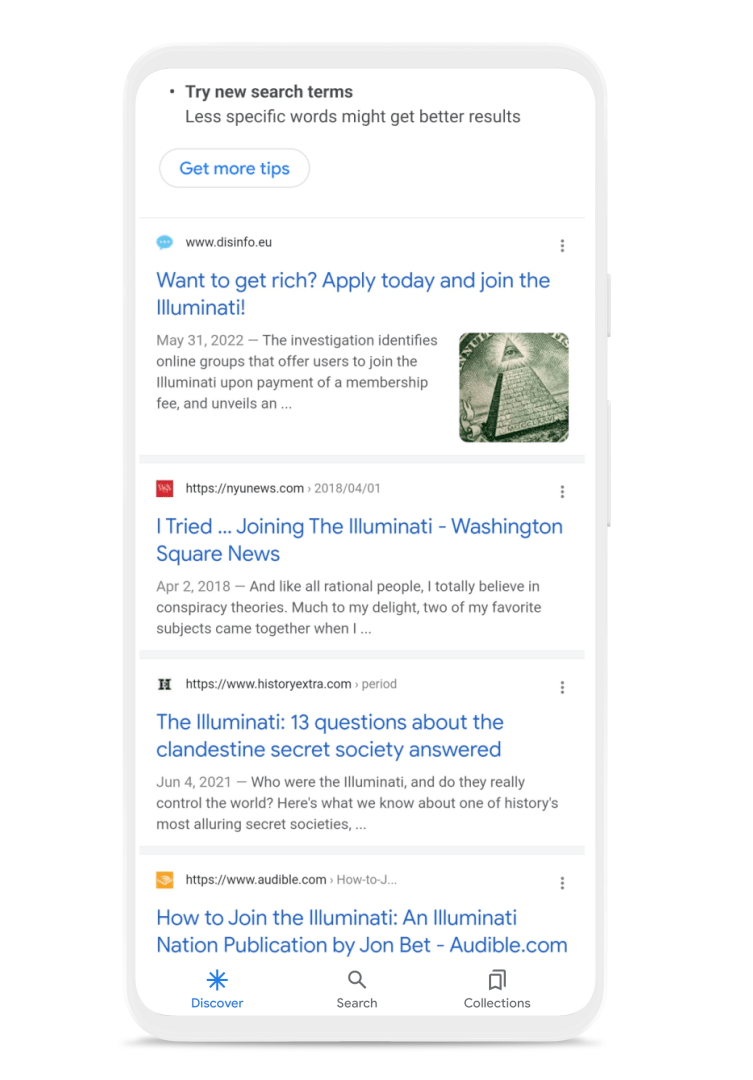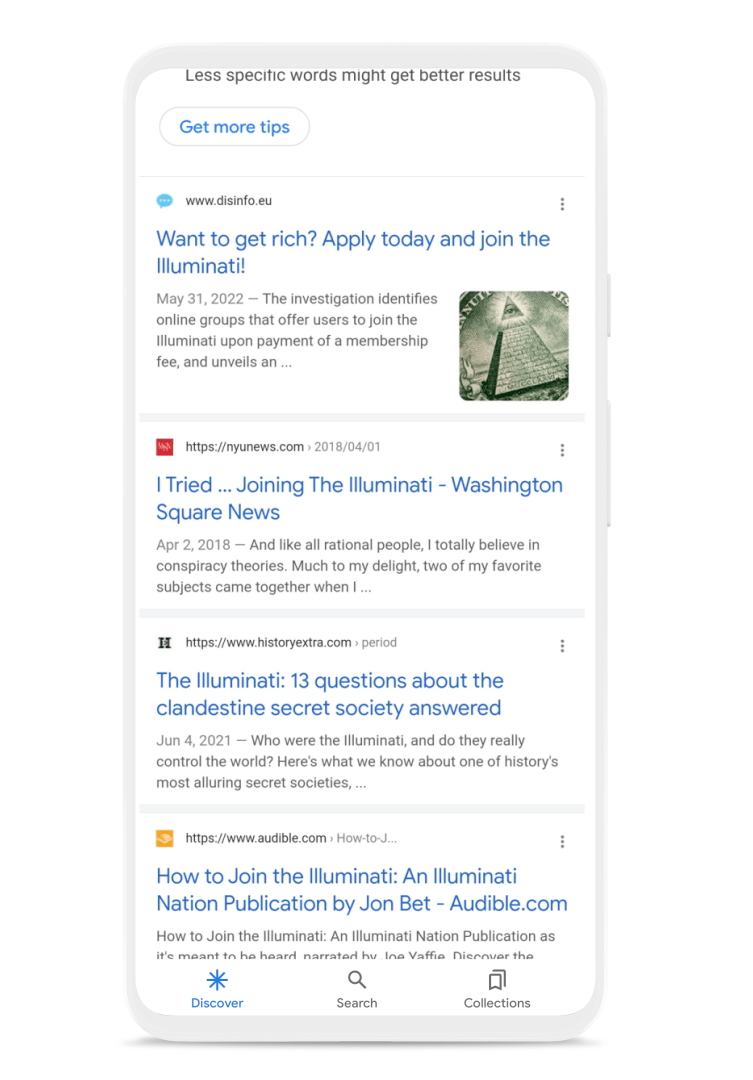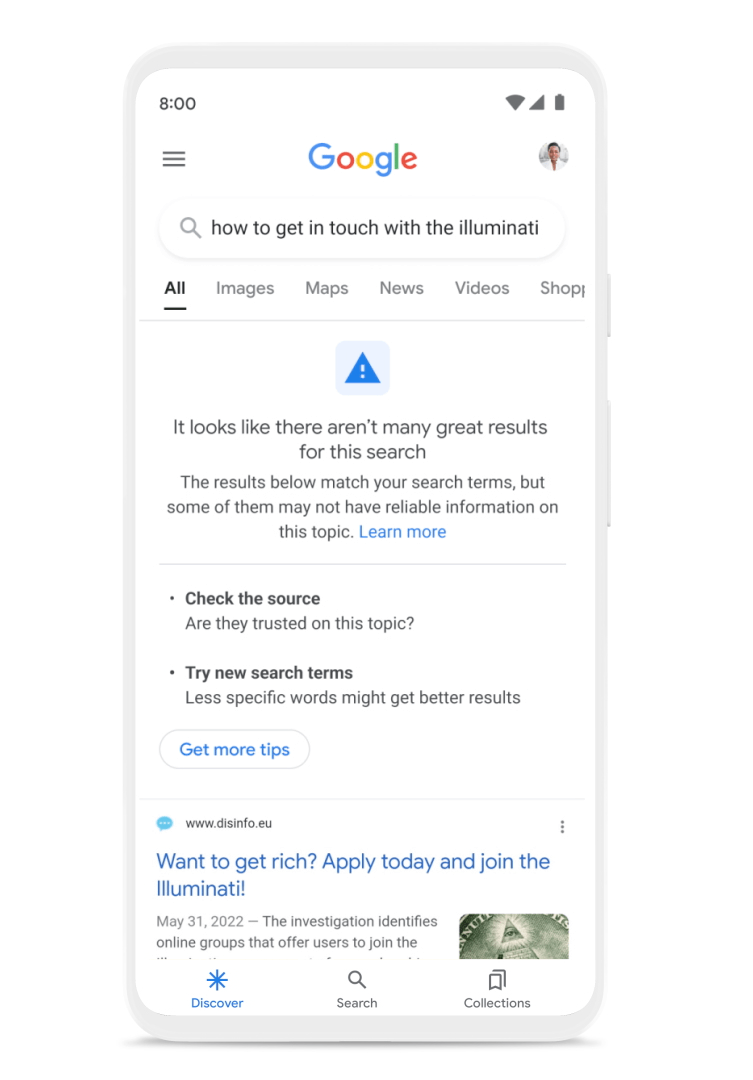
New content advisories on searches where our systems don’t have high confidence in the overall quality of the results.
Educating people about misinformation
Beyond our products, we’re making investments into programs and partnerships to help educate people about misinformation. Since 2018, the Google News Initiative (GNI) has invested nearly $75 million in projects and partnerships working to strengthen media literacy and combat misinformation around the world.
Today, we’re announcing that Google is partnering with MediaWise at the Poynter Institute for Media Studies and PBS NewsHour Student Reporting Labs to develop information literacy lesson plans for teachers of middle and high school students. It will be available for free to teachers using PBS Learning Media and for download on Poynter’s website. We’ve partnered with MediaWise since it was founded. And today’s announcement builds on the GNI’s support of its microlearning course through text and WhatsApp called Find Facts Fast.
We also announced today the results of a survey conducted by the Poynter Institute and YouGov, with support from Google, on the ways people across generational lines verify information. You can read more in our blog post.
Helping people everywhere find the information they need
Google was built on the premise that information can be a powerful thing for people around the world. We’re determined to keep doing our part to help people everywhere find what they’re looking for and give them the context they need to make informed decisions about what they see online.